Direct Video-Based Spatiotemporal Deep Learning for Cattle Lameness Detection
作者: Md Fahimuzzman Sohan, Raid Alzubi, Hadeel Alzoubi, Eid Albalawi, A. H. Abdul Hafez
分类: cs.CV, cs.AI, cs.LG, eess.IV
发布日期: 2025-04-23 (更新: 2025-09-18)
💡 一句话要点
提出基于视频时空深度学习的牛跛足检测方法,无需姿态估计预处理。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 牛跛足检测 时空深度学习 3D CNN ConvLSTM2D 视频分类 智能畜牧业
📋 核心要点
- 传统牛跛足检测依赖人工观察或复杂的多阶段流水线,效率低且成本高昂。
- 提出一种基于时空深度学习的端到端方法,直接从视频中学习跛足特征,无需人工特征工程。
- 实验表明,3D CNN模型在牛跛足检测任务上取得了90%的准确率,优于其他模型。
📝 摘要(中文)
牛跛足是畜牧业中常见的健康问题,通常由蹄部损伤或感染引起,严重影响动物福利和生产力。早期准确的检测对于最大限度地减少经济损失和确保适当的治疗至关重要。本研究提出了一个时空深度学习框架,用于使用公开的视频数据自动检测牛跛足。我们整理并公开发布了一个平衡的数据集,包含50个在线视频片段,其中包含42头牛,从室内和室外环境中的多个视点记录。这些视频根据视觉步态特征和元数据描述被分为跛足和非跛足类别。在应用数据增强技术以增强泛化能力后,训练并评估了两种深度学习架构:3D卷积神经网络(3D CNN)和卷积长短期记忆网络(ConvLSTM2D)。3D CNN实现了90%的视频级分类准确率,精确率、召回率和F1分数均为90.9%,优于ConvLSTM2D模型,后者的准确率为85%。与依赖于包含对象检测和姿态估计的多阶段流水线的传统方法不同,本研究证明了直接端到端视频分类方法的有效性。与最佳的端到端先前方法(C3D-ConvLSTM,90.3%)相比,我们的模型实现了相当的准确性,同时消除了姿态估计预处理。结果表明,深度学习模型可以成功地从各种视频源中提取和学习时空特征,从而在实际农场环境中实现可扩展且高效的牛跛足检测。
🔬 方法详解
问题定义:本研究旨在解决牛跛足的自动检测问题。现有方法通常依赖人工观察,主观性强且效率低下。一些基于计算机视觉的方法需要复杂的多阶段流水线,例如对象检测和姿态估计,计算成本高昂且容易出错。这些方法难以适应实际农场环境中的各种视角和光照条件。
核心思路:本研究的核心思路是利用深度学习模型直接从视频数据中学习牛跛足的时空特征。通过训练3D CNN和ConvLSTM2D等模型,可以自动提取视频中的运动模式和外观特征,从而实现端到端的跛足检测。这种方法避免了人工特征工程和复杂的预处理步骤,提高了检测效率和鲁棒性。
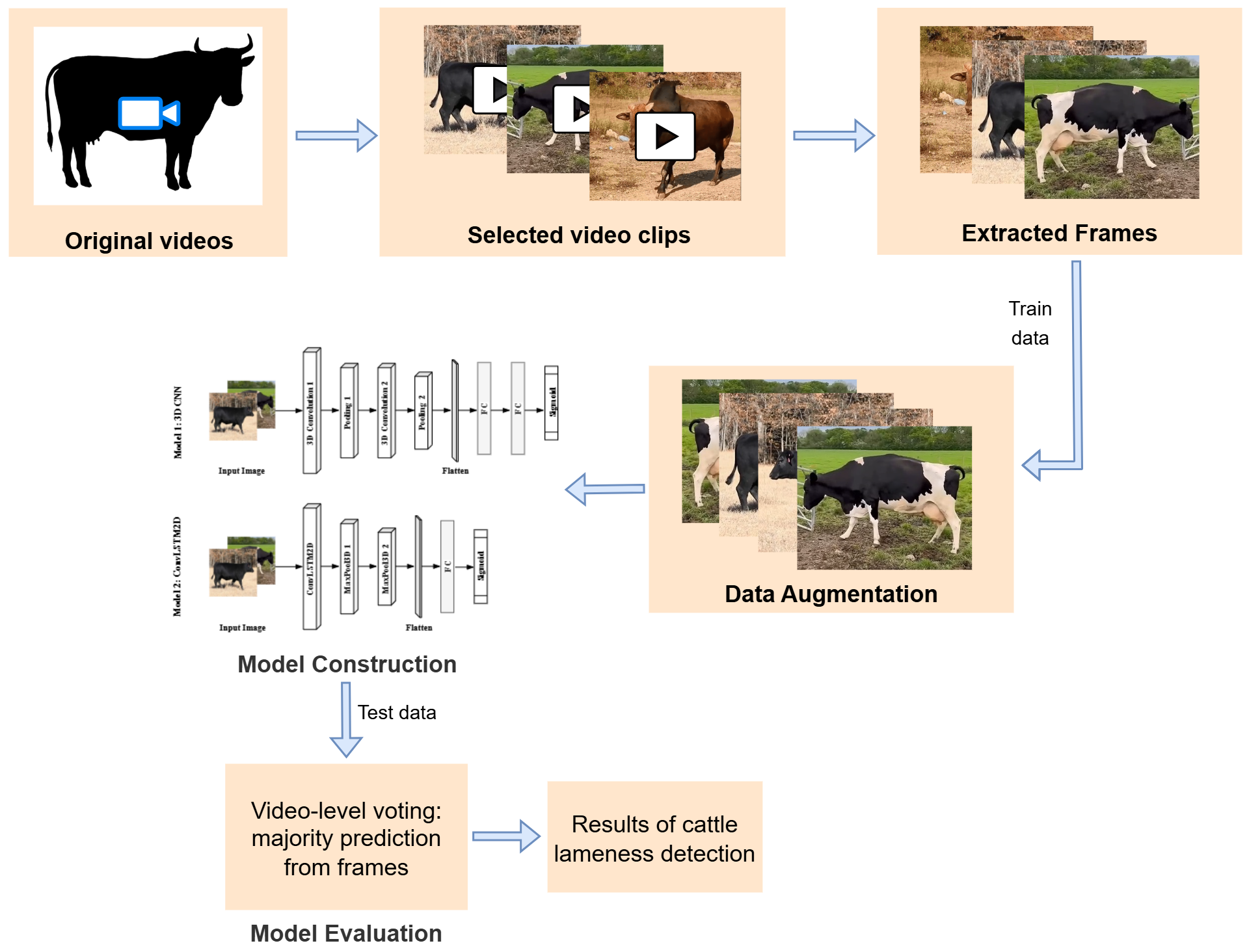
技术框架:整体框架包括数据收集与标注、数据增强、模型训练与评估三个主要阶段。首先,收集包含跛足和非跛足牛的视频数据,并进行标注。然后,应用数据增强技术,例如旋转、缩放和裁剪,以增加数据的多样性并提高模型的泛化能力。最后,训练3D CNN和ConvLSTM2D模型,并使用准确率、精确率、召回率和F1分数等指标评估模型的性能。
关键创新:本研究的关键创新在于提出了一种直接端到端的视频分类方法,无需姿态估计等预处理步骤。与传统的基于姿态估计的方法相比,该方法更加简洁高效,并且能够更好地适应实际农场环境中的各种视角和光照条件。此外,该研究还公开了一个包含50个视频片段的牛跛足数据集,为后续研究提供了便利。
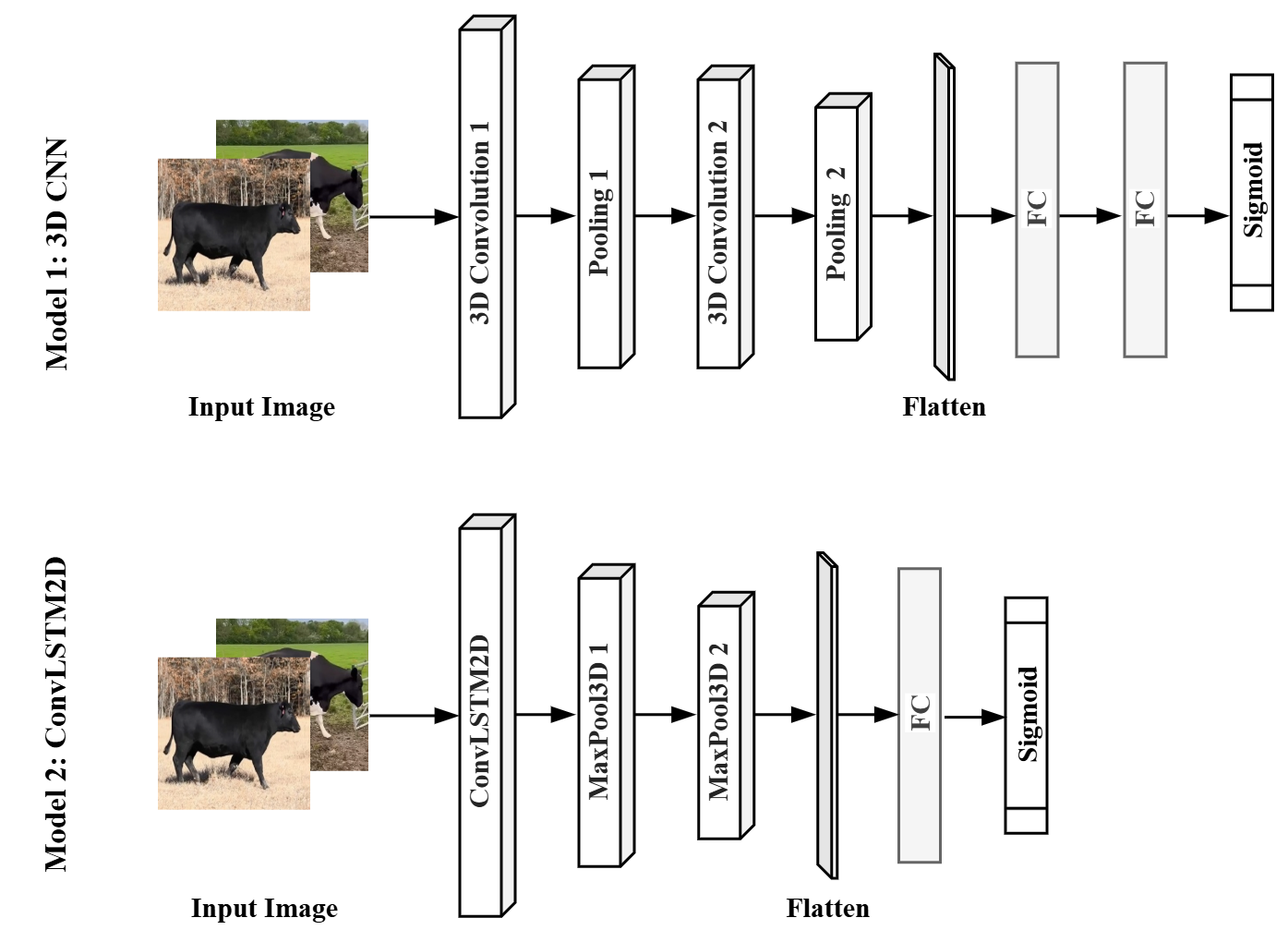
关键设计:3D CNN模型采用多个3D卷积层和池化层来提取视频中的时空特征。ConvLSTM2D模型则结合了卷积层和LSTM层,能够更好地捕捉视频中的时间依赖关系。在训练过程中,使用交叉熵损失函数来优化模型参数。数据增强技术包括随机旋转、缩放、裁剪和颜色抖动等。模型超参数通过交叉验证进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,3D CNN模型在牛跛足检测任务上取得了90%的视频级分类准确率,精确率、召回率和F1分数均为90.9%。该模型优于ConvLSTM2D模型(85%准确率),并且与现有的最佳端到端方法(C3D-ConvLSTM,90.3%)相比,在准确率相当的情况下,无需姿态估计预处理。
🎯 应用场景
该研究成果可应用于智能畜牧业,实现对牛群健康状况的实时监控和预警。通过在农场安装摄像头,并部署训练好的深度学习模型,可以自动检测跛足牛,及时采取治疗措施,减少经济损失,提高动物福利。该技术还可扩展到其他动物疾病的检测,具有广阔的应用前景。
📄 摘要(原文)
Cattle lameness is a prevalent health problem in livestock farming, often resulting from hoof injuries or infections, and severely impacts animal welfare and productivity. Early and accurate detection is critical for minimizing economic losses and ensuring proper treatment. This study proposes a spatiotemporal deep learning framework for automated cattle lameness detection using publicly available video data. We curate and publicly release a balanced set of 50 online video clips featuring 42 individual cattle, recorded from multiple viewpoints in both indoor and outdoor environments. The videos were categorized into lame and non-lame classes based on visual gait characteristics and metadata descriptions. After applying data augmentation techniques to enhance generalization, two deep learning architectures were trained and evaluated: 3D Convolutional Neural Networks (3D CNN) and Convolutional Long-Short-Term Memory (ConvLSTM2D). The 3D CNN achieved a video-level classification accuracy of 90%, with a precision, recall, and F1 score of 90.9% each, outperforming the ConvLSTM2D model, which achieved 85% accuracy. Unlike conventional approaches that rely on multistage pipelines involving object detection and pose estimation, this study demonstrates the effectiveness of a direct end-to-end video classification approach. Compared with the best end-to-end prior method (C3D-ConvLSTM, 90.3%), our model achieves comparable accuracy while eliminating pose estimation pre-processing.The results indicate that deep learning models can successfully extract and learn spatio-temporal features from various video sources, enabling scalable and efficient cattle lameness detection in real-world farm settings.