Uni3C: Unifying Precisely 3D-Enhanced Camera and Human Motion Controls for Video Generation
作者: Chenjie Cao, Jingkai Zhou, Shikai Li, Jingyun Liang, Chaohui Yu, Fan Wang, Xiangyang Xue, Yanwei Fu
分类: cs.CV
发布日期: 2025-04-21 (更新: 2025-09-20)
备注: Project page: https://github.com/ewrfcas/Uni3C. Accepted by Siggraph Asian 2025
💡 一句话要点
Uni3C:统一3D增强的相机与人体运动控制,实现视频生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 相机控制 人体运动控制 3D建模 点云 SMPL-X 深度估计 统一框架
📋 核心要点
- 现有视频生成方法通常独立处理相机和人体运动控制,缺乏高质量的联合标注数据。
- Uni3C通过统一的3D增强框架,利用点云和SMPL-X模型,实现相机和人体运动的精确协同控制。
- 实验表明,Uni3C在相机可控性和人体运动质量上显著优于现有方法,并在具有挑战性的数据集上验证了有效性。
📝 摘要(中文)
本文提出Uni3C,一个统一的3D增强框架,用于精确控制视频生成中的相机和人体运动。Uni3C包含两个关键贡献。首先,提出了一个即插即用的控制模块PCDController,它利用单目深度生成的非投影点云来实现精确的相机控制,并使用冻结的视频生成骨干网络进行训练。PCDController凭借点云的强大3D先验和视频基础模型的强大能力,展现出卓越的泛化能力,无论推理骨干网络是否冻结或微调,都能表现良好。这种灵活性使得Uni3C的不同模块能够在特定领域(相机控制或人体运动控制)进行训练,从而降低对联合标注数据的依赖。其次,提出了一个联合对齐的3D世界引导,用于推理阶段,无缝集成场景点云和SMPL-X人物,以统一相机和人体运动的控制信号。大量实验表明,PCDController在驱动相机运动方面具有很强的鲁棒性,尤其是在微调的视频生成骨干网络上。Uni3C在相机可控性和人体运动质量方面均显著优于竞争对手。此外,我们收集了专门的验证集,包含具有挑战性的相机运动和人体动作,以验证我们方法的有效性。
🔬 方法详解
问题定义:现有视频生成方法在控制相机和人体运动时,通常是独立进行的,这导致了两个问题:一是缺乏同时包含高质量相机和人体运动标注的数据集;二是难以实现相机和人体运动的精确协同控制,影响了生成视频的真实感和可控性。
核心思路:Uni3C的核心思路是利用3D信息(点云和SMPL-X模型)作为桥梁,将相机和人体运动控制统一到一个框架中。通过3D先验知识,可以更精确地控制相机运动,并实现相机与人体运动之间的自然交互。
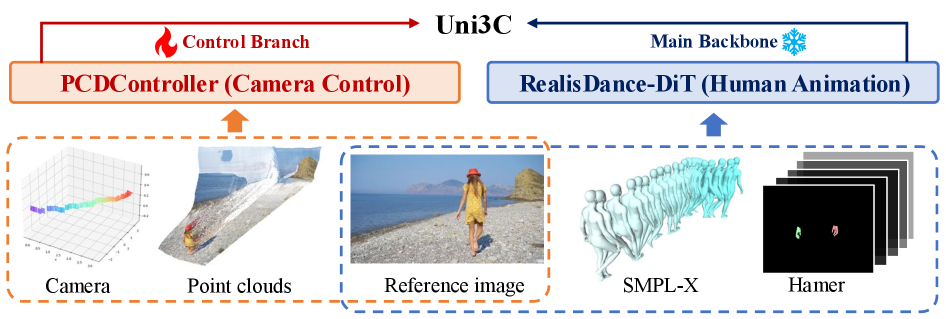
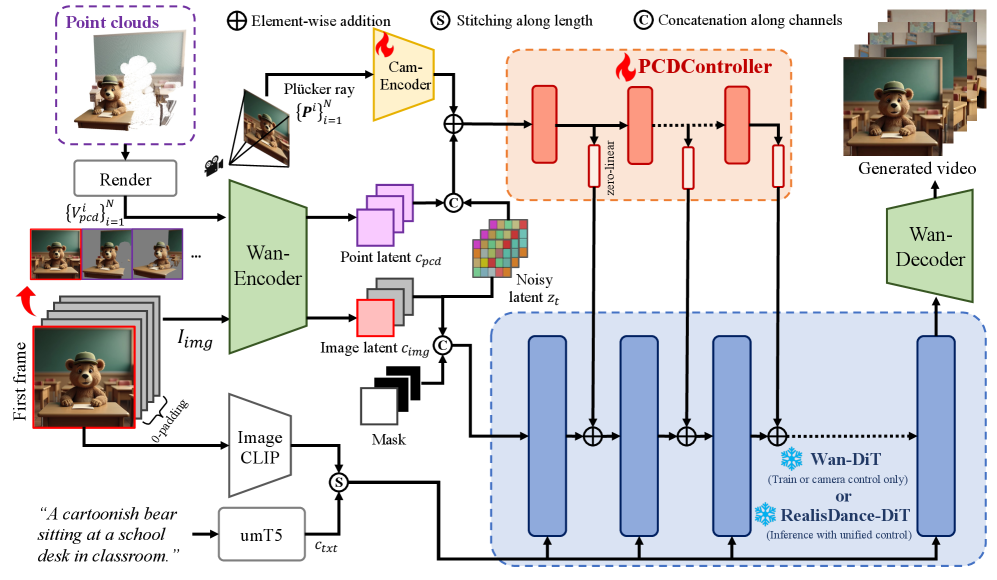
技术框架:Uni3C主要包含两个模块:PCDController和3D世界引导。PCDController是一个即插即用的相机控制模块,利用单目深度估计得到的点云信息来控制相机运动,并使用冻结的视频生成骨干网络进行训练。3D世界引导则在推理阶段,将场景点云和SMPL-X人体模型对齐,统一相机和人体运动的控制信号。整体流程是,首先使用PCDController控制相机运动,然后结合3D世界引导,控制人体运动,最后生成视频。
关键创新:Uni3C的关键创新在于:1) 提出了PCDController,利用点云进行相机控制,提高了相机控制的精度和鲁棒性;2) 提出了联合对齐的3D世界引导,将相机和人体运动控制统一到一个框架中,实现了更自然的交互。与现有方法相比,Uni3C能够更精确地控制相机和人体运动,生成更逼真、更可控的视频。
关键设计:PCDController的关键设计在于使用非投影点云作为输入,这保留了更多的3D信息,有利于精确控制相机运动。此外,PCDController使用冻结的视频生成骨干网络进行训练,这降低了对联合标注数据的依赖,提高了模型的泛化能力。3D世界引导的关键设计在于将场景点云和SMPL-X人体模型对齐,这使得相机和人体运动控制能够在一个统一的3D空间中进行,从而实现更自然的交互。具体的损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片
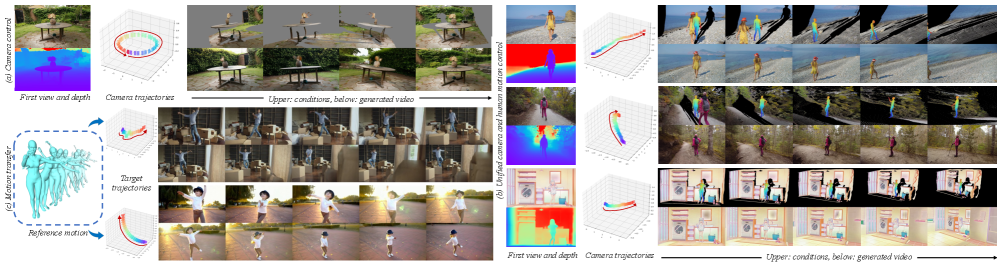
📊 实验亮点
Uni3C在相机可控性和人体运动质量方面均显著优于现有方法。实验结果表明,PCDController在驱动相机运动方面具有很强的鲁棒性,尤其是在微调的视频生成骨干网络上。此外,Uni3C在专门设计的包含具有挑战性的相机运动和人体动作的验证集上,也表现出良好的性能,验证了其有效性。具体的性能指标和对比结果在论文中有详细展示。
🎯 应用场景
Uni3C具有广泛的应用前景,例如虚拟现实、游戏开发、电影制作等领域。它可以用于生成具有精确相机运动和自然人体动作的虚拟场景,提升用户体验。此外,Uni3C还可以用于数据增强,生成更多样化的训练数据,提高其他视频生成模型的性能。未来,Uni3C有望成为视频内容创作的重要工具。
📄 摘要(原文)
Camera and human motion controls have been extensively studied for video generation, but existing approaches typically address them separately, suffering from limited data with high-quality annotations for both aspects. To overcome this, we present Uni3C, a unified 3D-enhanced framework for precise control of both camera and human motion in video generation. Uni3C includes two key contributions. First, we propose a plug-and-play control module trained with a frozen video generative backbone, PCDController, which utilizes unprojected point clouds from monocular depth to achieve accurate camera control. By leveraging the strong 3D priors of point clouds and the powerful capacities of video foundational models, PCDController shows impressive generalization, performing well regardless of whether the inference backbone is frozen or fine-tuned. This flexibility enables different modules of Uni3C to be trained in specific domains, i.e., either camera control or human motion control, reducing the dependency on jointly annotated data. Second, we propose a jointly aligned 3D world guidance for the inference phase that seamlessly integrates both scenic point clouds and SMPL-X characters to unify the control signals for camera and human motion, respectively. Extensive experiments confirm that PCDController enjoys strong robustness in driving camera motion for fine-tuned backbones of video generation. Uni3C substantially outperforms competitors in both camera controllability and human motion quality. Additionally, we collect tailored validation sets featuring challenging camera movements and human actions to validate the effectiveness of our method.