VideoPASTA: 7K Preference Pairs That Matter for Video-LLM Alignment
作者: Yogesh Kulkarni, Pooyan Fazli
分类: cs.CV
发布日期: 2025-04-18 (更新: 2025-09-25)
备注: EMNLP 2025 (Main)
💡 一句话要点
VideoPASTA:通过7K偏好对齐提升视频-语言模型时空理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 视频语言模型 偏好学习 对抗样本 时空理解 视频表示 直接偏好优化 长视频理解
📋 核心要点
- 现有Video-LLM在空间关系、时间顺序和跨帧连续性理解方面存在不足,限制了其在复杂视频理解任务中的应用。
- VideoPASTA通过构建对抗样本并利用偏好优化,使模型能够区分准确和错误的视频表示,从而提升模型对时空关系的理解。
- 实验表明,VideoPASTA在多个基准测试中显著提升了现有Video-LLM的性能,且无需人工标注或大规模预训练。
📝 摘要(中文)
视频-语言模型(Video-LLM)在理解视频内容方面表现出色,但在空间关系、时间顺序和跨帧连续性方面存在困难。为了解决这些局限性,我们引入了VideoPASTA(Preference Alignment with Spatio-Temporal-Cross Frame Adversaries),这是一个通过有针对性的偏好优化来增强Video-LLM的框架。VideoPASTA训练模型来区分准确的视频表示和精心设计的对抗性示例,这些示例故意违反空间、时间或跨帧关系。仅使用7,020个偏好对和直接偏好优化,VideoPASTA使模型能够学习鲁棒的表示,从而捕获细粒度的空间细节和长程时间动态。实验表明,VideoPASTA是模型无关的,并且显着提高了性能,例如,在应用于各种最先进的Video-LLM时,在LongVideoBench上实现了高达+3.8个百分点的增益,在VideoMME上实现了+4.1个百分点的增益,在MVBench上实现了+4.0个百分点的增益。这些结果表明,有针对性的对齐,而不是大规模的预训练或架构修改,可以有效地解决核心的视频-语言挑战。值得注意的是,VideoPASTA在没有任何人工注释或字幕的情况下实现了这些改进,仅依赖于32帧采样。这种效率使我们的方法成为一种可扩展的即插即用解决方案,可以无缝地与现有模型集成,同时保留其原始功能。
🔬 方法详解
问题定义:Video-LLM虽然在视频内容理解上取得了进展,但在理解视频中的空间关系、时间顺序以及跨帧之间的连续性方面仍然存在不足。现有的方法通常依赖于大规模的预训练或者复杂的模型结构设计,但这些方法计算成本高昂,且难以针对性地解决时空理解的难题。
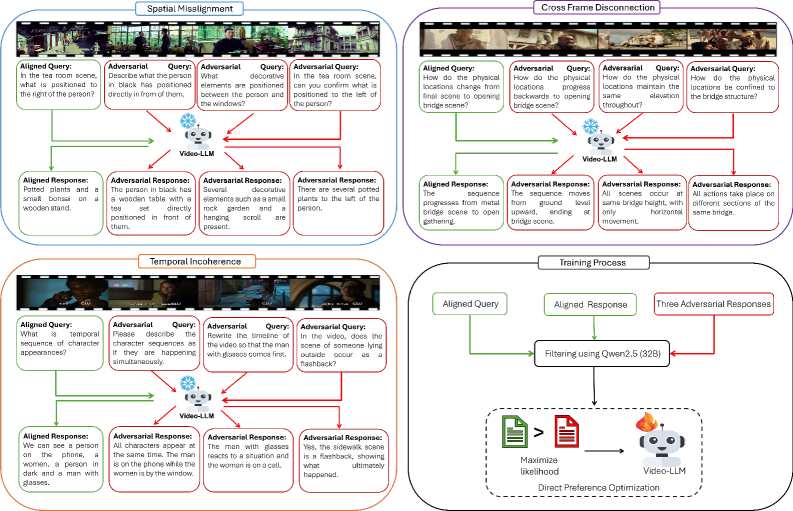
核心思路:VideoPASTA的核心思路是通过偏好学习,让模型学习区分“好”的视频表示和“坏”的视频表示。“坏”的视频表示是通过对抗攻击生成的,这些攻击专门设计来破坏视频中的空间、时间和跨帧关系。通过这种方式,模型可以学习到更加鲁棒和准确的视频表示。
技术框架:VideoPASTA的整体框架包括以下几个主要步骤:1) 从原始视频中采样32帧;2) 构建对抗样本,通过破坏空间、时间和跨帧关系生成“坏”的视频表示;3) 使用原始视频和对抗样本构建偏好对;4) 使用直接偏好优化(Direct Preference Optimization, DPO)训练Video-LLM,使其更偏好原始视频的表示。
关键创新:VideoPASTA的关键创新在于其对抗样本的构建方式和偏好学习的策略。通过精心设计的对抗样本,VideoPASTA能够针对性地提升模型对时空关系的理解能力。此外,使用DPO进行偏好学习,避免了复杂的奖励函数设计,简化了训练过程。
关键设计:VideoPASTA的关键设计包括:1) 对抗样本的生成策略,例如,通过随机打乱帧的顺序来破坏时间关系;2) 偏好对的构建方式,确保每个偏好对都包含一个“好”的视频表示和一个“坏”的视频表示;3) 使用DPO作为优化算法,DPO是一种直接优化偏好的方法,它不需要显式地定义奖励函数,而是直接优化模型对偏好数据的拟合程度。
🖼️ 关键图片
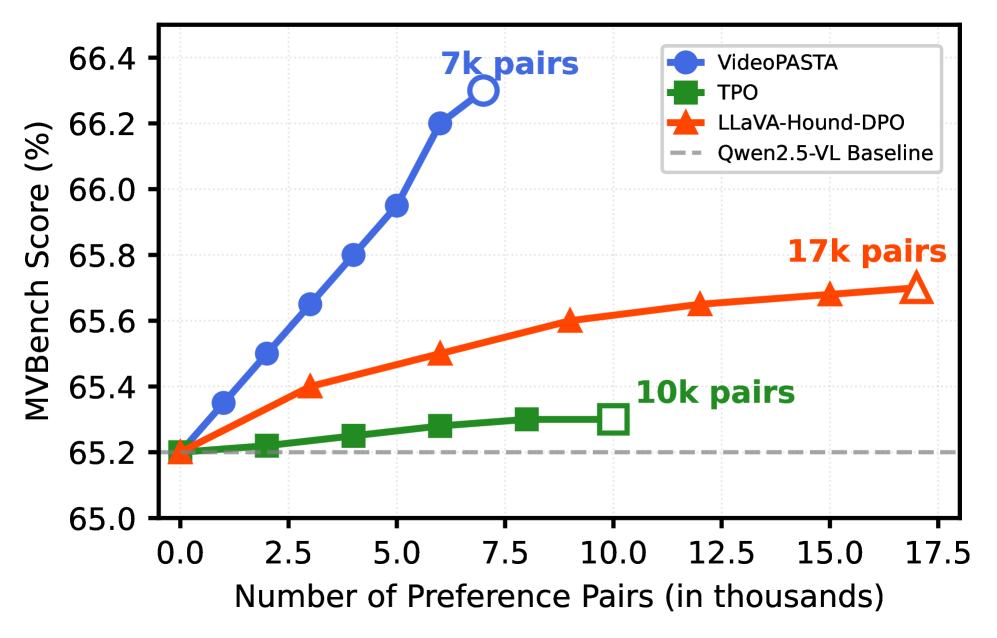

📊 实验亮点
VideoPASTA在多个视频理解基准测试中取得了显著的性能提升。例如,在LongVideoBench上提升了3.8个百分点,在VideoMME上提升了4.1个百分点,在MVBench上提升了4.0个百分点。这些结果表明,VideoPASTA能够有效地提升Video-LLM对视频内容的时空理解能力,且无需大规模的预训练或人工标注。
🎯 应用场景
VideoPASTA具有广泛的应用前景,例如视频监控、自动驾驶、视频编辑和智能助手等领域。通过提升Video-LLM对视频内容的时空理解能力,可以实现更准确的事件检测、行为识别和场景理解,从而为这些应用提供更强大的支持。此外,VideoPASTA的即插即用特性使其易于集成到现有的Video-LLM中,加速了其在实际应用中的部署。
📄 摘要(原文)
Video-language models (Video-LLMs) excel at understanding video content but struggle with spatial relationships, temporal ordering, and cross-frame continuity. To address these limitations, we introduce VideoPASTA (Preference Alignment with Spatio-Temporal-Cross Frame Adversaries), a framework that enhances Video-LLMs through targeted preference optimization. VideoPASTA trains models to distinguish accurate video representations from carefully crafted adversarial examples that deliberately violate spatial, temporal, or cross-frame relationships. With only 7,020 preference pairs and Direct Preference Optimization, VideoPASTA enables models to learn robust representations that capture fine-grained spatial details and long-range temporal dynamics. Experiments demonstrate that VideoPASTA is model agnostic and significantly improves performance, for example, achieving gains of up to +3.8 percentage points on LongVideoBench, +4.1 on VideoMME, and +4.0 on MVBench, when applied to various state-of-the-art Video-LLMs. These results demonstrate that targeted alignment, rather than massive pretraining or architectural modifications, effectively addresses core video-language challenges. Notably, VideoPASTA achieves these improvements without any human annotation or captioning, relying solely on 32-frame sampling. This efficiency makes our approach a scalable plug-and-play solution that seamlessly integrates with existing models while preserving their original capabilities.