Revisiting Radar Camera Alignment by Contrastive Learning for 3D Object Detection
作者: Linhua Kong, Dongxia Chang, Lian Liu, Zisen Kong, Pengyuan Li, Yao Zhao
分类: cs.CV
发布日期: 2025-04-23
💡 一句话要点
提出RCAlign模型,通过对比学习实现雷达相机特征对齐,提升3D目标检测精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 雷达相机融合 3D目标检测 对比学习 特征对齐 知识蒸馏 自动驾驶 多模态学习
📋 核心要点
- 现有雷达相机融合的3D目标检测方法在特征对齐方面存在不足,忽略模态间交互或无法有效对齐同位置特征。
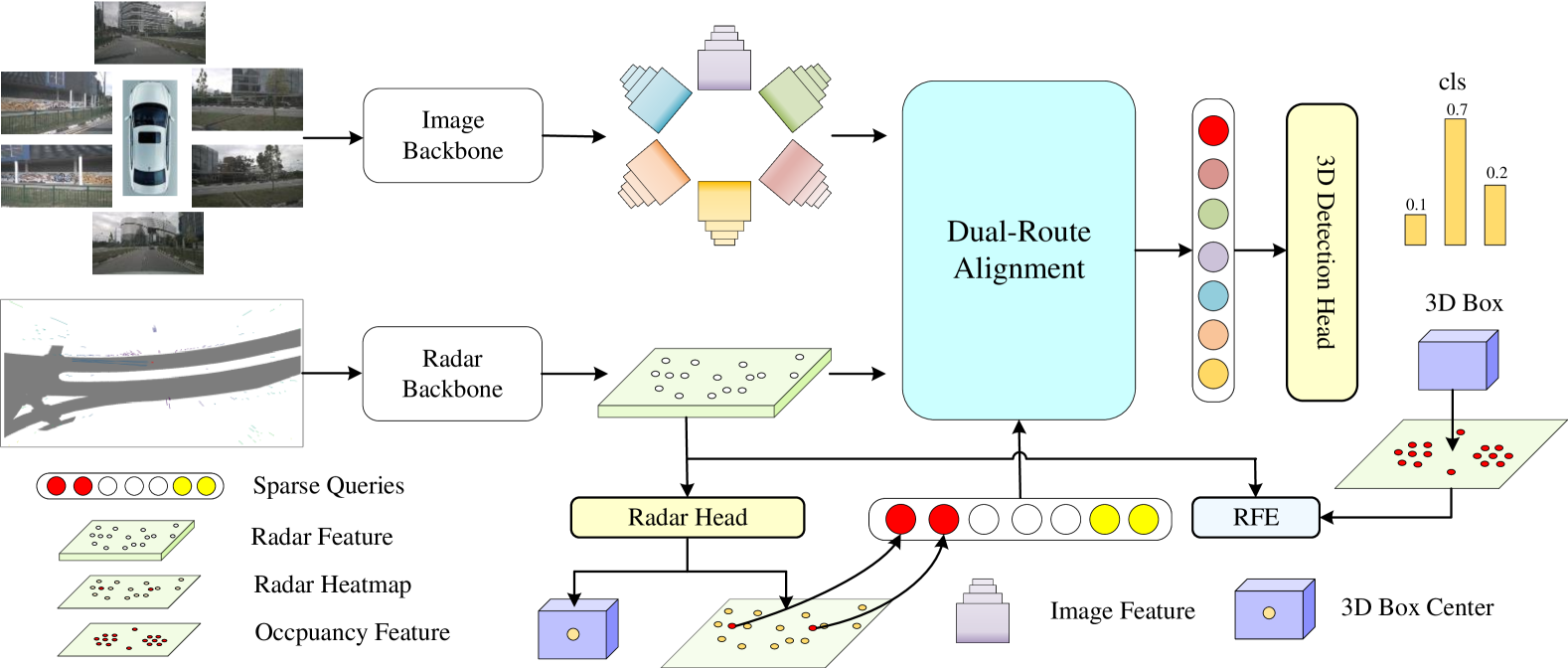
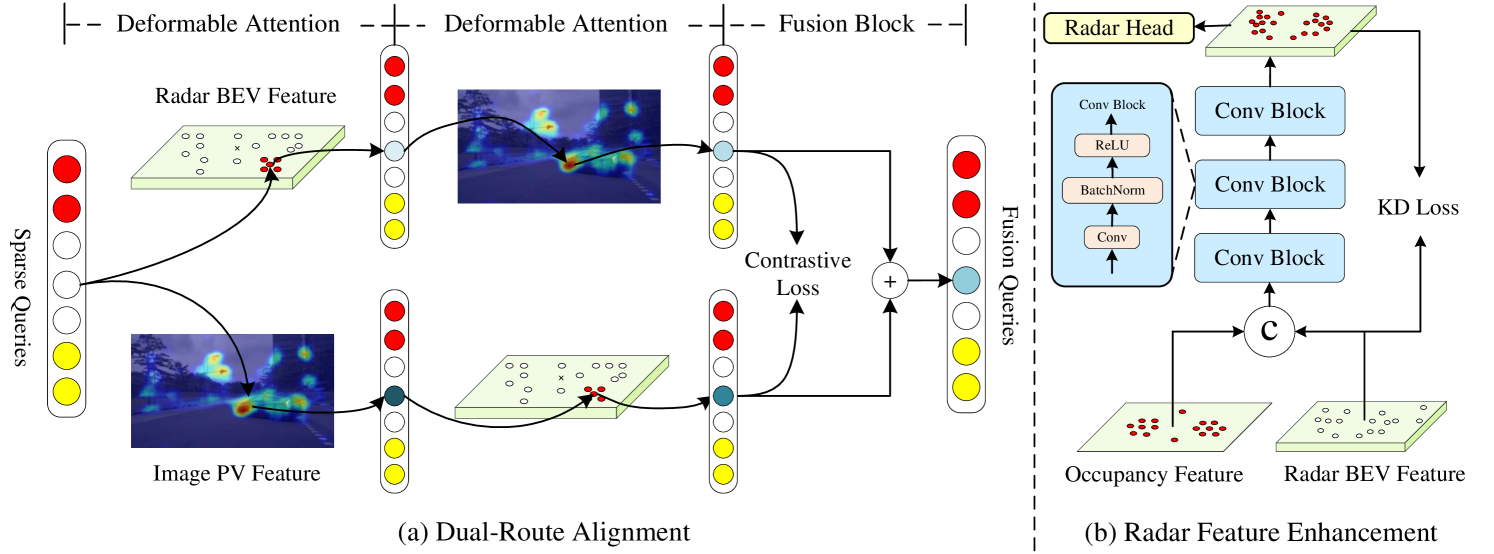
- RCAlign模型通过对比学习的双路对齐模块(DRA)对齐和融合雷达与相机特征,并使用雷达特征增强模块(RFE)提高雷达特征密度。
- 实验表明,RCAlign在nuScenes数据集上达到SOTA,并在实时3D检测中显著优于RCBEVDet,NDS提升4.3%,mAP提升8.4%。
📝 摘要(中文)
本文提出了一种新的雷达相机对齐模型(RCAlign),旨在解决雷达和相机融合的3D目标检测中,模态间特征未对齐的问题。现有方法要么忽略了模态间特征的交互,要么未能有效对齐空间位置相同的特征。RCAlign设计了一个基于对比学习的双路对齐(DRA)模块,用于对齐和融合雷达与相机的特征。此外,考虑到雷达BEV特征的稀疏性,提出了雷达特征增强(RFE)模块,通过知识蒸馏损失来提高雷达BEV特征的稠密程度。实验结果表明,RCAlign在nuScenes数据集上实现了雷达相机融合3D目标检测的新SOTA。与最新的SOTA方法(RCBEVDet)相比,在实时3D检测中,RCAlign取得了显著的性能提升(NDS提升4.3%,mAP提升8.4%)。
🔬 方法详解
问题定义:现有雷达相机融合的3D目标检测方法,在处理雷达和相机数据之间的模态差异时,往往忽略了模态间特征的充分交互,或者无法有效地对齐来自不同模态但在同一空间位置的特征。这导致融合后的特征表示不够准确,从而限制了3D目标检测的性能。现有方法的痛点在于缺乏有效的跨模态特征对齐和增强机制。
核心思路:RCAlign的核心思路是利用对比学习来显式地对齐雷达和相机特征,并使用知识蒸馏来增强雷达特征的表示能力。通过对比学习,模型能够学习到雷达和相机特征之间的相似性和差异性,从而更好地对齐它们。同时,通过知识蒸馏,可以将相机特征的丰富信息迁移到雷达特征上,提高雷达特征的稠密性和表达能力。
技术框架:RCAlign的整体框架包含两个主要模块:双路对齐(DRA)模块和雷达特征增强(RFE)模块。首先,雷达和相机数据分别经过各自的特征提取网络。然后,DRA模块利用对比学习对齐雷达和相机特征,并进行融合。接下来,RFE模块利用知识蒸馏增强雷达BEV特征。最后,融合后的特征被送入3D目标检测头进行预测。
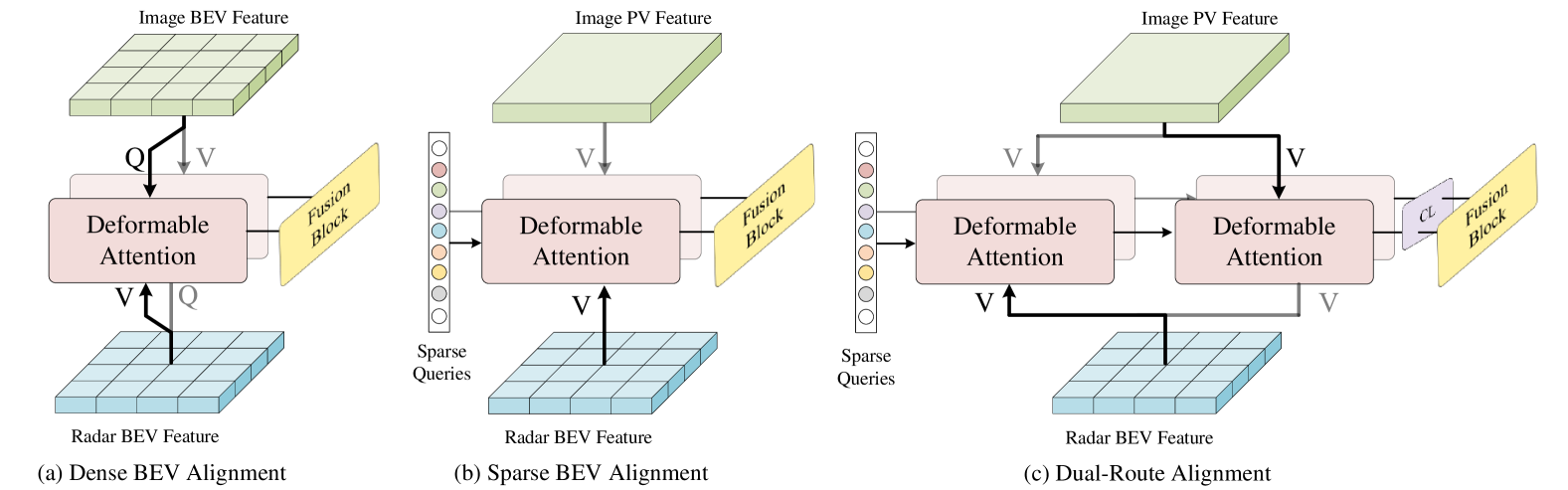
关键创新:RCAlign的关键创新在于DRA模块和RFE模块的设计。DRA模块通过对比学习显式地对齐雷达和相机特征,这与以往隐式地学习特征对齐的方法不同。RFE模块利用知识蒸馏增强雷达特征,解决了雷达数据稀疏性的问题。这两个模块的结合,使得RCAlign能够更有效地利用雷达和相机数据进行3D目标检测。
关键设计:DRA模块使用InfoNCE损失作为对比学习的损失函数,鼓励来自同一3D位置的雷达和相机特征更加相似,而来自不同位置的特征更加不同。RFE模块使用L1损失作为知识蒸馏的损失函数,促使雷达BEV特征学习相机BEV特征的分布。网络结构方面,DRA模块包含两个并行的分支,分别处理雷达和相机特征,并通过交叉注意力机制进行特征交互。RFE模块使用一个轻量级的卷积神经网络作为雷达特征增强器。
🖼️ 关键图片
📊 实验亮点
RCAlign在nuScenes数据集上取得了显著的性能提升,证明了其有效性。具体而言,与最新的SOTA方法RCBEVDet相比,RCAlign在实时3D检测中,NDS指标提升了4.3%,mAP指标提升了8.4%。这些结果表明,RCAlign在雷达相机融合的3D目标检测方面具有显著的优势。
🎯 应用场景
RCAlign在自动驾驶感知系统中具有重要的应用价值,可以提高3D目标检测的精度和鲁棒性。该方法还可以应用于机器人导航、智能交通监控等领域,提升复杂环境下的感知能力。未来,可以进一步探索将RCAlign与其他模态的数据进行融合,例如激光雷达,以实现更全面的环境感知。
📄 摘要(原文)
Recently, 3D object detection algorithms based on radar and camera fusion have shown excellent performance, setting the stage for their application in autonomous driving perception tasks. Existing methods have focused on dealing with feature misalignment caused by the domain gap between radar and camera. However, existing methods either neglect inter-modal features interaction during alignment or fail to effectively align features at the same spatial location across modalities. To alleviate the above problems, we propose a new alignment model called Radar Camera Alignment (RCAlign). Specifically, we design a Dual-Route Alignment (DRA) module based on contrastive learning to align and fuse the features between radar and camera. Moreover, considering the sparsity of radar BEV features, a Radar Feature Enhancement (RFE) module is proposed to improve the densification of radar BEV features with the knowledge distillation loss. Experiments show RCAlign achieves a new state-of-the-art on the public nuScenes benchmark in radar camera fusion for 3D Object Detection. Furthermore, the RCAlign achieves a significant performance gain (4.3\% NDS and 8.4\% mAP) in real-time 3D detection compared to the latest state-of-the-art method (RCBEVDet).