Relation-R1: Progressively Cognitive Chain-of-Thought Guided Reinforcement Learning for Unified Relation Comprehension
作者: Lin Li, Wei Chen, Jiahui Li, Kwang-Ting Cheng, Long Chen
分类: cs.CV
发布日期: 2025-04-20 (更新: 2025-12-13)
备注: AAAI 2026
💡 一句话要点
提出Relation-R1,通过认知链式思考引导的强化学习,统一解决关系理解问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉关系理解 链式思考 强化学习 多模态学习 语义依赖 N元关系 监督微调
📋 核心要点
- 现有方法在视觉关系理解方面不足,尤其缺乏对多实体间结构语义依赖的建模,导致结果不可靠。
- Relation-R1通过认知链式思考引导的监督微调和群体相对策略优化,显式建模结构语义依赖。
- 实验表明,Relation-R1在二元和N元关系理解上均达到SOTA,尤其在同义N元关系上泛化性更强。
📝 摘要(中文)
多模态大型语言模型(MLLM)在对象级定位和区域描述方面取得了显著进展。然而,它们在视觉关系理解方面仍然有限,即使是二元关系检测也很困难,更不用说涉及多个语义角色的N元关系了。核心原因是缺乏对多实体之间结构语义依赖性的建模,导致不可靠的输出、幻觉以及过度依赖语言先验。为此,我们提出了Relation-R1,这是第一个统一的关系理解框架,它在强化学习范式中显式地集成了认知链式思考(CoT)引导的监督微调(SFT)和群体相对策略优化(GRPO)。具体来说,我们首先通过SFT建立基本的推理能力,强制执行带有思考过程的结构化输出。然后,利用GRPO通过多奖励优化来改进这些输出,优先考虑视觉语义定位而不是语言诱导的偏差,从而提高泛化能力。此外,我们研究了该框架内各种CoT策略的影响,表明在CoT指导中采用由具体到一般的渐进式方法可以进一步提高泛化能力,尤其是在捕获同义N元关系方面。在广泛使用的PSG和SWiG数据集上的大量实验表明,Relation-R1在二元和N元关系理解方面都达到了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决视觉关系理解中的结构语义依赖建模问题,现有方法难以处理N元关系,且易受语言先验影响,导致幻觉和错误结果。现有方法的痛点在于无法有效捕捉多实体间的复杂关系,泛化能力差。
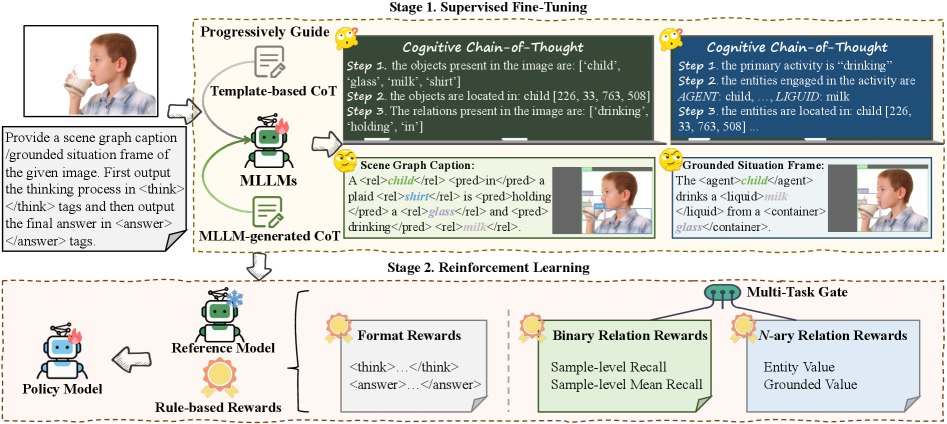
核心思路:论文的核心思路是结合认知链式思考(CoT)和强化学习(RL),通过CoT引导的监督微调(SFT)学习结构化推理过程,再利用群体相对策略优化(GRPO)增强视觉语义 grounding,从而克服语言偏差,提升泛化能力。这样设计的原因是CoT可以提供推理步骤,RL可以优化策略,二者结合可以有效提升关系理解能力。
技术框架:Relation-R1框架包含两个主要阶段:1) CoT引导的监督微调(SFT):利用CoT生成推理链,指导模型学习结构化的输出,建立初步的推理能力。2) 群体相对策略优化(GRPO):使用强化学习,通过多奖励优化策略,提升视觉语义 grounding,减少语言偏差。整体流程是先通过SFT学习推理,再通过GRPO优化推理结果。
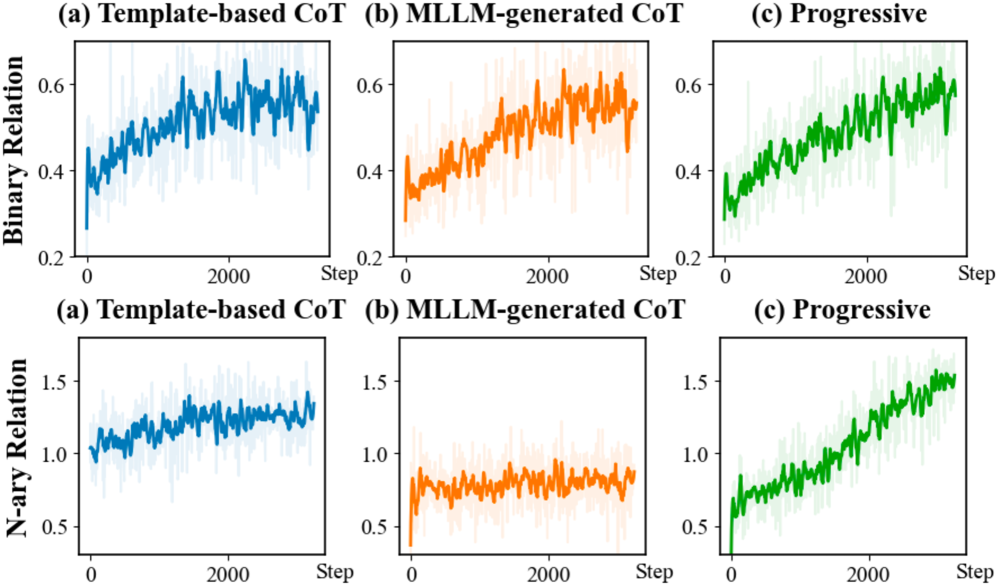
关键创新:论文的关键创新在于将认知链式思考(CoT)与强化学习(RL)相结合,提出了一个统一的关系理解框架Relation-R1。与现有方法相比,Relation-R1显式地建模了多实体之间的结构语义依赖,并利用强化学习优化视觉语义 grounding,从而提高了泛化能力。此外,论文还探索了不同的CoT策略,发现由具体到一般的渐进式CoT指导效果更好。
关键设计:在SFT阶段,使用了特定到一般的渐进式CoT策略,即先描述具体的关系,再进行抽象概括。在GRPO阶段,使用了多奖励函数,包括关系分类奖励、语义一致性奖励等,以优化视觉语义 grounding。具体参数设置和网络结构细节在论文中有详细描述,但摘要中未提及。
🖼️ 关键图片

📊 实验亮点
Relation-R1在PSG和SWiG数据集上取得了SOTA性能。实验结果表明,该方法在二元和N元关系理解方面均优于现有方法。特别是在同义N元关系识别方面,Relation-R1的泛化能力得到了显著提升。具体性能数据和对比基线在论文中有详细展示。
🎯 应用场景
该研究成果可应用于智能图像分析、视频理解、机器人视觉等领域。例如,机器人可以利用该技术理解场景中物体之间的关系,从而更好地完成任务。该研究有助于提升AI系统的感知能力和推理能力,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Recent advances in multi-modal large language models (MLLMs) have significantly improved object-level grounding and region captioning. However, they remain limited in visual relation understanding, struggling even with binary relation detection, let alone \textit{N}-ary relations involving multiple semantic roles. The core reason is the lack of modeling for \textit{structural semantic dependencies} among multi-entities, leading to unreliable outputs, hallucinations, and over-reliance on language priors (\eg, defaulting to ``person drinks a milk'' if a person is merely holding it). To this end, we propose Relation-R1, the \textit{first unified} relation comprehension framework that explicitly integrates cognitive chain-of-thought (CoT)-guided supervised fine-tuning (SFT) and group relative policy optimization (GRPO) within a reinforcement learning (RL) paradigm. Specifically, we first establish foundational reasoning capabilities via SFT, enforcing structured outputs with thinking processes. Then, GRPO is utilized to refine these outputs via multi-rewards optimization, prioritizing visual-semantic grounding over language-induced biases, thereby improving generalization capability. Furthermore, we investigate the impact of various CoT strategies within this framework, demonstrating that a specific-to-general progressive approach in CoT guidance further improves generalization, especially in capturing synonymous \textit{N}-ary relations. Extensive experiments on widely-used PSG and SWiG datasets demonstrate that Relation-R1 achieves state-of-the-art performance in both binary and \textit{N}-ary relation understanding.