NVSMask3D: Hard Visual Prompting with Camera Pose Interpolation for 3D Open Vocabulary Instance Segmentation
作者: Junyuan Fang, Zihan Wang, Yejun Zhang, Shuzhe Wang, Iaroslav Melekhov, Juho Kannala
分类: cs.CV
发布日期: 2025-04-20
备注: 15 pages, 4 figures, Scandinavian Conference on Image Analysis 2025
💡 一句话要点
提出NVSMask3D,利用相机位姿插值和硬视觉提示实现3D开放词汇实例分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D实例分割 视觉-语言模型 硬视觉提示 相机位姿插值 3D高斯溅射
📋 核心要点
- 现有视觉-语言模型在3D实例分割任务中,由于缺乏对单个对象精确定位和识别的能力,表现不佳。
- 该论文提出一种基于3D高斯溅射的硬视觉提示方法,通过相机插值生成多视角图像,增强几何一致性。
- 该方法无需训练,可与现有硬视觉提示方法结合,提升视觉-语言模型在3D场景中的实例分割性能。
📝 摘要(中文)
视觉-语言模型(VLMs)在图像级别的视觉感知任务中展现了令人印象深刻的零样本迁移能力。然而,在需要精确定位和识别单个对象的3D实例分割任务中,它们表现不足。为了弥合这一差距,我们提出了一种基于3D高斯溅射的新型硬视觉提示方法,该方法利用相机插值在目标对象周围生成不同的视角,而无需任何2D-3D优化或微调。我们的方法模拟了真实的3D视角,通过在不同视角之间强制执行几何一致性,有效地增强了现有的硬视觉提示。这种无需训练的策略与先前的硬视觉提示无缝集成,丰富了对象描述性特征,并使VLMs能够在各种3D场景中实现更鲁棒和准确的3D实例分割。
🔬 方法详解
问题定义:论文旨在解决3D开放词汇实例分割问题,即在没有特定类别训练数据的情况下,分割和识别3D场景中的物体实例。现有方法,特别是直接应用视觉-语言模型的方法,在3D场景中缺乏足够的几何信息和视角多样性,导致分割精度较低。
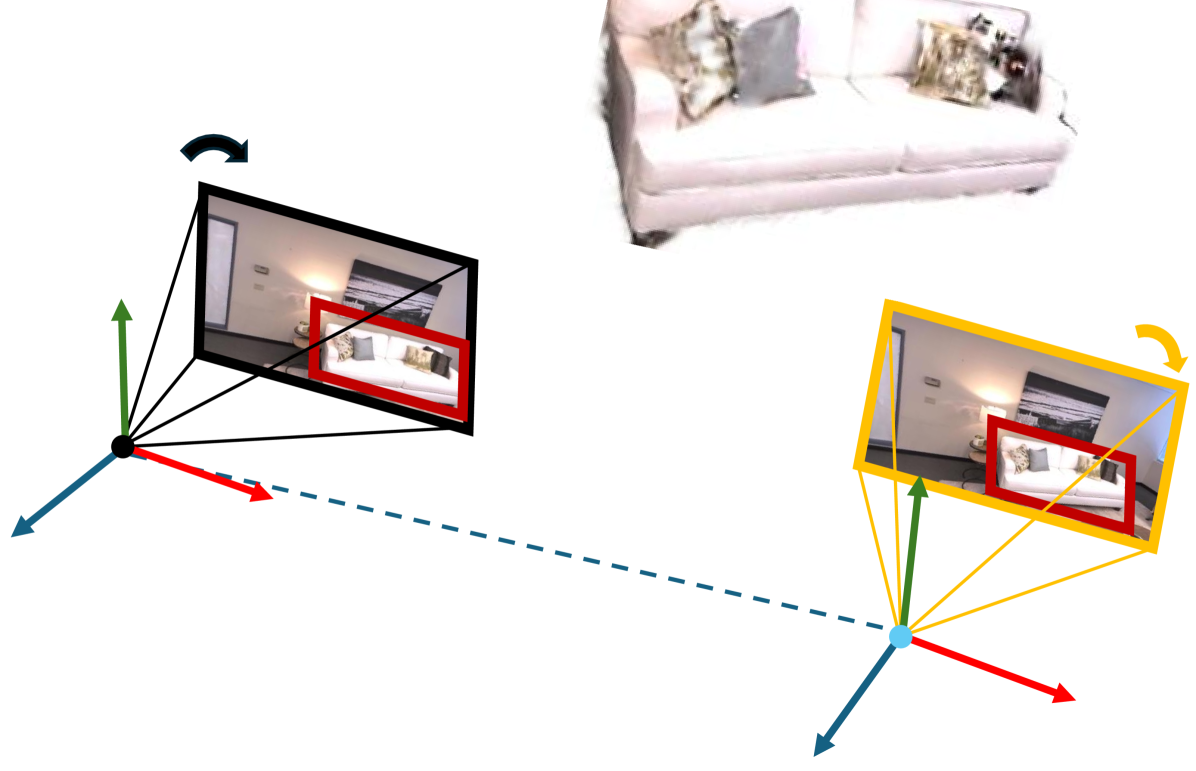
核心思路:核心思路是利用相机位姿插值生成目标物体周围的多个视角,模拟真实的3D场景观察。通过在这些视角上应用硬视觉提示,并强制视角间几何一致性,可以增强视觉-语言模型对物体特征的理解,从而提高分割精度。这种方法避免了复杂的2D-3D优化或微调过程。
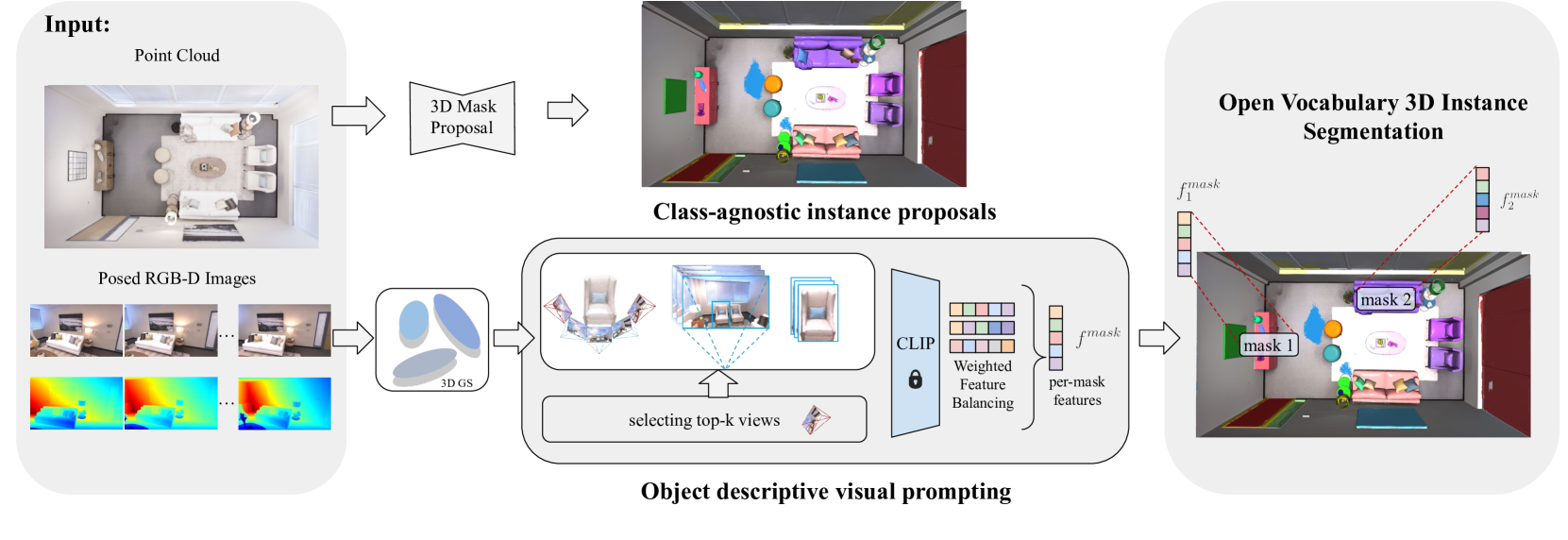
技术框架:整体框架包括以下步骤:1) 使用3D高斯溅射表示3D场景;2) 通过相机位姿插值生成目标物体周围的多个视角;3) 在每个视角上应用硬视觉提示,提取视觉特征;4) 利用视觉-语言模型,结合提取的视觉特征和文本描述,进行实例分割;5) 通过视角间的几何一致性约束,优化分割结果。
关键创新:最重要的创新点在于利用相机位姿插值生成多视角图像,并将其作为硬视觉提示的补充,从而在无需额外训练的情况下,提升视觉-语言模型在3D实例分割任务中的性能。这种方法有效地模拟了3D场景的几何信息,并增强了视觉特征的鲁棒性。
关键设计:关键设计包括:1) 相机位姿插值的策略,如何选择合适的插值方法和视角数量;2) 硬视觉提示的选择,如何设计有效的提示来引导视觉-语言模型;3) 几何一致性约束的实现,如何定义和优化视角间的几何关系。
🖼️ 关键图片
📊 实验亮点
该论文提出了一种无需训练的3D实例分割方法,通过相机位姿插值和硬视觉提示,显著提升了视觉-语言模型在3D场景中的分割性能。实验结果表明,该方法在多个3D数据集上取得了优于现有方法的性能,尤其是在开放词汇场景下,展现了强大的泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、场景理解、虚拟现实等领域。通过提升3D场景中物体实例分割的准确性,可以帮助机器人更好地理解周围环境,从而实现更智能的交互和决策。该方法无需训练的特性,使其在实际应用中具有很高的灵活性和可扩展性。
📄 摘要(原文)
Vision-language models (VLMs) have demonstrated impressive zero-shot transfer capabilities in image-level visual perception tasks. However, they fall short in 3D instance-level segmentation tasks that require accurate localization and recognition of individual objects. To bridge this gap, we introduce a novel 3D Gaussian Splatting based hard visual prompting approach that leverages camera interpolation to generate diverse viewpoints around target objects without any 2D-3D optimization or fine-tuning. Our method simulates realistic 3D perspectives, effectively augmenting existing hard visual prompts by enforcing geometric consistency across viewpoints. This training-free strategy seamlessly integrates with prior hard visual prompts, enriching object-descriptive features and enabling VLMs to achieve more robust and accurate 3D instance segmentation in diverse 3D scenes.