SmartFreeEdit: Mask-Free Spatial-Aware Image Editing with Complex Instruction Understanding
作者: Qianqian Sun, Jixiang Luo, Dell Zhang, Xuelong Li
分类: cs.CV, cs.MM
发布日期: 2025-04-17 (更新: 2025-11-03)
🔗 代码/项目: GITHUB
💡 一句话要点
SmartFreeEdit:提出一种无需掩码、空间感知、复杂指令理解的图像编辑框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像编辑 自然语言指令 多模态学习 超图 图像修复 空间推理 语义一致性
📋 核心要点
- 现有图像编辑方法在空间推理、精确区域分割和保持语义一致性方面面临挑战,尤其是在复杂场景中。
- SmartFreeEdit通过集成多模态大型语言模型和超图增强的图像修复,实现了无需掩码、空间感知的图像编辑。
- 实验表明,SmartFreeEdit在分割精度、指令遵循和视觉质量保持方面优于现有方法,并提升了全局一致性。
📝 摘要(中文)
本文提出SmartFreeEdit,一种新颖的端到端框架,它集成了多模态大型语言模型(MLLM)和超图增强的图像修复架构,从而实现仅通过自然语言指令引导的精确、无掩码图像编辑。SmartFreeEdit的关键创新包括:(1)引入区域感知tokens和掩码嵌入范式,增强对复杂场景的空间理解;(2)设计推理分割流程,优化基于自然语言指令的编辑掩码生成;(3)超图增强的图像修复模块,确保复杂编辑过程中结构完整性和语义一致性的保持,克服了基于局部信息的图像生成局限性。在Reason-Edit基准上的大量实验表明,SmartFreeEdit在多个评估指标上超越了当前最先进的方法,包括分割准确性、指令遵循和视觉质量保持,同时解决了局部信息关注问题,并提高了编辑图像的全局一致性。
🔬 方法详解
问题定义:现有基于自然语言指令的图像编辑方法,尤其是在处理复杂场景时,难以进行精确的空间推理和区域分割,并且难以保证编辑后图像的语义一致性。这些方法通常依赖于人工或自动生成的掩码,限制了编辑的灵活性和效率。
核心思路:SmartFreeEdit的核心思路是利用多模态大型语言模型(MLLM)理解复杂的自然语言指令,并结合超图增强的图像修复技术,在没有显式掩码的情况下,实现对图像的精确编辑。通过引入区域感知tokens和掩码嵌入范式,增强模型对图像空间信息的理解,从而更准确地定位需要编辑的区域。
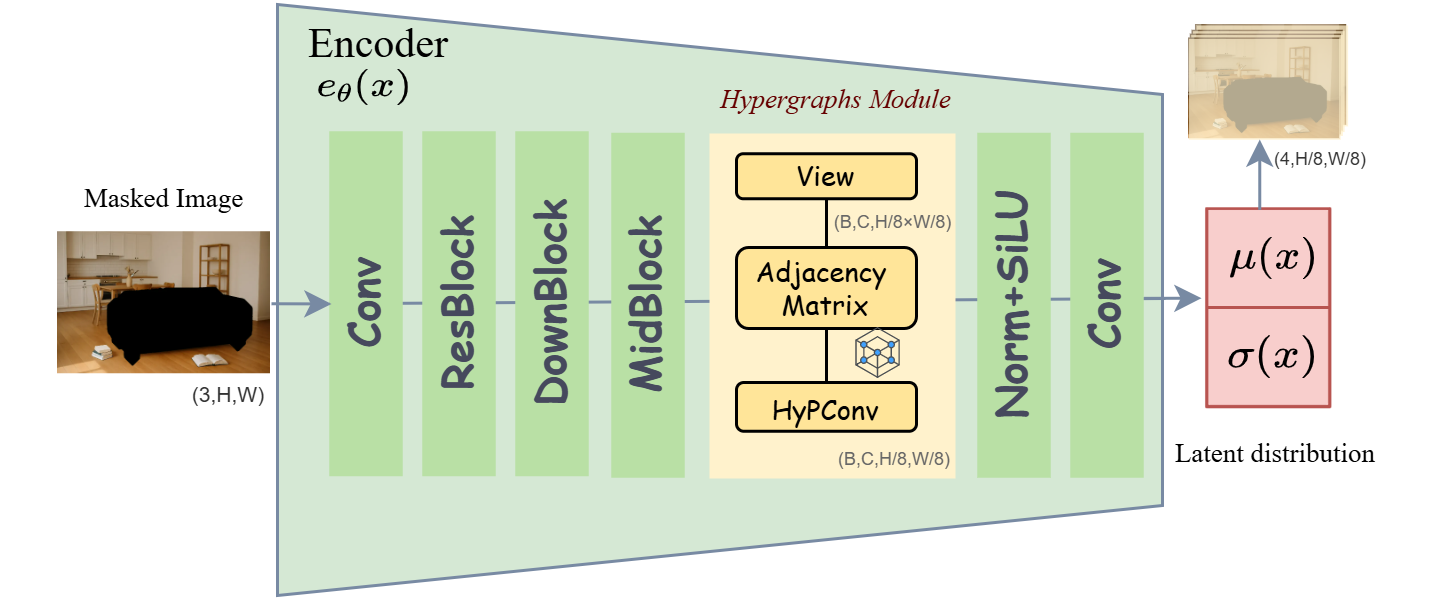
技术框架:SmartFreeEdit框架主要包含三个模块:(1)区域感知tokens和掩码嵌入模块,用于增强模型对图像空间信息的理解;(2)推理分割流程,用于根据自然语言指令生成编辑掩码;(3)超图增强的图像修复模块,用于在保持结构完整性和语义一致性的前提下,完成图像编辑。整个流程是端到端的,可以直接根据自然语言指令对图像进行编辑。
关键创新:SmartFreeEdit的关键创新在于:(1)提出了区域感知tokens和掩码嵌入范式,增强了模型对复杂场景的空间理解能力;(2)设计了推理分割流程,能够根据自然语言指令优化编辑掩码的生成;(3)引入了超图增强的图像修复模块,克服了传统局部图像修复方法在保持全局一致性方面的局限性。
关键设计:区域感知tokens通过将图像划分为多个区域,并为每个区域分配一个token,从而使模型能够更好地理解图像的空间结构。掩码嵌入范式将掩码信息嵌入到图像特征中,从而使模型能够更好地定位需要编辑的区域。超图增强的图像修复模块利用超图结构对图像中的对象关系进行建模,从而更好地保持编辑后图像的语义一致性。损失函数的设计也至关重要,需要平衡分割精度、指令遵循和视觉质量。
🖼️ 关键图片


📊 实验亮点
在Reason-Edit基准测试中,SmartFreeEdit在分割准确性、指令遵循和视觉质量保持等多个评估指标上均超越了当前最先进的方法。具体而言,SmartFreeEdit在分割准确性方面取得了显著提升,同时在保持图像视觉质量和遵循自然语言指令方面也表现出色,有效解决了局部信息关注问题,并提高了编辑图像的全局一致性。
🎯 应用场景
SmartFreeEdit具有广泛的应用前景,例如:照片编辑、图像修复、艺术创作、虚拟现实内容生成等。该技术可以帮助用户更轻松地通过自然语言指令修改图像,提高图像编辑的效率和质量。未来,该技术有望应用于智能设计、个性化定制等领域,为用户提供更加智能、便捷的图像处理服务。
📄 摘要(原文)
Recent advancements in image editing have utilized large-scale multimodal models to enable intuitive, natural instruction-driven interactions. However, conventional methods still face significant challenges, particularly in spatial reasoning, precise region segmentation, and maintaining semantic consistency, especially in complex scenes. To overcome these challenges, we introduce SmartFreeEdit, a novel end-to-end framework that integrates a multimodal large language model (MLLM) with a hypergraph-enhanced inpainting architecture, enabling precise, mask-free image editing guided exclusively by natural language instructions. The key innovations of SmartFreeEdit include:(1)the introduction of region aware tokens and a mask embedding paradigm that enhance the spatial understanding of complex scenes;(2) a reasoning segmentation pipeline designed to optimize the generation of editing masks based on natural language instructions;and (3) a hypergraph-augmented inpainting module that ensures the preservation of both structural integrity and semantic coherence during complex edits, overcoming the limitations of local-based image generation. Extensive experiments on the Reason-Edit benchmark demonstrate that SmartFreeEdit surpasses current state-of-the-art methods across multiple evaluation metrics, including segmentation accuracy, instruction adherence, and visual quality preservation, while addressing the issue of local information focus and improving global consistency in the edited image. Our project will be available at https://github.com/smileformylove/SmartFreeEdit.