Seurat: From Moving Points to Depth
作者: Seokju Cho, Jiahui Huang, Seungryong Kim, Joon-Young Lee
分类: cs.CV
发布日期: 2025-04-20
备注: CVPR 2025 Highlight. Project page: https://seurat-cvpr.github.io
💡 一句话要点
Seurat:利用运动点轨迹推断单目视频深度变化
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 单目深度估计 运动结构恢复 Transformer网络 点轨迹跟踪 零样本学习
📋 核心要点
- 单目视频深度估计缺乏立体视觉信息,导致深度模糊性,是长期存在的难题。
- 该方法通过跟踪视频中的2D点轨迹,利用空间和时间Transformer学习轨迹间的关系,从而推断深度变化。
- 在TAPVid-3D数据集上的实验表明,该方法具有良好的零样本泛化能力,能够有效应用于真实场景。
📝 摘要(中文)
单目视频深度估计由于缺乏立体视觉等关键深度线索,一直面临挑战。受人类通过观察物体大小和间距随运动变化来感知相对深度的启发,本文提出了一种新方法,通过分析跟踪到的2D轨迹的空间关系和时间演变来推断相对深度。具体而言,我们使用现成的点跟踪模型来捕获2D轨迹。然后,我们的方法采用空间和时间Transformer来处理这些轨迹,并直接推断随时间的深度变化。在TAPVid-3D基准测试中评估表明,我们的方法表现出强大的零样本性能,能够有效地从合成数据集泛化到真实世界数据集。结果表明,我们的方法在不同领域实现了时间上平滑、高精度的深度预测。
🔬 方法详解
问题定义:单目视频深度估计旨在从单个摄像头拍摄的视频中恢复场景的深度信息。现有方法通常依赖于大量的监督数据或复杂的几何约束,但在真实场景中泛化能力有限,且难以处理遮挡、光照变化等问题。缺乏有效的深度线索是单目深度估计的主要痛点。
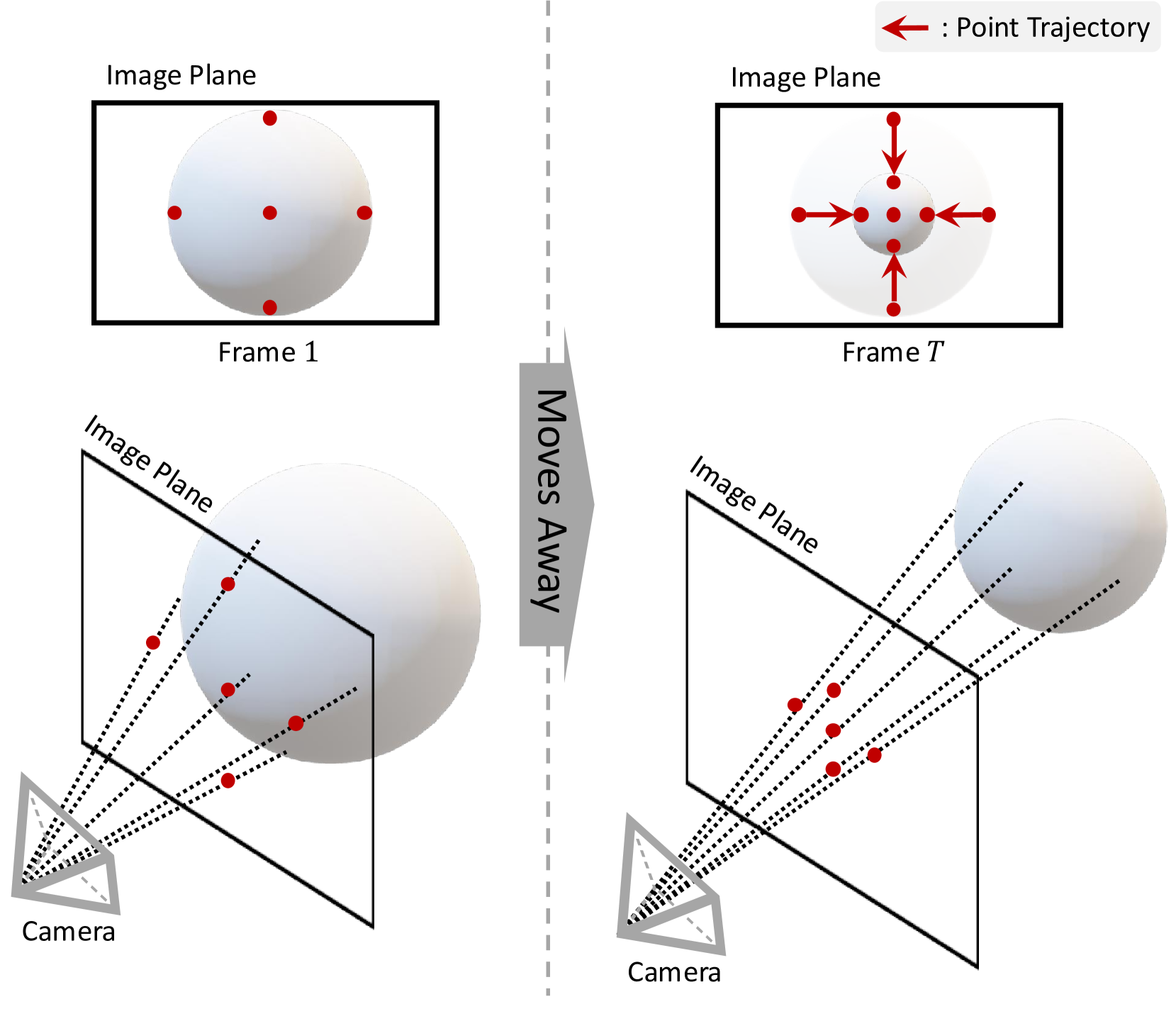
核心思路:该论文的核心思路是模仿人类通过观察物体运动来感知深度的机制。通过跟踪视频中的特征点,并分析这些点在时间和空间上的相对关系,可以推断出场景的深度变化。这种方法避免了直接预测绝对深度,而是关注相对深度变化,从而降低了问题的难度。
技术框架:该方法主要包含以下几个阶段:1) 2D点轨迹跟踪:使用现成的点跟踪模型(如RAFT)提取视频中的2D轨迹。2) 空间Transformer:利用空间Transformer处理每一帧中的轨迹点,学习轨迹点之间的空间关系。3) 时间Transformer:利用时间Transformer处理不同帧之间的轨迹,学习轨迹的时间演变信息。4) 深度变化预测:基于空间和时间Transformer的输出,预测每一帧的深度变化。
关键创新:该方法最重要的创新点在于将深度估计问题转化为轨迹分析问题。通过分析轨迹的空间和时间关系,可以有效地推断出深度变化,而无需依赖复杂的几何约束或大量的监督数据。此外,使用空间和时间Transformer能够有效地捕捉轨迹之间的复杂关系。
关键设计:空间Transformer和时间Transformer的具体结构未知,论文中可能未详细描述。损失函数的设计可能包括时间一致性损失,以保证深度变化的平滑性。具体的参数设置未知。
🖼️ 关键图片


📊 实验亮点
该方法在TAPVid-3D数据集上取得了显著的零样本性能,表明其具有良好的泛化能力。具体性能数据未知,但摘要中强调了其在不同领域实现了时间上平滑、高精度的深度预测。该方法能够有效地从合成数据泛化到真实世界数据,克服了传统方法在真实场景中表现不佳的问题。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、视频编辑、增强现实等领域。通过单目视频进行深度估计,可以帮助机器人更好地理解周围环境,实现自主导航。在自动驾驶领域,可以提高车辆对障碍物的感知能力,提升安全性。在视频编辑和增强现实领域,可以实现更逼真的三维效果。
📄 摘要(原文)
Accurate depth estimation from monocular videos remains challenging due to ambiguities inherent in single-view geometry, as crucial depth cues like stereopsis are absent. However, humans often perceive relative depth intuitively by observing variations in the size and spacing of objects as they move. Inspired by this, we propose a novel method that infers relative depth by examining the spatial relationships and temporal evolution of a set of tracked 2D trajectories. Specifically, we use off-the-shelf point tracking models to capture 2D trajectories. Then, our approach employs spatial and temporal transformers to process these trajectories and directly infer depth changes over time. Evaluated on the TAPVid-3D benchmark, our method demonstrates robust zero-shot performance, generalizing effectively from synthetic to real-world datasets. Results indicate that our approach achieves temporally smooth, high-accuracy depth predictions across diverse domains.