Federated EndoViT: Pretraining Vision Transformers via Federated Learning on Endoscopic Image Collections
作者: Max Kirchner, Alexander C. Jenke, Sebastian Bodenstedt, Fiona R. Kolbinger, Oliver L. Saldanha, Jakob N. Kather, Martin Wagner, Stefanie Speidel
分类: cs.CV, cs.LG
发布日期: 2025-04-23 (更新: 2025-05-08)
备注: Preprint submitted to IEEE TMI
💡 一句话要点
提出基于联邦学习的内窥镜Vision Transformer预训练方法,解决数据共享限制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 内窥镜图像 Vision Transformer 预训练 自适应锐度感知最小化 掩码自编码器 医疗影像分析
📋 核心要点
- 现有方法难以在保护隐私的前提下,利用多中心内窥镜数据训练通用的视觉模型。
- 提出FL-EndoViT,一种基于联邦学习的Vision Transformer预训练方法,结合FedSAM和SWA。
- 实验表明,FL-EndoViT在多个下游任务中表现与集中式训练模型相当甚至更好。
📝 摘要(中文)
本研究旨在利用联邦学习训练基础模型,解决微创手术中数据共享的限制,实现无需数据传输的协同模型训练。受EndoViT研究的启发,我们改进了用于联邦学习的掩码自编码器(MAE),并增强了自适应锐度感知最小化(FedSAM)和随机权重平均(SWA)。我们的模型在Endo700k数据集上进行预训练,并在语义分割、动作三元组识别和手术阶段识别等任务上进行微调和评估。结果表明,将自适应FedSAM集成到联邦MAE方法中可以改善预训练,从而降低每个patch的重建损失。FL-EndoViT在手术下游任务中的表现与CEN-EndoViT相当。此外,在数据有限的手术场景分割以及使用大型数据集的动作三元组识别中,FL-EndoViT优于CEN-EndoViT。这些发现突出了联邦学习在保护隐私的手术基础模型训练中的潜力,为手术数据科学提供了一个鲁棒且通用的解决方案。有效的协作需要调整联邦学习方法,例如集成FedSAM,以适应各机构之间固有的数据异质性。未来,探索基于视频模型的FL可以通过结合对真实手术环境至关重要的时空动态来增强这些能力。
🔬 方法详解
问题定义:论文旨在解决内窥镜图像数据在不同医疗机构之间共享困难的问题。由于隐私保护和数据安全等因素,直接将数据集中起来进行模型训练是不现实的。现有的集中式训练方法无法充分利用分散在各个机构的大量数据,限制了模型的泛化能力和性能。
核心思路:论文的核心思路是利用联邦学习,在不共享原始数据的前提下,让各个医疗机构协同训练一个全局模型。通过在本地训练模型并将模型参数更新上传到中央服务器进行聚合,从而实现知识共享和模型优化。同时,引入自适应锐度感知最小化(FedSAM)来提高模型的泛化能力和鲁棒性。
技术框架:整体框架包括以下几个主要步骤:1) 各个医疗机构在本地使用内窥镜图像数据训练Masked Autoencoder (MAE) 模型。2) 在本地训练过程中,使用FedSAM优化器来提高模型的泛化能力。3) 各个机构将模型参数更新上传到中央服务器。4) 中央服务器使用随机权重平均(SWA)算法对各个机构上传的参数进行聚合,得到全局模型。5) 将全局模型分发给各个机构,进行下一轮的本地训练。
关键创新:论文的关键创新在于将自适应锐度感知最小化(FedSAM)集成到联邦学习框架中。FedSAM能够帮助模型找到更平坦的损失函数最小值,从而提高模型的泛化能力和鲁棒性,尤其是在数据异质性较强的联邦学习场景下。此外,使用SWA进行模型聚合也有助于提高模型的性能。
关键设计:论文中关键的设计包括:1) 使用Masked Autoencoder (MAE) 作为预训练模型,学习内窥镜图像的通用特征表示。2) 使用FedSAM优化器,其自适应地调整锐度感知最小化的强度,以适应不同机构的数据分布。3) 使用随机权重平均(SWA)算法进行模型聚合,能够有效地融合各个机构的模型参数,提高全局模型的性能。4) 在Endo700k数据集上进行预训练,并在语义分割、动作三元组识别和手术阶段识别等下游任务上进行微调和评估。
🖼️ 关键图片


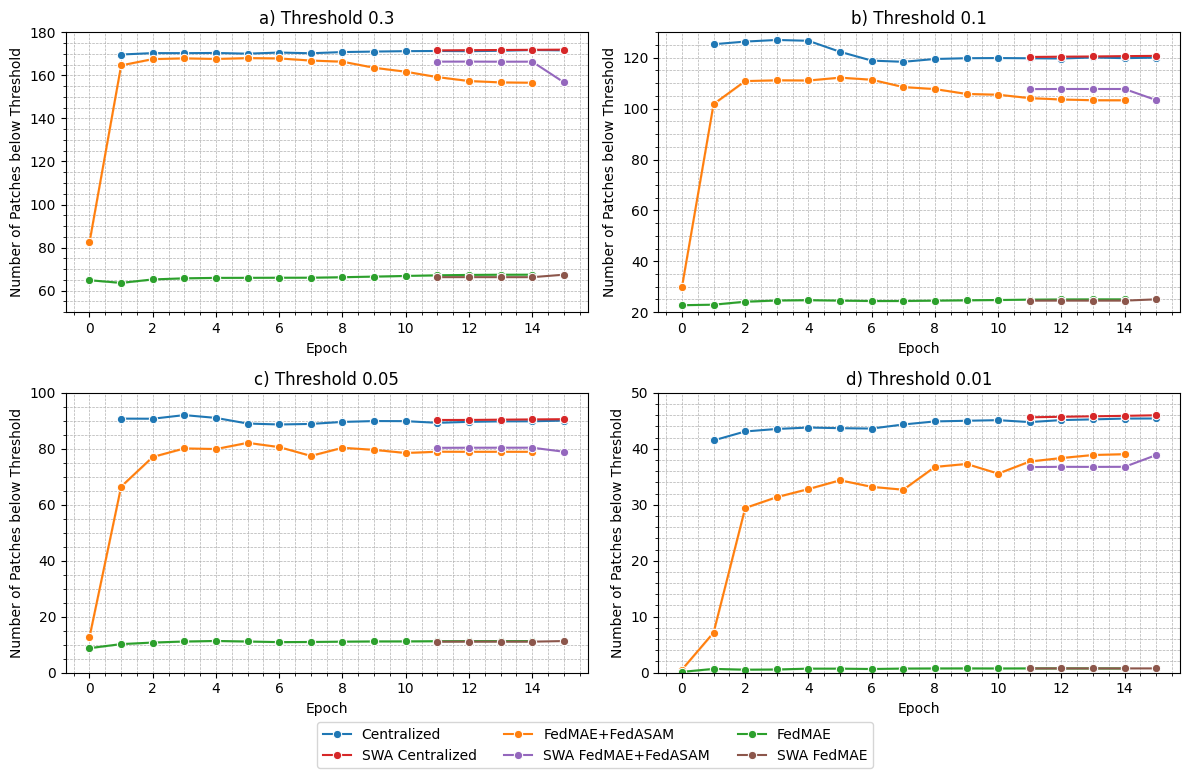
📊 实验亮点
实验结果表明,集成了自适应FedSAM的FL-EndoViT在预训练阶段降低了每个patch的重建损失。在下游任务中,FL-EndoViT在数据有限的手术场景分割任务以及使用大型数据集的动作三元组识别任务中,表现优于集中式训练的CEN-EndoViT,证明了联邦学习在保护隐私的同时,能够有效利用多中心数据提升模型性能。
🎯 应用场景
该研究成果可应用于医疗影像分析、手术机器人辅助、智能诊断等领域。通过联邦学习,可以安全地利用多中心数据训练高性能的AI模型,提升医疗服务的质量和效率。未来,该方法有望推广到其他医疗领域,例如病理图像分析、基因组学研究等。
📄 摘要(原文)
Purpose: In this study, we investigate the training of foundation models using federated learning to address data-sharing limitations and enable collaborative model training without data transfer for minimally invasive surgery. Methods: Inspired by the EndoViT study, we adapt the Masked Autoencoder for federated learning, enhancing it with adaptive Sharpness-Aware Minimization (FedSAM) and Stochastic Weight Averaging (SWA). Our model is pretrained on the Endo700k dataset collection and later fine-tuned and evaluated for tasks such as Semantic Segmentation, Action Triplet Recognition, and Surgical Phase Recognition. Results: Our findings demonstrate that integrating adaptive FedSAM into the federated MAE approach improves pretraining, leading to a reduction in reconstruction loss per patch. The application of FL-EndoViT in surgical downstream tasks results in performance comparable to CEN-EndoViT. Furthermore, FL-EndoViT exhibits advantages over CEN-EndoViT in surgical scene segmentation when data is limited and in action triplet recognition when large datasets are used. Conclusion: These findings highlight the potential of federated learning for privacy-preserving training of surgical foundation models, offering a robust and generalizable solution for surgical data science. Effective collaboration requires adapting federated learning methods, such as the integration of FedSAM, which can accommodate the inherent data heterogeneity across institutions. In future, exploring FL in video-based models may enhance these capabilities by incorporating spatiotemporal dynamics crucial for real-world surgical environments.