DERD-Net: Learning Depth from Event-based Ray Densities
作者: Diego Hitzges, Suman Ghosh, Guillermo Gallego
分类: cs.CV, cs.LG, cs.RO, eess.SP
发布日期: 2025-04-22 (更新: 2025-10-24)
备注: 17 pages, 3 figures, 15 tables. Project page: https://github.com/tub-rip/DERD-Net. 39th Conference on Neural Information Processing Systems (NeurIPS), San Diego, 2025
🔗 代码/项目: GITHUB
💡 一句话要点
DERD-Net:提出基于事件相机射线密度的深度学习方法,提升单目和双目深度估计精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 事件相机 深度估计 射线密度 视差空间图像 3D卷积 循环神经网络 机器人视觉 SLAM
📋 核心要点
- 传统深度学习框架难以处理事件数据的异步流式特性,因为它们针对离散的图像类输入进行了优化。
- 论文提出DERD-Net,通过将事件反投影到空间中形成射线密度,并使用3D卷积和循环结构处理视差空间图像(DSI)。
- 实验表明,DERD-Net在单目和双目深度估计任务上均取得了显著提升,尤其在双目数据上,平均绝对误差降低了至少42%。
📝 摘要(中文)
本文提出了一种可扩展、灵活且适应性强的框架,用于利用事件相机进行像素级深度估计,适用于单目和双目设置。该方法将3D场景结构编码为视差空间图像(DSI),DSI表示通过将事件反投影到空间中获得的射线空间密度,其中相机位姿已知。神经网络处理DSI的局部子区域,结合3D卷积和循环结构来识别用于深度预测的有效模式。局部处理实现了快速推理和完全并行化,并确保了恒定的超低模型复杂性和内存成本,而与相机分辨率无关。在标准基准(MVSEC和DSEC数据集)上的实验表明,该方法具有前所未有的有效性:(i)仅使用单目数据,该方法即可获得与现有立体方法相当的结果;(ii)当应用于立体数据时,它大大优于所有最先进的方法,将平均绝对误差降低了至少42%;(iii)该方法还使深度完整性提高了3倍以上,同时仍将中值绝对误差降低了至少30%。凭借其卓越的性能和对事件数据的有效处理,该框架具有成为使用深度学习进行基于事件的深度估计和SLAM的标准方法的强大潜力。
🔬 方法详解
问题定义:事件相机具有高速度和宽广照明条件下检测无模糊3D边缘的能力,使其在多视图立体深度估计和SLAM中具有潜力。然而,事件数据是异步和流式的,这与传统相机产生的图像帧不同。现有深度学习方法难以直接处理这种数据,导致深度估计精度不高。
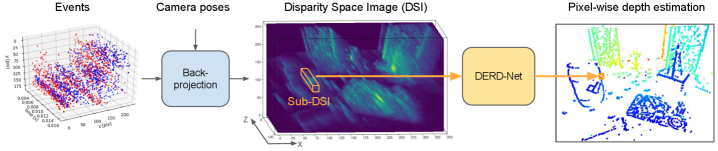
核心思路:论文的核心思路是将事件数据转换为视差空间图像(DSI),DSI表示射线在空间中的密度。通过将事件反投影到3D空间中,可以得到一系列射线,而DSI则记录了这些射线的空间分布。这种表示方法能够有效地捕捉场景的几何信息,并将其转化为深度学习模型可以处理的形式。
技术框架:DERD-Net的整体框架包括以下几个主要步骤:1) 事件数据预处理,将事件流转换为DSI;2) 使用3D卷积神经网络处理DSI的局部子区域,提取特征;3) 使用循环神经网络(RNN)对提取的特征进行时序建模,进一步提升深度估计的准确性;4) 通过回归层预测每个像素的深度值。
关键创新:该方法最重要的创新点在于将事件数据转换为射线密度表示(DSI),并使用3D卷积和循环神经网络进行处理。这种方法能够有效地利用事件数据的时空信息,并克服了传统深度学习方法在处理异步数据方面的局限性。此外,局部处理策略使得模型复杂度与相机分辨率无关,保证了推理速度。
关键设计:在网络结构方面,DERD-Net采用了3D卷积层来提取DSI中的空间特征,并使用GRU(Gated Recurrent Unit)来对时序信息进行建模。损失函数采用L1损失,以提高深度估计的准确性。此外,论文还使用了数据增强技术,例如随机旋转和缩放,以提高模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DERD-Net在MVSEC和DSEC数据集上取得了显著的性能提升。在单目深度估计任务中,该方法达到了与现有立体方法相当的水平。在立体深度估计任务中,该方法优于所有最先进的方法,将平均绝对误差降低了至少42%。此外,该方法还使深度完整性提高了3倍以上,同时仍将中值绝对误差降低了至少30%。
🎯 应用场景
DERD-Net在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。它可以帮助机器人在光照条件不佳或高速运动的情况下准确地感知周围环境的深度信息,从而实现更安全、更可靠的自主导航和控制。此外,该方法还可以用于构建高精度的3D地图,为增强现实应用提供支持。
📄 摘要(原文)
Event cameras offer a promising avenue for multi-view stereo depth estimation and Simultaneous Localization And Mapping (SLAM) due to their ability to detect blur-free 3D edges at high-speed and over broad illumination conditions. However, traditional deep learning frameworks designed for conventional cameras struggle with the asynchronous, stream-like nature of event data, as their architectures are optimized for discrete, image-like inputs. We propose a scalable, flexible and adaptable framework for pixel-wise depth estimation with event cameras in both monocular and stereo setups. The 3D scene structure is encoded into disparity space images (DSIs), representing spatial densities of rays obtained by back-projecting events into space via known camera poses. Our neural network processes local subregions of the DSIs combining 3D convolutions and a recurrent structure to recognize valuable patterns for depth prediction. Local processing enables fast inference with full parallelization and ensures constant ultra-low model complexity and memory costs, regardless of camera resolution. Experiments on standard benchmarks (MVSEC and DSEC datasets) demonstrate unprecedented effectiveness: (i) using purely monocular data, our method achieves comparable results to existing stereo methods; (ii) when applied to stereo data, it strongly outperforms all state-of-the-art (SOTA) approaches, reducing the mean absolute error by at least 42%; (iii) our method also allows for increases in depth completeness by more than 3-fold while still yielding a reduction in median absolute error of at least 30%. Given its remarkable performance and effective processing of event-data, our framework holds strong potential to become a standard approach for using deep learning for event-based depth estimation and SLAM. Project page: https://github.com/tub-rip/DERD-Net