Exploring Modality Guidance to Enhance VFM-based Feature Fusion for UDA in 3D Semantic Segmentation
作者: Johannes Spoecklberger, Wei Lin, Pedro Hermosilla, Sivan Doveh, Horst Possegger, M. Jehanzeb Mirza
分类: cs.CV
发布日期: 2025-04-19
💡 一句话要点
提出基于模态引导的VFM特征融合方法,提升3D语义分割UDA性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D语义分割 无监督领域自适应 视觉基础模型 跨模态融合 模态引导
📋 核心要点
- 现有3D语义分割UDA方法难以有效利用跨模态信息,导致领域自适应性能受限。
- 提出一种模态引导的VFM特征融合方法,利用VFM的跨域特征,自适应调整图像和点云的贡献。
- 实验表明,该方法在多个数据集上显著提升了3D语义分割的UDA性能,平均mIoU提升6.5%。
📝 摘要(中文)
视觉基础模型(VFMs)已成为图像分类、图像分割和目标定位等众多下游视觉任务的常用选择。然而,它们也可以为下游3D任务提供显著的效用,这些任务可以利用跨模态信息(例如,来自配对图像数据)。在这项工作中,我们进一步探索了VFMs在基于LiDAR的3D语义分割任务中,从有标签源域数据自适应到无标签目标域数据的效用。我们的方法使用配对的2D-3D(图像和点云)数据,并依赖于VFM中鲁棒的(跨域)特征,在有标签源域和无标签目标域的混合数据上训练3D骨干网络。我们方法的关键在于一个由图像和点云流引导的融合网络,其相对贡献基于目标域进行调整。我们将提出的方法与几种最先进的方法在不同的设置下进行了广泛的比较,并取得了显著的性能提升。例如,与之前的最先进方法相比,在所有任务上的平均改进为6.5 mIoU。
🔬 方法详解
问题定义:论文旨在解决3D语义分割中,如何利用视觉基础模型(VFMs)的跨模态信息,提升无监督领域自适应(UDA)的性能。现有方法在融合图像和点云特征时,往往缺乏有效的模态引导机制,导致无法充分利用VFM的潜力,限制了模型在目标域的泛化能力。
核心思路:论文的核心思路是设计一个由图像和点云流引导的融合网络,该网络能够根据目标域的特征,自适应地调整图像和点云特征的相对贡献。通过这种模态引导机制,可以更好地利用VFM的跨域特征,从而提升UDA的性能。
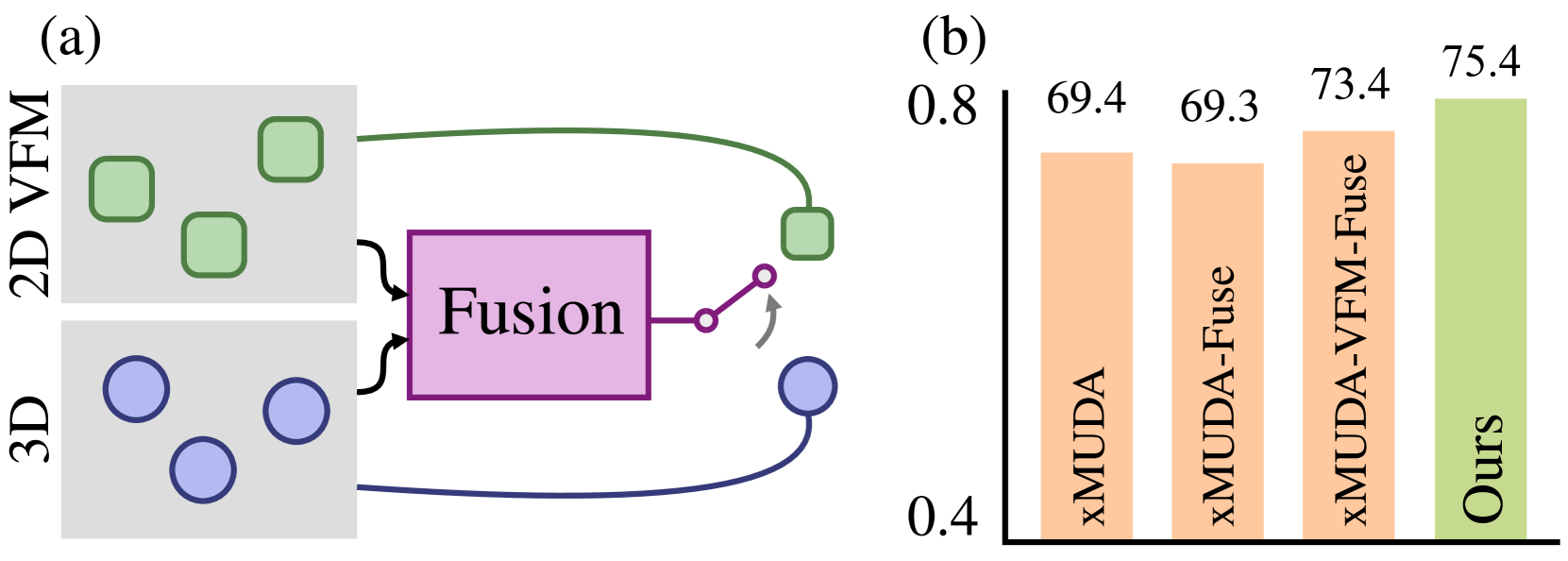
技术框架:整体框架包含以下几个主要模块:1) 2D图像分支:使用VFM提取图像特征。2) 3D点云分支:使用3D骨干网络提取点云特征。3) 模态引导融合网络:将图像和点云特征进行融合,并根据目标域的特征自适应地调整两种模态的贡献。4) 3D语义分割模块:对融合后的特征进行语义分割。整个流程是在有标签的源域和无标签的目标域数据上进行训练,通过最小化源域的分割损失和目标域的自适应损失,实现模型的领域自适应。
关键创新:最重要的技术创新点在于模态引导的融合网络。该网络能够根据目标域的特征,动态地调整图像和点云特征的权重,从而更好地利用VFM的跨域信息。与现有方法相比,该方法能够更有效地融合多模态特征,提升UDA的性能。
关键设计:融合网络的设计是关键。具体来说,可以使用注意力机制来学习图像和点云特征的权重。例如,可以设计一个注意力模块,该模块以目标域的特征作为输入,输出图像和点云特征的注意力权重。此外,损失函数的设计也很重要。除了源域的分割损失外,还需要设计一个目标域的自适应损失,例如,可以使用对抗学习或一致性正则化等方法来减小源域和目标域之间的差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个3D语义分割UDA数据集上取得了显著的性能提升。例如,与之前的state-of-the-art方法相比,在所有任务上的平均mIoU提升了6.5%。这表明该方法能够有效地利用VFM的跨模态信息,提升模型的领域自适应能力。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智慧城市等领域。通过利用视觉基础模型和跨模态信息,可以提升3D场景理解的准确性和鲁棒性,从而提高自动驾驶车辆的环境感知能力,增强机器人在复杂环境中的导航能力,并为智慧城市提供更精确的3D环境建模。
📄 摘要(原文)
Vision Foundation Models (VFMs) have become a de facto choice for many downstream vision tasks, like image classification, image segmentation, and object localization. However, they can also provide significant utility for downstream 3D tasks that can leverage the cross-modal information (e.g., from paired image data). In our work, we further explore the utility of VFMs for adapting from a labeled source to unlabeled target data for the task of LiDAR-based 3D semantic segmentation. Our method consumes paired 2D-3D (image and point cloud) data and relies on the robust (cross-domain) features from a VFM to train a 3D backbone on a mix of labeled source and unlabeled target data. At the heart of our method lies a fusion network that is guided by both the image and point cloud streams, with their relative contributions adjusted based on the target domain. We extensively compare our proposed methodology with different state-of-the-art methods in several settings and achieve strong performance gains. For example, achieving an average improvement of 6.5 mIoU (over all tasks), when compared with the previous state-of-the-art.