Vision and Language Integration for Domain Generalization
作者: Yanmei Wang, Xiyao Liu, Fupeng Chu, Zhi Han
分类: cs.CV, cs.LG
发布日期: 2025-04-17
💡 一句话要点
提出VLCA,利用视觉-语言融合弥合领域差异,提升领域泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域泛化 视觉语言融合 多模态学习 语义空间 低秩逼近
📋 核心要点
- 领域泛化面临的挑战是领域差异导致难以找到通用的图像特征空间,现有方法缺乏合适的图像基本单元。
- VLCA的核心思想是结合语言空间的语义完整性和视觉空间的直观性,利用语义空间作为桥梁连接多个图像域。
- 实验结果表明,提出的VLCA方法能够有效地提升领域泛化能力,证明了该方法的有效性。
📝 摘要(中文)
领域泛化旨在通过在源域上训练模型,学习领域不变的特征空间,从而使模型在未知的目标域上具有鲁棒的泛化能力。然而,由于领域差异的存在,很难找到可靠的通用图像特征空间,其原因是缺乏合适的图像基本单元。与视觉空间中的图像不同,语言具有全面的表达元素,可以有效地传递语义。受语言语义完整性和图像直观性的启发,我们提出了VLCA,它结合了语言空间和视觉空间,并使用语义空间作为桥梁连接多个图像域。具体来说,在语言空间中,利用语言基本单元的完整性,我们倾向于通过词向量距离来捕获类别之间关系的语义表示。然后,在视觉空间中,利用图像特征的直观性,通过低秩逼近探索同一类别的样本特征的共同模式。最后,通过文本和图像的多模态空间将语言表示与视觉表示对齐。实验证明了该方法的有效性。
🔬 方法详解
问题定义:领域泛化旨在解决模型在未见过的目标领域上的泛化能力问题。现有方法通常难以提取领域不变的特征,因为图像特征受到领域偏差的影响,缺乏鲁棒性。现有的基于图像的方法难以找到可靠的通用图像特征空间,其根本原因是缺乏合适的图像基本单元,难以有效表达图像的语义信息。
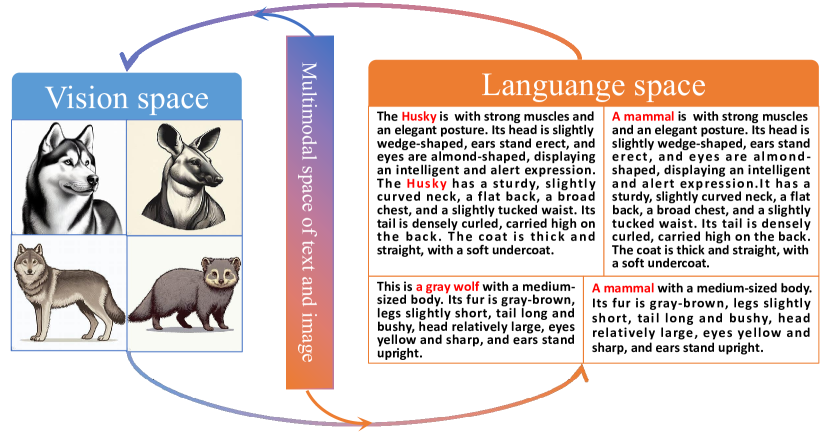
核心思路:VLCA的核心思路是利用语言的语义表达能力来辅助视觉特征的学习,从而弥合领域之间的差异。语言具有比图像更全面的表达元素,可以有效地传递语义信息。通过将图像特征与语言特征对齐,可以学习到更具领域不变性的特征表示。该方法将语义空间作为桥梁,连接多个图像域,从而实现更好的领域泛化能力。
技术框架:VLCA方法包含以下几个主要模块:1) 语言空间表示学习:利用词向量距离捕获类别之间关系的语义表示。2) 视觉空间表示学习:通过低秩逼近探索同一类别的样本特征的共同模式。3) 多模态对齐:通过文本和图像的多模态空间将语言表示与视觉表示对齐。整体流程是先分别学习语言和视觉空间的表示,然后通过多模态对齐将二者融合,最终得到领域不变的特征表示。
关键创新:VLCA的关键创新在于将语言信息引入到领域泛化问题中,利用语言的语义表达能力来辅助视觉特征的学习。与传统的仅依赖图像特征的方法不同,VLCA通过结合语言和视觉信息,可以学习到更具领域不变性的特征表示。此外,该方法还提出了一种新的多模态对齐方法,可以将语言表示与视觉表示有效地对齐。
关键设计:在语言空间表示学习中,可以使用预训练的词向量模型(如Word2Vec、GloVe)来获取类别名称的词向量表示。在视觉空间表示学习中,可以使用低秩逼近方法(如奇异值分解)来提取同一类别的样本特征的共同模式。在多模态对齐中,可以使用对比学习或交叉模态注意力机制来实现语言表示与视觉表示的对齐。损失函数可以包括对比损失、三元组损失等,用于约束语言和视觉表示之间的距离。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了VLCA方法的有效性。具体的性能数据和对比基线在摘要中未给出,但结论是该方法能够有效地提升领域泛化能力。未来的研究可以进一步探索不同模态融合策略和更有效的多模态对齐方法,以进一步提高模型的性能。
🎯 应用场景
该研究成果可应用于各种需要领域泛化的计算机视觉任务中,例如图像分类、目标检测、图像分割等。特别是在医疗影像分析、自动驾驶等领域,由于数据分布的差异性较大,领域泛化能力尤为重要。该方法可以提高模型在不同场景下的鲁棒性和泛化能力,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Domain generalization aims at training on source domains to uncover a domain-invariant feature space, allowing the model to perform robust generalization ability on unknown target domains. However, due to domain gaps, it is hard to find reliable common image feature space, and the reason for that is the lack of suitable basic units for images. Different from image in vision space, language has comprehensive expression elements that can effectively convey semantics. Inspired by the semantic completeness of language and intuitiveness of image, we propose VLCA, which combine language space and vision space, and connect the multiple image domains by using semantic space as the bridge domain. Specifically, in language space, by taking advantage of the completeness of language basic units, we tend to capture the semantic representation of the relations between categories through word vector distance. Then, in vision space, by taking advantage of the intuitiveness of image features, the common pattern of sample features with the same class is explored through low-rank approximation. In the end, the language representation is aligned with the vision representation through the multimodal space of text and image. Experiments demonstrate the effectiveness of the proposed method.