Decoupled Global-Local Alignment for Improving Compositional Understanding
作者: Xiaoxing Hu, Kaicheng Yang, Jun Wang, Haoran Xu, Ziyong Feng, Yupei Wang
分类: cs.CV
发布日期: 2025-04-23 (更新: 2025-08-26)
备注: ACMMM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出解耦全局-局部对齐框架DeGLA,提升CLIP模型组合理解能力并保持通用性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 组合理解 视觉语言预训练 自蒸馏 对比学习 难负样本挖掘
📋 核心要点
- CLIP等模型在组合理解方面存在不足,难以有效处理关系和属性等复杂概念。
- DeGLA框架通过解耦全局和局部对齐,并引入自蒸馏和高质量负样本,提升组合理解能力。
- 实验表明,DeGLA在组合理解和零样本分类任务上均取得了显著提升,优于现有方法。
📝 摘要(中文)
对比语言-图像预训练(CLIP)通过对齐图像和文本模态在多个下游任务上取得了成功。然而,全局对比学习的本质限制了CLIP理解组合概念(如关系和属性)的能力。尽管最近的研究采用全局难负样本来改善组合理解,但这些方法通过强制拉远文本负样本与图像在嵌入空间中的距离,显著损害了模型固有的通用能力。为了克服这个限制,我们引入了一个解耦全局-局部对齐(DeGLA)框架,该框架在显著减轻通用能力损失的同时,提高了组合理解能力。为了优化模型固有能力的保留,我们在全局对齐过程中引入了自蒸馏机制,将可学习的图像-文本编码器与来自指数移动平均的冻结教师模型对齐。在自蒸馏的约束下,有效地减轻了微调过程中预训练知识的灾难性遗忘。为了提高组合理解能力,我们首先利用大型语言模型(LLM)的上下文学习能力,构建了跨越五种类型的大约200万个高质量负面标题。随后,我们提出了图像引导对比(IGC)损失和文本引导对比(TGC)损失,以增强视觉-语言组合性。大量的实验结果证明了DeGLA框架的有效性。与之前的最先进方法相比,DeGLA在VALSE、SugarCrepe和ARO基准测试中平均提高了3.5%。同时,它在11个数据集上的零样本分类任务中获得了平均13.0%的性能提升。我们的代码将在https://github.com/xiaoxing2001/DeGLA发布。
🔬 方法详解
问题定义:现有CLIP模型及其改进方法在组合理解方面存在局限性,难以准确识别图像中对象之间的关系和属性。直接使用全局难负样本进行训练虽然可以提升组合理解能力,但会严重损害模型在其他任务上的通用性能,导致灾难性遗忘。
核心思路:DeGLA的核心思路是将全局对齐和局部对齐解耦,分别优化。全局对齐侧重于保持模型的通用能力,通过自蒸馏避免灾难性遗忘;局部对齐则专注于提升组合理解能力,通过高质量的负样本和特定的损失函数来实现。
技术框架:DeGLA框架包含两个主要部分:全局对齐和局部对齐。全局对齐使用自蒸馏机制,将可学习的学生模型与通过指数移动平均得到的冻结教师模型对齐。局部对齐则利用大型语言模型生成的高质量负样本,并设计了图像引导对比(IGC)损失和文本引导对比(TGC)损失,以增强视觉-语言组合性。整体流程是先进行全局对齐,再进行局部对齐,从而在提升组合理解能力的同时,保持模型的通用性。
关键创新:DeGLA的关键创新在于解耦全局和局部对齐,并分别采用不同的策略进行优化。自蒸馏机制有效地缓解了微调过程中的灾难性遗忘,保证了模型的通用能力。利用大型语言模型生成高质量负样本,并设计特定的对比损失函数,显著提升了模型的组合理解能力。
关键设计:自蒸馏过程中,教师模型通过指数移动平均更新,平滑了模型参数的更新过程,有助于稳定训练。IGC损失和TGC损失分别从图像和文本的角度出发,引导模型学习图像区域与文本描述之间的对应关系。具体而言,IGC损失鼓励模型将图像区域与对应的文本描述对齐,同时远离不相关的文本描述;TGC损失则鼓励模型将文本描述与对应的图像区域对齐,同时远离不相关的图像区域。
🖼️ 关键图片

📊 实验亮点
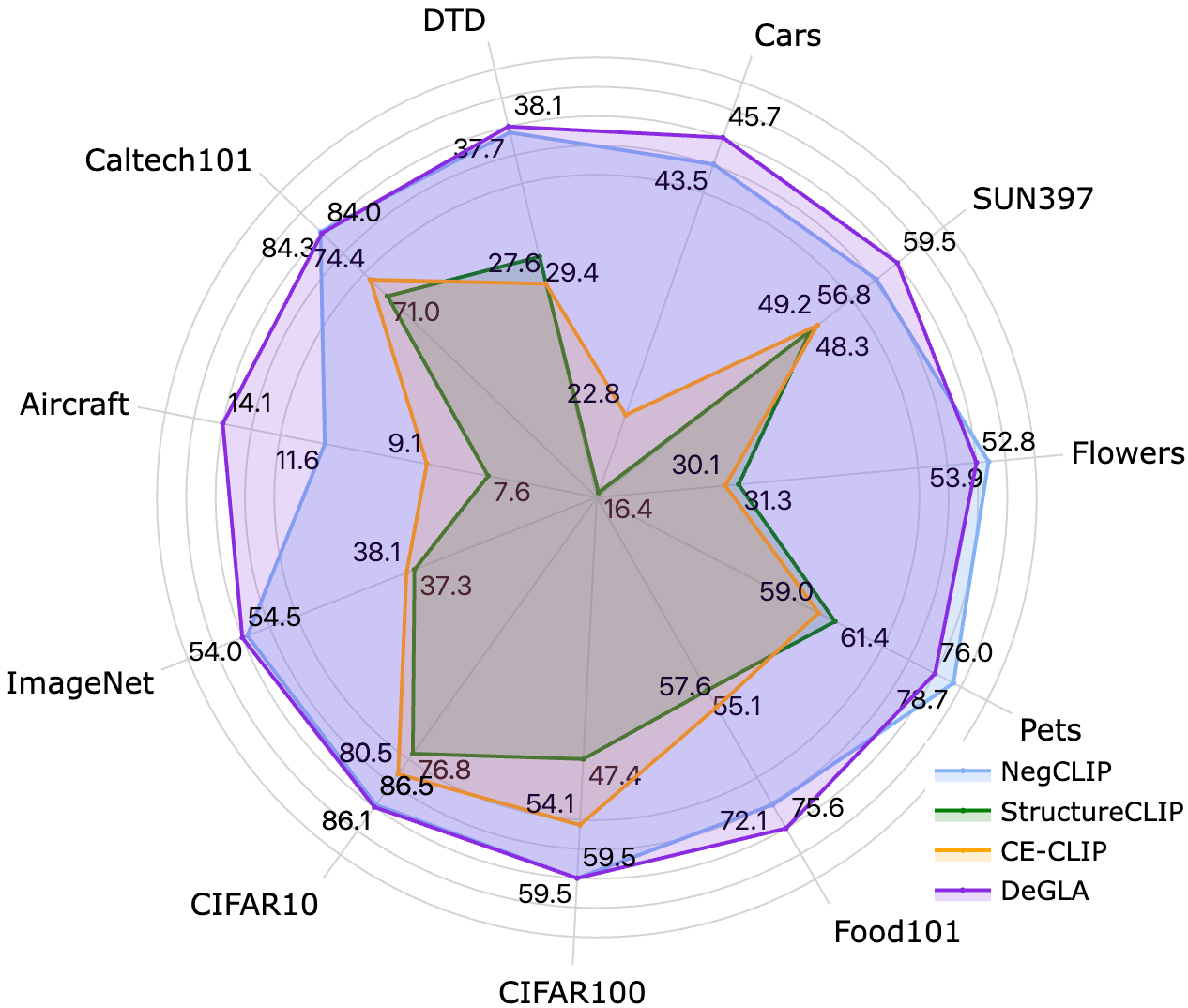
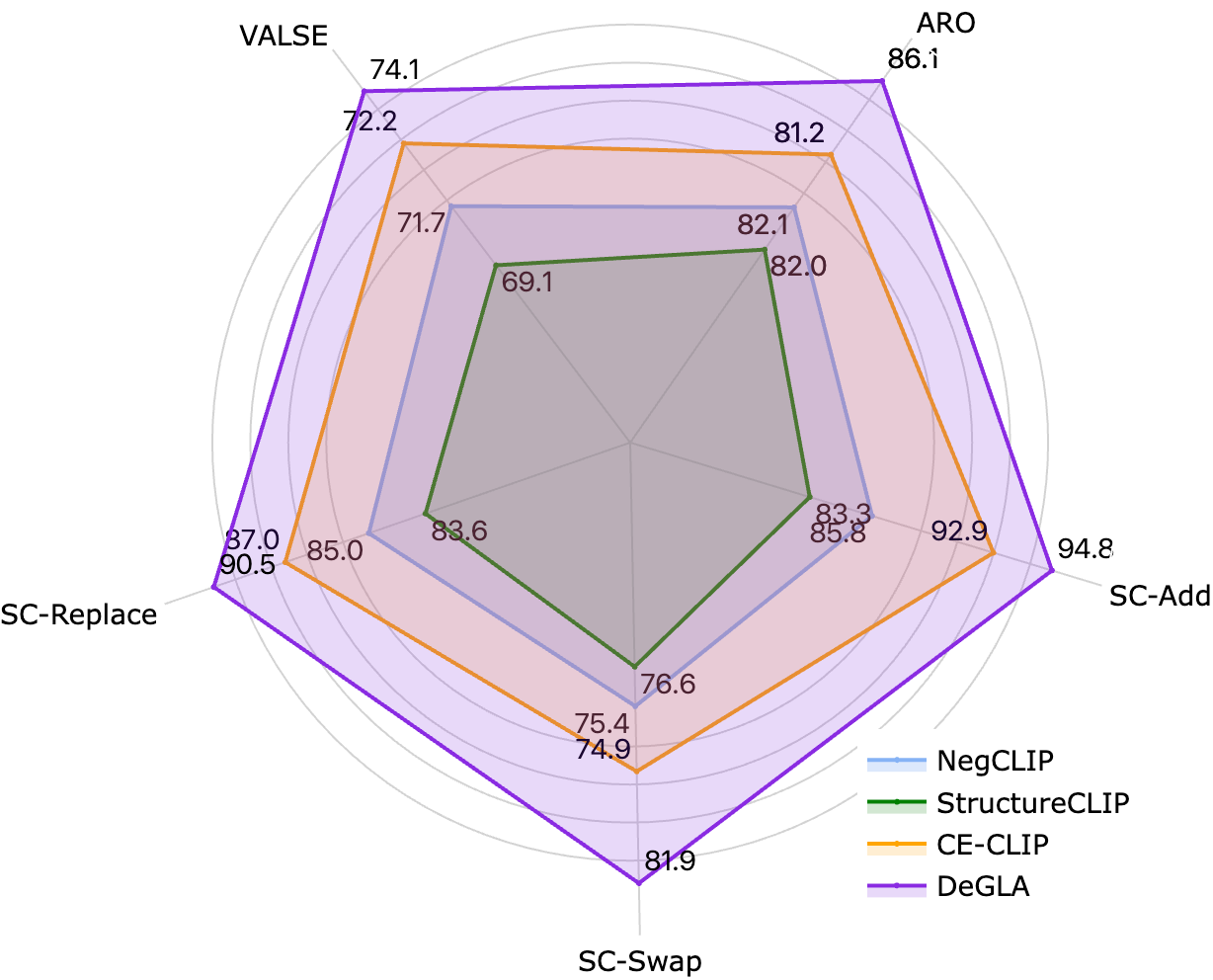
DeGLA框架在VALSE、SugarCrepe和ARO等组合理解基准测试中,相比现有方法平均提升了3.5%。同时,在11个数据集上的零样本分类任务中,DeGLA取得了平均13.0%的性能提升,表明该方法在提升组合理解能力的同时,有效保持了模型的通用性。
🎯 应用场景
该研究成果可应用于图像检索、视觉问答、图像描述生成等领域。通过提升模型对图像中对象关系和属性的理解能力,可以提高这些应用在复杂场景下的性能。例如,在图像检索中,可以更准确地根据用户输入的复杂查询条件检索到相关的图像。
📄 摘要(原文)
Contrastive Language-Image Pre-training (CLIP) has achieved success on multiple downstream tasks by aligning image and text modalities. However, the nature of global contrastive learning limits CLIP's ability to comprehend compositional concepts, such as relations and attributes. Although recent studies employ global hard negative samples to improve compositional understanding, these methods significantly compromise the model's inherent general capabilities by forcibly distancing textual negative samples from images in the embedding space. To overcome this limitation, we introduce a Decoupled Global-Local Alignment (DeGLA) framework that improves compositional understanding while substantially mitigating losses in general capabilities. To optimize the retention of the model's inherent capabilities, we incorporate a self-distillation mechanism within the global alignment process, aligning the learnable image-text encoder with a frozen teacher model derived from an exponential moving average. Under the constraint of self-distillation, it effectively mitigates the catastrophic forgetting of pretrained knowledge during fine-tuning. To improve compositional understanding, we first leverage the in-context learning capability of Large Language Models (LLMs) to construct about 2M high-quality negative captions across five types. Subsequently, we propose the Image-Grounded Contrast (IGC) loss and Text-Grounded Contrast (TGC) loss to enhance vision-language compositionally. Extensive experimental results demonstrate the effectiveness of the DeGLA framework. Compared to previous state-of-the-art methods, DeGLA achieves an average enhancement of 3.5% across the VALSE, SugarCrepe, and ARO benchmarks. Concurrently, it obtains an average performance improvement of 13.0% on zero-shot classification tasks across eleven datasets. Our code will be released at https://github.com/xiaoxing2001/DeGLA