Are Vision LLMs Road-Ready? A Comprehensive Benchmark for Safety-Critical Driving Video Understanding
作者: Tong Zeng, Longfeng Wu, Liang Shi, Dawei Zhou, Feng Guo
分类: cs.CV, cs.CL
发布日期: 2025-04-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出DVBench:用于评估视觉语言模型在安全关键驾驶场景理解能力的综合基准
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 自动驾驶 安全关键场景 基准测试 视频理解 多模态学习 领域自适应
📋 核心要点
- 现有VLLM在通用视觉任务表现出色,但在安全关键的自动驾驶领域,其场景理解能力仍面临挑战,缺乏针对性评估。
- 论文提出DVBench基准,通过分层能力分类和人工标注,全面评估VLLM在安全关键驾驶视频理解中的感知和推理能力。
- 实验表明,现有VLLM在DVBench上表现不佳,但通过领域特定数据微调后,性能显著提升,验证了针对性适应的必要性。
📝 摘要(中文)
视觉大型语言模型(VLLMs)在图像描述和视觉问答等通用视觉任务中表现出令人印象深刻的能力。然而,它们在自动驾驶等专业、安全关键领域的有效性在很大程度上仍未被探索。自动驾驶系统需要在复杂环境中进行复杂的场景理解,但现有的多模态基准主要关注正常驾驶条件,未能充分评估VLLM在安全关键场景中的性能。为了解决这个问题,我们引入了DVBench,这是一个开创性的基准,旨在评估VLLM在理解安全关键驾驶视频方面的性能。DVBench围绕一个分层能力分类构建,该分类与广泛采用的用于描述高度自动化驾驶系统评估中使用的驾驶场景的框架相一致,包含10,000个多项选择题,并具有人工标注的真实答案,从而能够全面评估VLLM在感知和推理方面的能力。对14个SOTA VLLM(参数范围从0.5B到72B)的实验表明存在显著的性能差距,没有模型的准确率超过40%,这突出了理解复杂驾驶场景的关键局限性。为了探究适应性,我们使用来自DVBench的领域特定数据对选定的模型进行了微调,实现了5.24到10.94个百分点的准确率提升,相对提升高达43.59%。这种改进突显了有针对性的适应的必要性,以弥合通用VLLM和任务关键型驾驶应用之间的差距。DVBench建立了一个重要的评估框架和研究路线图,用于开发满足现实世界自主系统安全性和鲁棒性要求的VLLM。我们发布了基准测试工具箱和微调模型:https://github.com/tong-zeng/DVBench.git。
🔬 方法详解
问题定义:现有视觉语言模型(VLLM)在通用视觉任务中表现良好,但在自动驾驶等安全关键领域,其性能尚未得到充分评估。现有的多模态基准测试主要关注正常驾驶条件,缺乏对安全关键场景的评估,无法准确反映VLLM在复杂驾驶环境下的理解能力。因此,需要一个专门的基准来评估VLLM在安全关键驾驶场景下的表现。
核心思路:论文的核心思路是构建一个专门针对安全关键驾驶场景的评估基准,即DVBench。该基准包含大量安全关键驾驶视频,并设计了相应的多项选择题,以评估VLLM在感知和推理方面的能力。通过对现有VLLM进行评估,并使用领域特定数据进行微调,来验证VLLM在自动驾驶领域的适用性和改进潜力。
技术框架:DVBench的整体框架包括以下几个主要部分:1) 数据收集与标注:收集包含安全关键驾驶场景的视频数据,并进行人工标注,生成多项选择题及其答案。2) 分层能力分类:构建一个分层能力分类体系,用于描述驾驶场景,并指导问题的设计。3) 模型评估:使用DVBench评估现有VLLM的性能,并分析其在不同能力方面的表现。4) 模型微调:使用DVBench的数据对选定的VLLM进行微调,以提高其在安全关键驾驶场景下的理解能力。
关键创新:DVBench的关键创新在于其专注于安全关键驾驶场景,并构建了一个分层能力分类体系。与现有的多模态基准测试相比,DVBench更贴近实际的自动驾驶应用,能够更准确地评估VLLM在复杂驾驶环境下的理解能力。此外,DVBench还提供了领域特定数据,用于微调VLLM,从而提高其在自动驾驶领域的性能。
关键设计:DVBench的关键设计包括:1) 多项选择题的设计:问题涵盖了感知、推理等多个方面,旨在全面评估VLLM的能力。2) 分层能力分类体系:该体系与自动驾驶领域的常用框架相一致,能够更准确地描述驾驶场景。3) 数据集的规模和多样性:DVBench包含10,000个多项选择题,涵盖了各种安全关键驾驶场景,保证了评估的全面性和可靠性。
🖼️ 关键图片
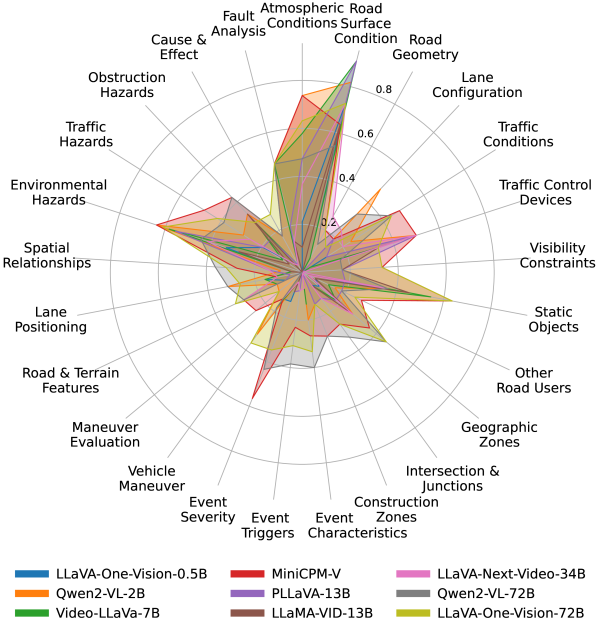
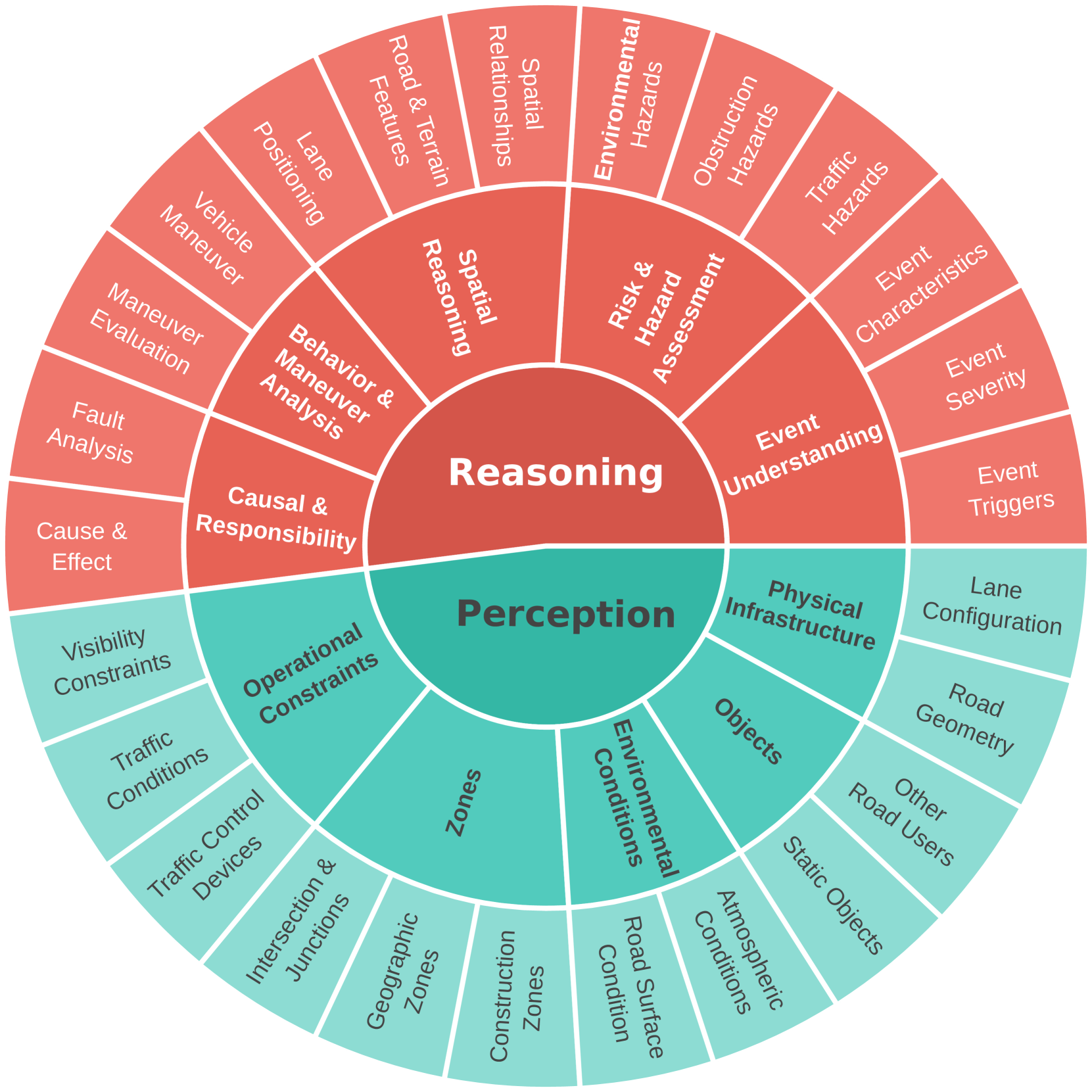

📊 实验亮点
实验结果表明,现有SOTA VLLM在DVBench上的准确率均未超过40%,表明其在安全关键驾驶场景理解方面存在显著差距。通过使用DVBench数据进行微调,模型准确率提升了5.24到10.94个百分点,相对提升高达43.59%,验证了领域特定数据微调的有效性,并为VLLM在自动驾驶领域的应用提供了新的研究方向。
🎯 应用场景
该研究成果可应用于自动驾驶系统的开发与测试,帮助评估和改进VLLM在安全关键场景下的表现。通过DVBench,可以更有效地开发出满足安全和鲁棒性要求的自动驾驶系统,从而提高道路安全性,并加速自动驾驶技术的商业化落地。此外,该基准也可用于其他安全关键领域,如机器人导航和智能监控。
📄 摘要(原文)
Vision Large Language Models (VLLMs) have demonstrated impressive capabilities in general visual tasks such as image captioning and visual question answering. However, their effectiveness in specialized, safety-critical domains like autonomous driving remains largely unexplored. Autonomous driving systems require sophisticated scene understanding in complex environments, yet existing multimodal benchmarks primarily focus on normal driving conditions, failing to adequately assess VLLMs' performance in safety-critical scenarios. To address this, we introduce DVBench, a pioneering benchmark designed to evaluate the performance of VLLMs in understanding safety-critical driving videos. Built around a hierarchical ability taxonomy that aligns with widely adopted frameworks for describing driving scenarios used in assessing highly automated driving systems, DVBench features 10,000 multiple-choice questions with human-annotated ground-truth answers, enabling a comprehensive evaluation of VLLMs' capabilities in perception and reasoning. Experiments on 14 SOTA VLLMs, ranging from 0.5B to 72B parameters, reveal significant performance gaps, with no model achieving over 40% accuracy, highlighting critical limitations in understanding complex driving scenarios. To probe adaptability, we fine-tuned selected models using domain-specific data from DVBench, achieving accuracy gains ranging from 5.24 to 10.94 percentage points, with relative improvements of up to 43.59%. This improvement underscores the necessity of targeted adaptation to bridge the gap between general-purpose VLLMs and mission-critical driving applications. DVBench establishes an essential evaluation framework and research roadmap for developing VLLMs that meet the safety and robustness requirements for real-world autonomous systems. We released the benchmark toolbox and the fine-tuned model at: https://github.com/tong-zeng/DVBench.git.