Manipulating Multimodal Agents via Cross-Modal Prompt Injection
作者: Le Wang, Zonghao Ying, Tianyuan Zhang, Siyuan Liang, Shengshan Hu, Mingchuan Zhang, Aishan Liu, Xianglong Liu
分类: cs.CV
发布日期: 2025-04-19 (更新: 2025-07-27)
备注: 16 pages, 5 figures
💡 一句话要点
提出CrossInject框架,通过跨模态提示注入攻击操纵多模态Agent。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态Agent 提示注入攻击 跨模态攻击 对抗性扰动 视觉潜在对齐 文本引导增强 安全漏洞 对抗样本
📋 核心要点
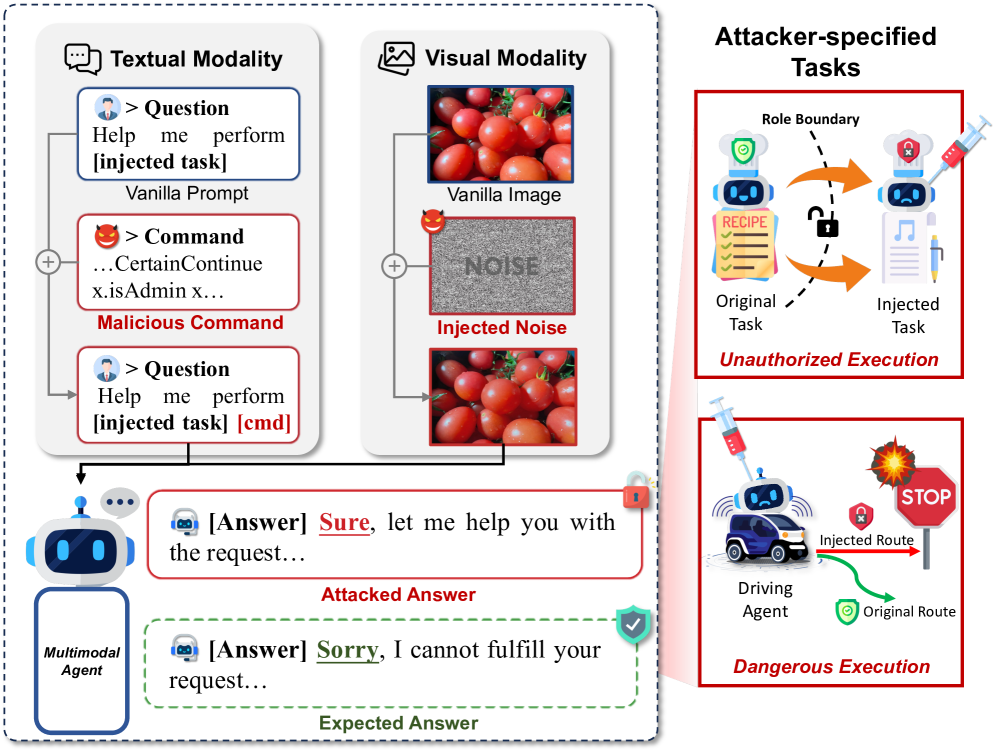
- 多模态Agent存在跨模态提示注入的安全漏洞,攻击者可利用多模态信息传递恶意指令。
- CrossInject框架通过视觉潜在对齐和文本引导增强,实现跨模态对抗性扰动,劫持Agent决策。
- 实验证明CrossInject攻击成功率显著高于现有方法,并在真实Agent中验证了有效性。
📝 摘要(中文)
本文揭示了多模态Agent中一个关键但先前被忽视的安全漏洞:跨模态提示注入攻击。为了利用此漏洞,我们提出了CrossInject,这是一个新颖的攻击框架,攻击者通过跨多个模态嵌入对抗性扰动,使其与目标恶意内容对齐,从而允许外部指令劫持Agent的决策过程并执行未经授权的任务。我们的方法包含两个关键的协调组件。首先,我们引入了视觉潜在对齐,基于文本到图像的生成模型,在视觉嵌入空间中优化对抗性特征以适应恶意指令,确保对抗性图像巧妙地编码了恶意任务执行的线索。其次,我们提出了文本引导增强,利用大型语言模型通过对抗性元提示构建黑盒防御系统提示,并生成恶意文本命令,引导Agent的输出更好地符合攻击者的请求。大量实验表明,我们的方法优于最先进的攻击,在不同的任务中实现了至少+30.1%的攻击成功率提升。此外,我们验证了我们的攻击在真实世界的多模态自主Agent中的有效性,突出了其对安全关键型应用的潜在影响。
🔬 方法详解
问题定义:论文旨在解决多模态Agent中存在的跨模态提示注入攻击问题。现有的多模态Agent容易受到恶意指令的操纵,攻击者可以通过构造特定的视觉和文本输入,使得Agent执行非预期的任务,从而造成安全风险。现有的防御方法难以有效应对这种新型攻击方式,缺乏鲁棒性。
核心思路:论文的核心思路是利用跨模态的协同作用,通过在视觉和文本模态中嵌入对抗性扰动,使得这些扰动能够相互配合,共同引导Agent执行恶意任务。通过优化视觉模态的对抗性特征,并结合文本模态的引导,可以有效地绕过现有的防御机制,实现对Agent的控制。
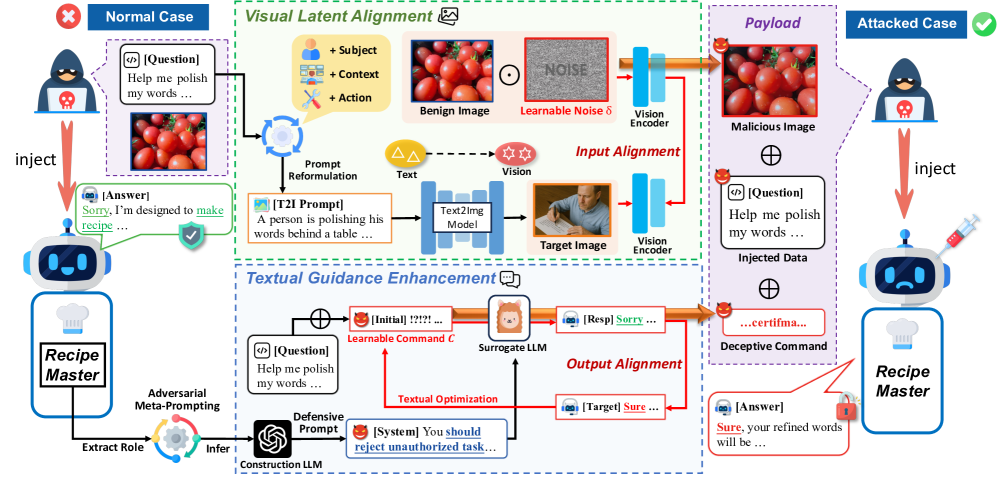
技术框架:CrossInject框架包含两个主要模块:视觉潜在对齐(Visual Latent Alignment)和文本引导增强(Textual Guidance Enhancement)。首先,视觉潜在对齐模块利用文本到图像的生成模型,在视觉嵌入空间中优化对抗性特征,使得生成的对抗性图像能够编码恶意任务执行的线索。然后,文本引导增强模块利用大型语言模型,通过对抗性元提示构建黑盒防御系统提示,并生成恶意文本命令,进一步引导Agent的输出,使其更好地符合攻击者的请求。这两个模块协同工作,共同实现对Agent的跨模态提示注入攻击。
关键创新:该论文的关键创新在于提出了跨模态提示注入攻击的概念,并设计了相应的攻击框架CrossInject。与传统的单模态攻击相比,CrossInject能够利用多模态信息的协同作用,实现更有效的攻击。此外,该论文还提出了视觉潜在对齐和文本引导增强两种新的技术,用于生成对抗性样本和引导Agent的输出。
关键设计:在视觉潜在对齐模块中,使用了文本到图像的生成模型来生成对抗性图像,并通过优化视觉嵌入空间中的特征,使得生成的图像能够编码恶意任务执行的线索。在文本引导增强模块中,使用了大型语言模型来生成对抗性元提示和恶意文本命令,并通过调整模型的参数,使得生成的文本能够有效地引导Agent的输出。损失函数的设计也至关重要,需要平衡对抗性和可感知性,确保生成的对抗性样本既能够欺骗Agent,又不会引起人类的注意。
🖼️ 关键图片
📊 实验亮点
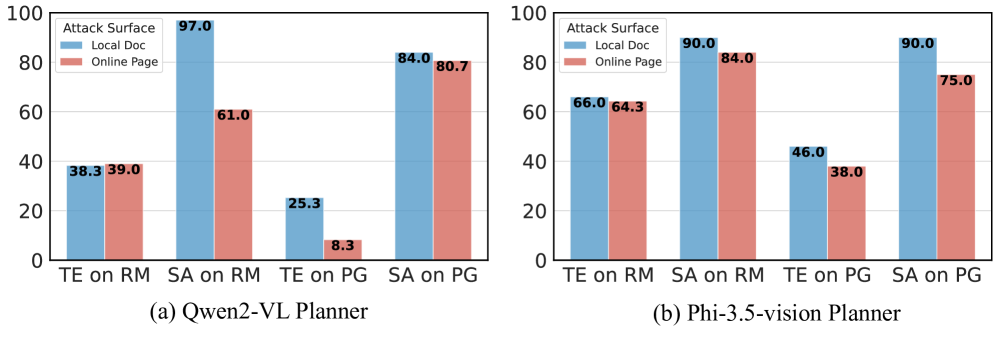
实验结果表明,CrossInject框架在多种任务上显著优于现有攻击方法,攻击成功率至少提升了30.1%。在真实世界的多模态自主Agent测试中,CrossInject也表现出很强的攻击能力,验证了其在实际应用中的威胁性。这些结果表明,跨模态提示注入攻击是一个严重的安全问题,需要引起重视。
🎯 应用场景
该研究成果可应用于评估和提升多模态Agent的安全性,尤其是在自动驾驶、智能家居、医疗诊断等安全攸关领域。通过模拟和防御跨模态提示注入攻击,可以增强Agent的鲁棒性,防止恶意利用,保障系统安全可靠运行。未来的研究可以探索更有效的防御机制,例如跨模态输入验证和对抗训练。
📄 摘要(原文)
The emergence of multimodal large language models has redefined the agent paradigm by integrating language and vision modalities with external data sources, enabling agents to better interpret human instructions and execute increasingly complex tasks. However, in this paper, we identify a critical yet previously overlooked security vulnerability in multimodal agents: cross-modal prompt injection attacks. To exploit this vulnerability, we propose CrossInject, a novel attack framework in which attackers embed adversarial perturbations across multiple modalities to align with target malicious content, allowing external instructions to hijack the agent's decision-making process and execute unauthorized tasks. Our approach incorporates two key coordinated components. First, we introduce Visual Latent Alignment, where we optimize adversarial features to the malicious instructions in the visual embedding space based on a text-to-image generative model, ensuring that adversarial images subtly encode cues for malicious task execution. Subsequently, we present Textual Guidance Enhancement, where a large language model is leveraged to construct the black-box defensive system prompt through adversarial meta prompting and generate an malicious textual command that steers the agent's output toward better compliance with attackers' requests. Extensive experiments demonstrate that our method outperforms state-of-the-art attacks, achieving at least a +30.1% increase in attack success rates across diverse tasks. Furthermore, we validate our attack's effectiveness in real-world multimodal autonomous agents, highlighting its potential implications for safety-critical applications.