A Multimodal Recaptioning Framework to Account for Perceptual Diversity Across Languages in Vision-Language Modeling
作者: Kyle Buettner, Jacob T. Emmerson, Adriana Kovashka
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-04-19 (更新: 2025-11-11)
备注: Accepted at IJCNLP-AACL 2025 (Main)
💡 一句话要点
提出多模态重述框架,解决视觉-语言模型中跨语言感知差异问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉-语言模型 跨语言理解 感知偏差 图像重述
📋 核心要点
- 现有视觉-语言模型依赖英文描述的机器翻译进行跨语言学习,导致模型存在以英语为中心的感知偏差。
- 论文提出多模态重述框架,利用少量目标语言数据,结合近邻示例和多模态LLM推理,增强目标语言描述。
- 实验表明,该方法在德语和日语的文本-图像检索任务中,显著提升了性能,并降低了原生与翻译错误。
📝 摘要(中文)
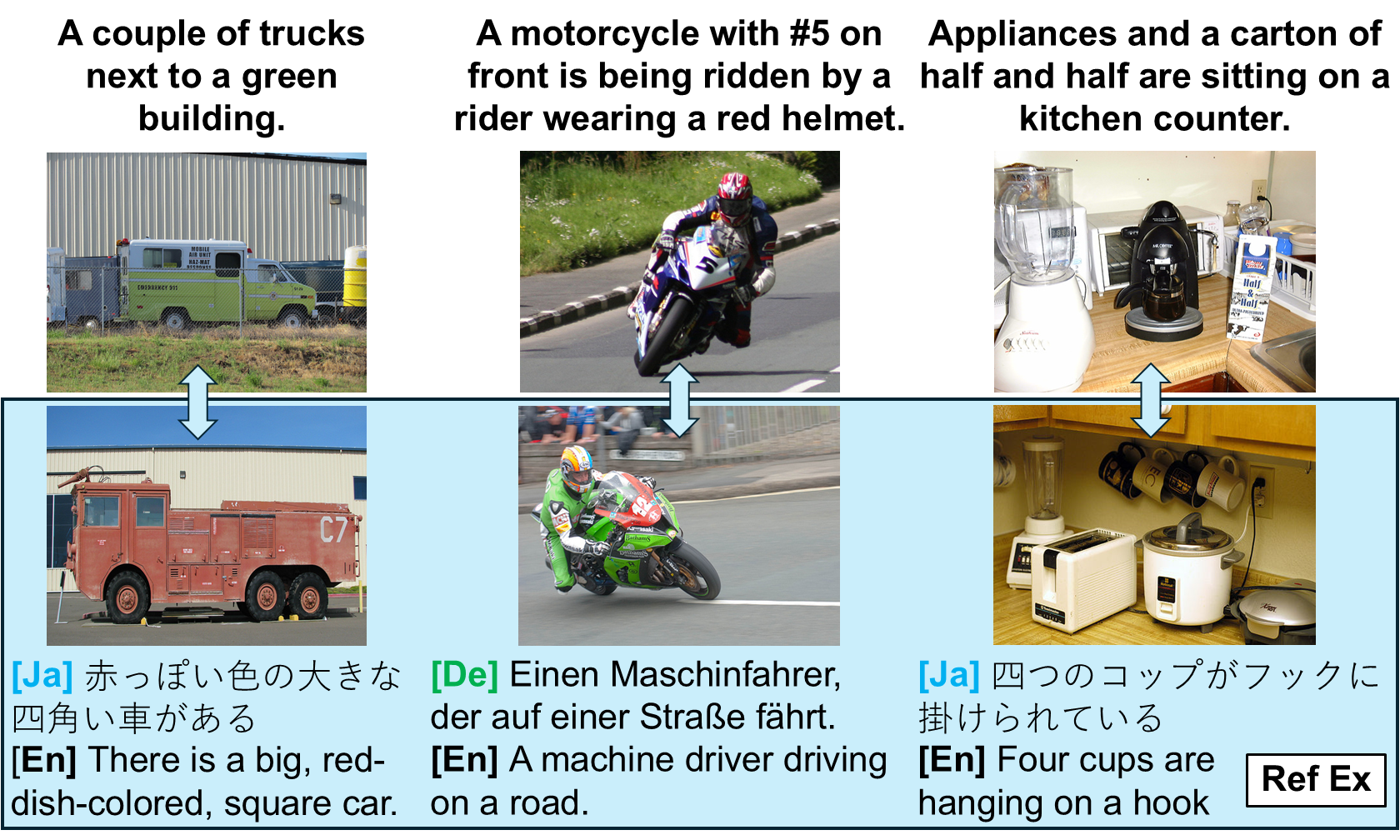
本文提出了一个框架,旨在解决视觉-语言模型(VLM)中存在的感知偏差问题。当为图像生成描述时,人们会以不同的方式描述对象,例如使用不同的术语和/或包含对他们来说在感知上值得注意的细节。尤其是在不同的语言和文化中,描述可能是独特的。现代视觉-语言模型通常通过在机器翻译的英语字幕上进行训练来获得对不同语言文本图像的理解。然而,这个过程依赖于从英语使用者的角度编写的输入内容,导致了感知偏差。本文利用少量母语数据、最近邻示例指导和多模态LLM推理来扩充字幕,以更好地反映目标语言的描述。通过将生成的重写添加到多语言CLIP微调中,在德语和日语文本-图像检索案例研究中取得了改进(平均召回率高达+3.5,原生与翻译错误高达+4.4)。此外,本文还提出了一种构建跨语言对象描述变异理解的机制,并提供了对跨数据集和跨语言泛化的见解。
🔬 方法详解
问题定义:现有的视觉-语言模型在处理多语言任务时,通常依赖于英文图像描述的机器翻译。这种方法忽略了不同语言和文化背景下人们对图像的感知差异,导致模型产生以英语为中心的感知偏差。现有方法无法充分捕捉目标语言的细微差别和文化背景,限制了模型在非英语环境下的性能。
核心思路:本文的核心思路是通过多模态重述(Recaptioning)来弥补不同语言之间的感知差异。具体来说,利用少量目标语言的母语数据,结合最近邻示例指导和多模态大型语言模型(LLM)的推理能力,将英文描述改写为更符合目标语言习惯和文化背景的描述。这样可以有效地增强模型对目标语言的理解,并减少感知偏差。
技术框架:该框架主要包含以下几个阶段:1) 数据收集:收集少量目标语言的图像描述数据。2) 近邻示例检索:对于给定的图像,在目标语言数据集中检索与其视觉内容相似的图像描述作为示例。3) 多模态LLM重述:利用多模态LLM,结合原始英文描述、图像内容和近邻示例,生成目标语言的重述描述。4) 模型微调:使用生成的重述描述对多语言CLIP模型进行微调,提升模型在目标语言上的性能。
关键创新:该方法最重要的创新点在于利用多模态LLM进行图像描述的重述,从而有效地将英文描述转化为更符合目标语言习惯和文化背景的描述。与直接使用机器翻译相比,该方法能够更好地捕捉目标语言的细微差别和文化背景,从而减少感知偏差。此外,利用近邻示例指导LLM的重述过程,可以进一步提升生成描述的质量和相关性。
关键设计:在多模态LLM重述阶段,可以使用不同的LLM模型,例如GPT-4或LLaMA。关键在于如何有效地将图像内容、原始英文描述和近邻示例输入到LLM中。一种常见的方法是将图像特征、文本描述和示例描述进行拼接,然后输入到LLM中进行生成。损失函数可以使用标准的交叉熵损失函数,用于训练LLM生成目标语言的重述描述。在CLIP模型微调阶段,可以使用对比学习损失函数,例如InfoNCE,来训练模型学习图像和文本之间的对应关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在德语和日语的文本-图像检索任务中取得了显著的提升。具体来说,在德语和日语的检索任务中,平均召回率分别提升了高达3.5%。此外,该方法还显著降低了原生与翻译错误,提升幅度高达4.4%。这些结果表明,该方法能够有效地减少视觉-语言模型中的感知偏差,并提升模型在目标语言上的性能。
🎯 应用场景
该研究成果可应用于多语言图像搜索、跨文化视觉内容理解、多语言视觉问答等领域。通过减少视觉-语言模型中的感知偏差,可以提升模型在不同语言和文化环境下的性能和公平性。未来,该方法可以推广到更多的语言和视觉任务中,促进跨文化交流和理解。
📄 摘要(原文)
When captioning an image, people describe objects in diverse ways, such as by using different terms and/or including details that are perceptually noteworthy to them. Descriptions can be especially unique across languages and cultures. Modern vision-language models (VLMs) gain understanding of images with text in different languages often through training on machine translations of English captions. However, this process relies on input content written from the perception of English speakers, leading to a perceptual bias. In this work, we outline a framework to address this bias. We specifically use a small amount of native speaker data, nearest-neighbor example guidance, and multimodal LLM reasoning to augment captions to better reflect descriptions in a target language. When adding the resulting rewrites to multilingual CLIP finetuning, we improve on German and Japanese text-image retrieval case studies (up to +3.5 mean recall, +4.4 on native vs. translation errors). We also propose a mechanism to build understanding of object description variation across languages, and offer insights into cross-dataset and cross-language generalization.