DanceText: A Training-Free Layered Framework for Controllable Multilingual Text Transformation in Images
作者: Zhenyu Yu, Mohd Yamani Idna Idris, Hua Wang, Pei Wang, Rizwan Qureshi, Shaina Raza, Aman Chadha, Yong Xiang, Zhixiang Chen
分类: cs.CV
发布日期: 2025-04-18 (更新: 2025-09-26)
🔗 代码/项目: GITHUB
💡 一句话要点
DanceText:一种免训练的分层框架,用于图像中可控的多语言文本转换。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 文本编辑 图像合成 几何变换 深度感知 免训练 多语言文本 分层编辑
📋 核心要点
- 现有方法在复杂几何变换下,难以保持文本布局一致性,且可控性不足。
- DanceText采用分层编辑策略,将文本与背景分离,实现模块化和可控的几何变换。
- 实验表明,DanceText在视觉质量上表现优异,尤其是在大规模复杂变换场景下。
📝 摘要(中文)
本文提出DanceText,一个免训练的框架,用于图像中的多语言文本编辑,旨在支持复杂的几何变换并实现无缝的前景-背景融合。虽然基于扩散的生成模型在文本引导的图像合成方面显示出前景,但它们通常缺乏可控性,并且在旋转、平移、缩放和扭曲等非平凡的操作下无法保持布局一致性。为了解决这些限制,DanceText引入了一种分层编辑策略,将文本与背景分离,从而允许以模块化和可控的方式执行几何变换。进一步提出了一个深度感知模块,以对齐变换后的文本和重建的背景之间的外观和视角,从而增强照片真实感和空间一致性。重要的是,DanceText通过集成预训练模块采用完全免训练的设计,从而允许灵活部署而无需特定于任务的微调。在AnyWord-3M基准上的大量实验表明,我们的方法在视觉质量方面取得了优异的性能,尤其是在大规模和复杂的转换场景下。
🔬 方法详解
问题定义:论文旨在解决图像中多语言文本编辑的问题,特别是当需要对文本进行复杂的几何变换(如旋转、缩放、扭曲等)时,如何保证编辑后的文本与图像背景的无缝融合,同时保持文本布局的一致性和可控性。现有方法,特别是基于扩散模型的图像生成方法,在处理这类问题时,往往缺乏足够的可控性,并且难以在复杂的几何变换下保持文本的布局。
核心思路:DanceText的核心思路是将文本编辑过程分解为多个可控的步骤,通过分层编辑策略将文本与背景分离,分别进行处理。这样可以更精确地控制文本的几何变换,并利用深度感知模块来保证文本与背景在外观和视角上的一致性,从而实现更逼真的编辑效果。
技术框架:DanceText框架主要包含以下几个模块:1) 文本检测与分割模块,用于将图像中的文本区域提取出来;2) 几何变换模块,用于对提取出的文本进行旋转、缩放、扭曲等几何变换;3) 背景重建模块,用于重建文本区域被移除后的背景图像;4) 深度感知融合模块,用于将变换后的文本与重建的背景进行融合,并根据深度信息调整文本的外观,以保证空间一致性和真实感。整个流程是训练无关的,依赖于预训练模型。
关键创新:DanceText的关键创新在于其分层编辑策略和深度感知融合模块。分层编辑策略使得文本的几何变换更加可控,避免了直接对整个图像进行编辑可能导致的布局不一致问题。深度感知融合模块则通过考虑文本与背景的深度信息,实现了更逼真的融合效果,解决了传统方法中容易出现的文本与背景外观不协调的问题。
关键设计:DanceText框架的关键设计包括:1) 分层编辑策略的具体实现方式,例如如何精确地分割文本区域,以及如何对文本进行灵活的几何变换;2) 深度感知融合模块的具体实现方式,例如如何估计文本和背景的深度信息,以及如何根据深度信息调整文本的外观参数(如颜色、光照等);3) 损失函数的设计,用于优化深度感知融合模块的参数,以保证融合后的图像具有更高的真实感和空间一致性。具体的技术细节(如参数设置、网络结构等)在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片

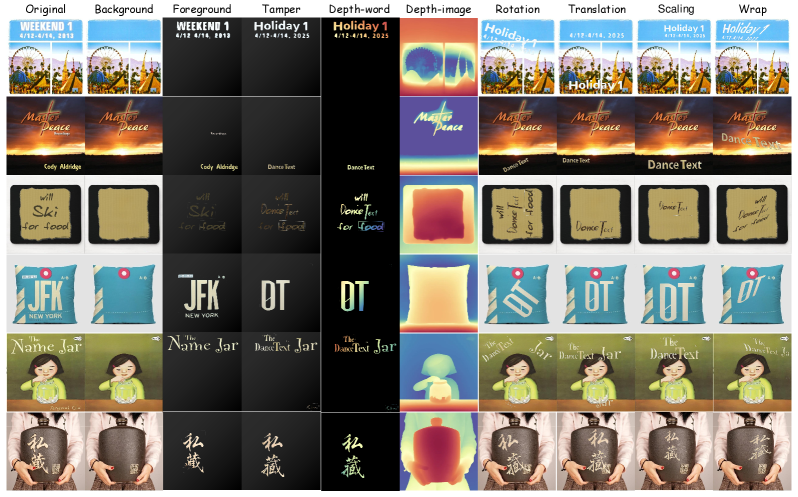

📊 实验亮点
DanceText在AnyWord-3M基准测试中表现出色,尤其是在大规模和复杂的转换场景下,视觉质量显著优于现有方法。由于采用了完全免训练的设计,DanceText可以灵活部署,无需针对特定任务进行微调,这大大降低了使用成本和部署难度。具体的性能提升数据需要在论文中查找,此处未知。
🎯 应用场景
DanceText具有广泛的应用前景,例如:广告设计、图像编辑、虚拟现实、增强现实等领域。它可以用于快速生成具有各种文本效果的图像,例如:将广告语添加到产品图片中,或者在虚拟场景中添加逼真的文本标签。此外,该技术还可以用于修复图像中的文本错误,或者将图像中的文本翻译成其他语言。
📄 摘要(原文)
We present DanceText, a training-free framework for multilingual text editing in images, designed to support complex geometric transformations and achieve seamless foreground-background integration. While diffusion-based generative models have shown promise in text-guided image synthesis, they often lack controllability and fail to preserve layout consistency under non-trivial manipulations such as rotation, translation, scaling, and warping. To address these limitations, DanceText introduces a layered editing strategy that separates text from the background, allowing geometric transformations to be performed in a modular and controllable manner. A depth-aware module is further proposed to align appearance and perspective between the transformed text and the reconstructed background, enhancing photorealism and spatial consistency. Importantly, DanceText adopts a fully training-free design by integrating pretrained modules, allowing flexible deployment without task-specific fine-tuning. Extensive experiments on the AnyWord-3M benchmark demonstrate that our method achieves superior performance in visual quality, especially under large-scale and complex transformation scenarios. Code is avaible at https://github.com/YuZhenyuLindy/DanceText.git.