Enhancing Multimodal In-Context Learning for Image Classification through Coreset Optimization
作者: Huiyi Chen, Jiawei Peng, Kaihua Tang, Xin Geng, Xu Yang
分类: cs.CV, cs.AI
发布日期: 2025-04-19 (更新: 2025-07-30)
备注: 11 pages, 5 figures
💡 一句话要点
提出基于关键帧优化的KeCO框架,提升图像分类中多模态上下文学习性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 图像分类 核心集优化 多模态学习 视觉语言模型
📋 核心要点
- 现有上下文学习方法在图像分类中选择信息丰富的示例时,计算和内存成本高昂,且丢弃样本造成信息损失。
- KeCO框架利用未开发数据构建紧凑信息核心集,通过视觉特征关键帧作为锚点,更新核心集样本。
- 实验表明,KeCO有效提升图像分类的上下文学习性能,平均提升超过20%,并在模拟在线场景中表现出色。
📝 摘要(中文)
上下文学习(ICL)使大型视觉-语言模型(LVLMs)无需参数更新即可适应新任务,它利用来自大型支持集的一些示例。然而,选择信息丰富的示例会导致高昂的计算和内存成本。虽然一些方法探索在文本分类中选择小型且具有代表性的核心集,但评估所有支持集样本仍然代价高昂,并且丢弃的样本会导致不必要的信息丢失。由于特征空间的差异,这些方法对于图像分类可能效果较差。鉴于这些限制,我们提出了一种新的基于关键帧优化的框架(KeCO),该框架利用未开发的数据来构建紧凑且信息丰富的核心集。我们在核心集中引入视觉特征作为关键帧,作为识别要通过不同选择策略更新的样本的锚点。通过利用支持集中未开发的样本,我们更新所选核心集样本的关键帧,使随机初始化的核心集能够在低计算成本下演变为更具信息性的核心集。通过在粗粒度和细粒度图像分类基准上的大量实验,我们证明了KeCO有效地提高了图像分类任务的ICL性能,平均提高了20%以上。值得注意的是,我们在模拟的在线场景下评估了KeCO,并且在这种场景下的强大性能突出了我们的框架对于资源受限的现实世界场景的实际价值。
🔬 方法详解
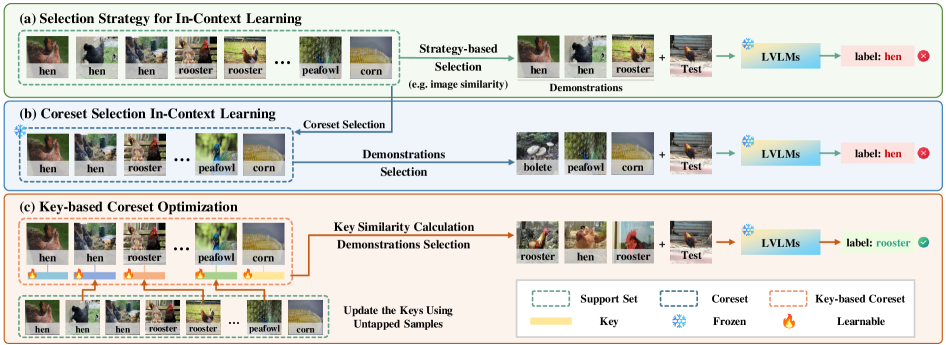
问题定义:论文旨在解决图像分类中,利用上下文学习(ICL)时,如何高效选择信息量大的示例,降低计算和内存开销的问题。现有方法,如直接从支持集中选择核心集,计算成本高,且丢弃的样本会造成信息损失。此外,文本分类领域的核心集选择方法在图像分类任务中效果不佳,因为图像和文本的特征空间存在差异。
核心思路:论文的核心思路是利用未充分利用的支持集数据,通过迭代更新核心集的方式,使其逐步演化为信息量更丰富的集合。具体来说,引入视觉特征作为核心集的“关键帧”,这些关键帧作为锚点,用于指导从支持集中选择需要更新的样本。通过这种方式,避免了对整个支持集进行评估,降低了计算成本,同时保留了更多潜在有用的信息。
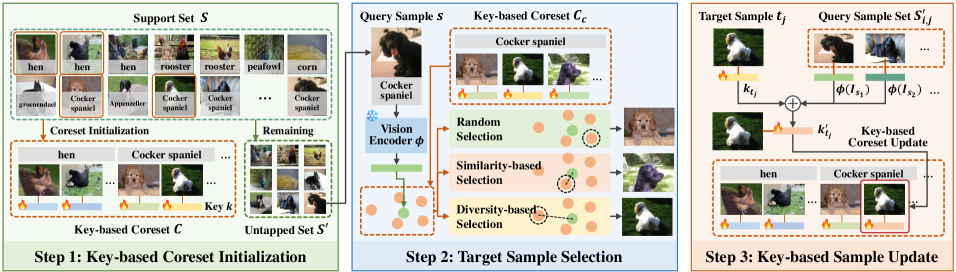
技术框架:KeCO框架主要包含以下几个阶段:1) 初始化核心集:随机初始化一个小的核心集。2) 关键帧选择:将核心集中的视觉特征作为关键帧。3) 样本选择与更新:根据关键帧,从支持集中选择需要更新的样本,并更新核心集中的对应关键帧。4) 迭代优化:重复步骤2和3,直到核心集收敛或达到预定的迭代次数。
关键创新:KeCO的关键创新在于引入了“关键帧”的概念,并将其作为核心集迭代更新的锚点。与现有方法直接从支持集中选择固定核心集不同,KeCO通过关键帧引导,动态地从支持集中提取信息,并更新核心集,从而实现更高效的信息利用和更低的计算成本。
关键设计:关键帧的选择策略(例如,基于距离或相似度),以及如何利用支持集样本更新关键帧是关键设计。具体的损失函数和网络结构(如果使用)在论文中应该有详细描述,但摘要中未提及,因此此处标记为未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,KeCO框架在粗粒度和细粒度图像分类基准上,能够有效提升上下文学习的性能,平均提升超过20%。在模拟的在线场景下,KeCO也表现出强大的性能,验证了其在实际应用中的价值。这些结果表明,KeCO能够以较低的计算成本,构建更具信息量的核心集。
🎯 应用场景
该研究成果可应用于资源受限的图像分类场景,例如移动设备上的图像识别、边缘计算环境下的视觉任务等。通过高效地选择上下文示例,KeCO能够提升模型在这些场景下的性能和效率,降低部署成本,并为在线学习和持续学习提供支持。
📄 摘要(原文)
In-context learning (ICL) enables Large Vision-Language Models (LVLMs) to adapt to new tasks without parameter updates, using a few demonstrations from a large support set. However, selecting informative demonstrations leads to high computational and memory costs. While some methods explore selecting a small and representative coreset in the text classification, evaluating all support set samples remains costly, and discarded samples lead to unnecessary information loss. These methods may also be less effective for image classification due to differences in feature spaces. Given these limitations, we propose Key-based Coreset Optimization (KeCO), a novel framework that leverages untapped data to construct a compact and informative coreset. We introduce visual features as keys within the coreset, which serve as the anchor for identifying samples to be updated through different selection strategies. By leveraging untapped samples from the support set, we update the keys of selected coreset samples, enabling the randomly initialized coreset to evolve into a more informative coreset under low computational cost. Through extensive experiments on coarse-grained and fine-grained image classification benchmarks, we demonstrate that KeCO effectively enhances ICL performance for image classification task, achieving an average improvement of more than 20\%. Notably, we evaluate KeCO under a simulated online scenario, and the strong performance in this scenario highlights the practical value of our framework for resource-constrained real-world scenarios.