Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
作者: Kaihang Pan, Wang Lin, Zhongqi Yue, Tenglong Ao, Liyu Jia, Wei Zhao, Juncheng Li, Siliang Tang, Hanwang Zhang
分类: cs.CV
发布日期: 2025-04-20
备注: Accepted by CVPR 2025 (Oral)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于离散扩散时间步Token的生成式多模态预训练方法,提升多模态理解与生成能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 扩散模型 视觉Token 生成式模型
📋 核心要点
- 现有多模态大语言模型依赖空间视觉Token,但空间Token缺乏语言的递归结构,限制了模型性能。
- 利用扩散时间步学习离散递归视觉Token,递归补偿噪声图像中的属性损失,构建合适的视觉语言。
- 实验结果表明,该方法在多模态理解和生成任务上均优于其他多模态大语言模型。
📝 摘要(中文)
本文提出了一种新的多模态大型语言模型(MLLM)方法,旨在统一视觉理解和生成。该方法结合了LLM和扩散模型各自的优势。现有方法依赖于空间视觉Token,但本文指出空间Token缺乏语言固有的递归结构,使得LLM难以掌握。本文通过利用扩散时间步来学习离散的、递归的视觉Token,构建了一种合适的视觉语言。提出的Token递归地补偿噪声图像中随时间步增加而逐渐损失的属性,使得扩散模型能够在任何时间步重建原始图像。这种方法有效地整合了LLM在自回归推理方面的优势和扩散模型在精确图像生成方面的优势,从而在统一的框架内实现无缝的多模态理解和生成。大量实验表明,与其他MLLM相比,该方法在多模态理解和生成方面均取得了优异的性能。
🔬 方法详解
问题定义:现有MLLM方法依赖于空间视觉Token,例如将图像分割成patch并按栅格扫描顺序排列。这种空间Token缺乏语言固有的递归结构,导致LLM难以有效地学习和利用视觉信息,从而限制了多模态理解和生成能力。现有方法的痛点在于视觉表征方式与语言模型的内在机制不匹配。
核心思路:本文的核心思路是利用扩散模型的扩散时间步(diffusion timestep)来学习离散的、递归的视觉Token。随着扩散过程的进行,图像逐渐被噪声破坏,而扩散时间步可以看作是图像质量的度量。通过学习与不同时间步对应的Token,模型可以递归地补偿噪声图像中逐渐损失的属性,从而构建一种具有递归结构的视觉语言。这种视觉语言更符合LLM的建模方式,有助于提升多模态理解和生成能力。
技术框架:整体框架包含以下几个主要模块:1) 视觉编码器:将图像编码成一系列的视觉特征。2) 扩散模型:用于生成不同时间步的噪声图像。3) Token学习模块:学习与不同时间步对应的离散视觉Token。4) LLM:用于处理视觉Token和文本信息,进行多模态理解和生成。流程如下:首先,图像通过视觉编码器得到视觉特征。然后,扩散模型生成一系列不同时间步的噪声图像。接着,Token学习模块学习与这些噪声图像对应的离散视觉Token。最后,LLM将这些视觉Token和文本信息结合起来,进行多模态理解和生成。
关键创新:最重要的技术创新点在于利用扩散时间步来学习离散的、递归的视觉Token。与传统的空间Token相比,这种Token具有更强的递归结构,更符合LLM的建模方式。此外,通过递归地补偿噪声图像中的属性损失,模型可以更好地捕捉图像的全局信息和细节信息。
关键设计:在Token学习模块中,可以使用VQ-VAE等方法来学习离散的视觉Token。损失函数可以包括重构损失和量化损失,以保证Token的质量和离散性。在LLM中,可以使用Transformer等模型来处理视觉Token和文本信息。关键参数包括Token的数量、扩散模型的步数、LLM的层数等。具体数值在论文中未明确给出,属于未知信息。
🖼️ 关键图片
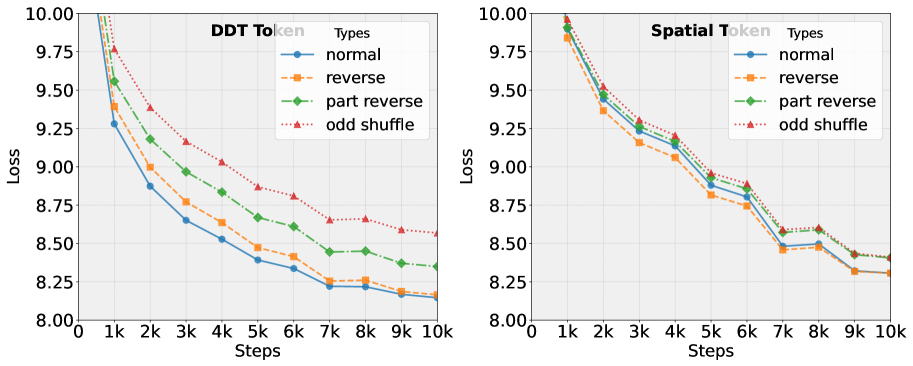


📊 实验亮点
实验结果表明,该方法在多模态理解和生成任务上均取得了优异的性能,优于其他MLLM。具体的性能数据和对比基线在摘要中未给出,属于未知信息。但论文强调,该方法在多模态理解和生成方面均取得了显著提升。
🎯 应用场景
该研究成果可应用于图像描述生成、视觉问答、多模态对话等领域。通过提升多模态理解和生成能力,可以实现更智能的人机交互,例如帮助视障人士理解图像内容,或者生成更逼真的虚拟场景。未来,该方法有望在智能客服、教育娱乐等领域发挥重要作用。
📄 摘要(原文)
Recent endeavors in Multimodal Large Language Models (MLLMs) aim to unify visual comprehension and generation by combining LLM and diffusion models, the state-of-the-art in each task, respectively. Existing approaches rely on spatial visual tokens, where image patches are encoded and arranged according to a spatial order (e.g., raster scan). However, we show that spatial tokens lack the recursive structure inherent to languages, hence form an impossible language for LLM to master. In this paper, we build a proper visual language by leveraging diffusion timesteps to learn discrete, recursive visual tokens. Our proposed tokens recursively compensate for the progressive attribute loss in noisy images as timesteps increase, enabling the diffusion model to reconstruct the original image at any timestep. This approach allows us to effectively integrate the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework. Extensive experiments show that we achieve superior performance for multimodal comprehension and generation simultaneously compared with other MLLMs. Project Page: https://DDT-LLaMA.github.io/.