Interpreting the linear structure of vision-language model embedding spaces
作者: Isabel Papadimitriou, Huangyuan Su, Thomas Fel, Sham Kakade, Stephanie Gil
分类: cs.CV, cs.CL, cs.MM
发布日期: 2025-04-16 (更新: 2025-08-20)
备注: COLM 2025
💡 一句话要点
利用稀疏自编码器解析视觉-语言模型嵌入空间的线性结构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 嵌入空间 稀疏自编码器 跨模态语义 线性结构
📋 核心要点
- 现有视觉-语言模型(VLM)的嵌入空间组织方式尚不明确,缺乏对模型如何编码意义和模态的深入理解。
- 论文提出使用稀疏自编码器(SAE)来近似VLM的嵌入,将嵌入分解为稀疏线性组合的概念,从而揭示其潜在结构。
- 实验表明,SAE能有效重建嵌入,并发现跨模态语义桥接概念,揭示了VLM如何通过潜在桥梁缝合不同模态的信息。
📝 摘要(中文)
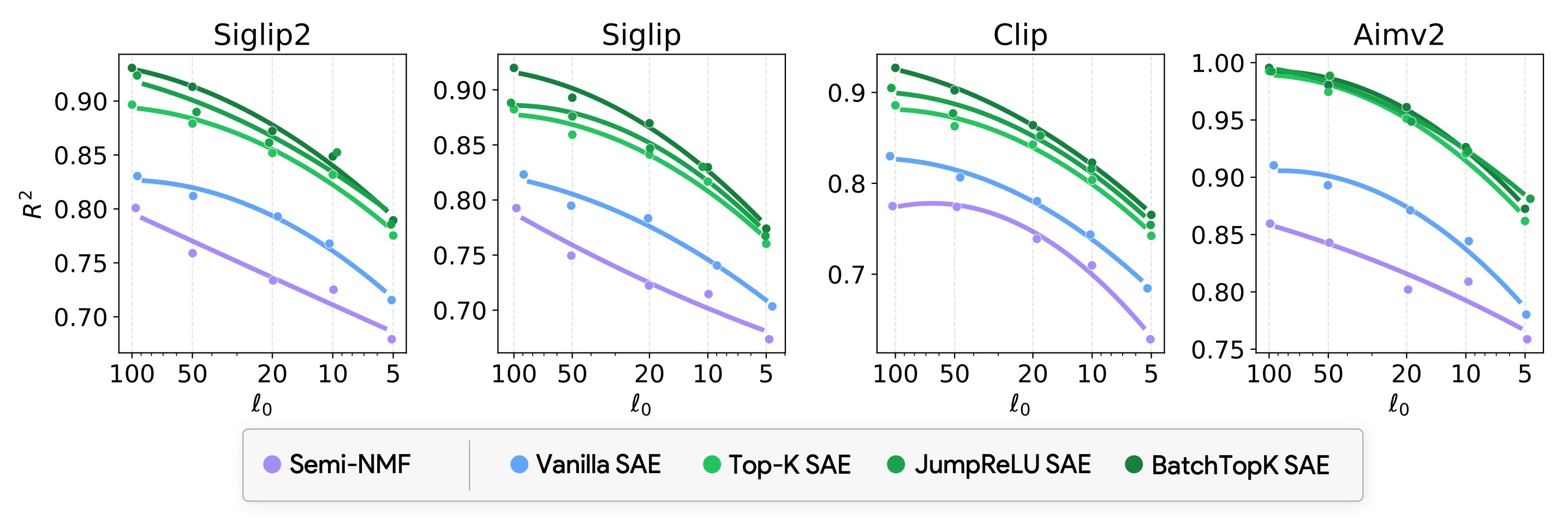
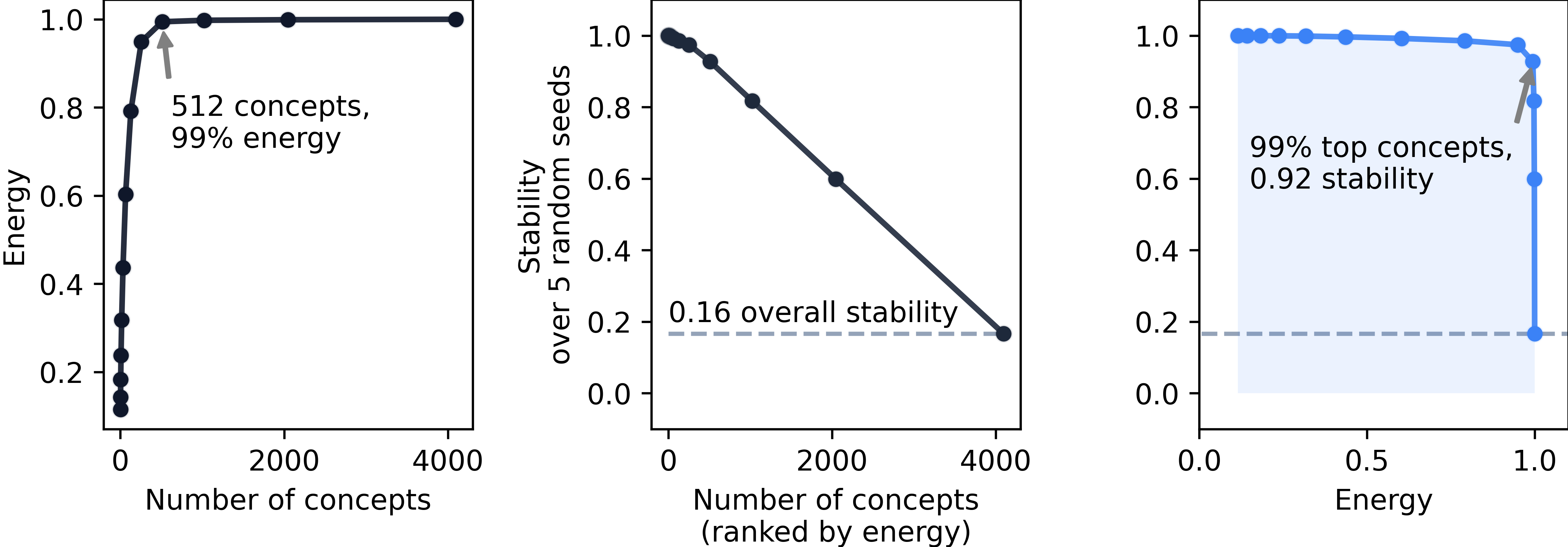
视觉-语言模型将图像和文本编码到一个联合空间中,最小化对应图像和文本对之间的距离。为了研究语言和图像在这个联合空间中是如何组织的,以及模型如何编码意义和模态,我们在四个视觉-语言模型(CLIP、SigLIP、SigLIP2和AIMv2)的嵌入空间上训练并发布了稀疏自编码器(SAE)。SAE将模型嵌入近似为学习到的方向(或“概念”)的稀疏线性组合。我们发现,与其他线性特征学习方法相比,SAE能够更好地重建真实嵌入,同时保持最大的稀疏性。使用不同的种子或不同的数据重新训练SAE导致两个发现:SAE捕获的罕见的、特定的概念容易发生剧烈变化,但我们也表明,常用的概念在多次运行中非常稳定。有趣的是,虽然大多数概念主要针对一种模态激活,但我们发现它们不仅仅是编码模态本身。许多概念几乎与定义模态的子空间正交,并且概念方向不能很好地用作模态分类器,这表明它们编码跨模态语义。为了量化这种桥接行为,我们引入了桥接分数,这是一种识别概念对的指标,这些概念对在对齐的图像-文本输入中共同激活,并且在共享空间中几何对齐。这表明,即使是单模态概念也可以协作以支持跨模态集成。我们发布了所有模型的SAE的交互式演示,允许研究人员探索概念空间的组织。总的来说,我们的发现揭示了VLM嵌入空间中由模态塑造的稀疏线性结构,但通过潜在的桥梁缝合在一起,为多模态意义的构建提供了新的见解。
🔬 方法详解
问题定义:现有视觉-语言模型(VLM)虽然在各种任务中表现出色,但其内部的嵌入空间如何组织,以及模型如何编码图像和文本的意义和模态信息,仍然是一个未解之谜。理解VLM的嵌入空间对于提高模型的可解释性、可控性和泛化能力至关重要。现有的线性特征学习方法可能无法充分捕捉VLM嵌入空间的复杂结构,并且缺乏对跨模态语义桥接的有效分析。
核心思路:论文的核心思路是利用稀疏自编码器(SAE)来学习VLM嵌入空间的稀疏线性表示。SAE通过学习一组基向量(或“概念”),将原始嵌入向量近似为这些基向量的稀疏线性组合。这种方法能够有效地提取嵌入空间中的重要特征,并揭示其潜在的结构。通过分析这些“概念”的激活模式和几何关系,可以深入了解VLM如何编码意义和模态信息。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择四个具有代表性的VLM模型(CLIP、SigLIP、SigLIP2和AIMv2);2) 提取这些模型的图像和文本嵌入;3) 在这些嵌入空间上训练稀疏自编码器(SAE);4) 分析SAE学习到的“概念”的激活模式、稳定性和跨模态语义桥接能力;5) 通过“桥接分数”量化概念对之间的跨模态关联;6) 提供交互式演示,方便研究人员探索概念空间。
关键创新:论文的关键创新点在于:1) 使用稀疏自编码器(SAE)来解析VLM嵌入空间的线性结构,这是一种有效的特征提取和表示学习方法;2) 提出了“桥接分数”这一指标,用于量化概念对之间的跨模态语义关联,从而揭示VLM如何实现跨模态信息集成;3) 发现VLM嵌入空间中存在由模态塑造的稀疏线性结构,但通过潜在的桥梁缝合在一起,为多模态意义的构建提供了新的见解。
关键设计:SAE的训练目标是最小化重构误差,同时鼓励稀疏性。具体的损失函数通常包含一个重构损失项(例如均方误差)和一个稀疏性惩罚项(例如L1正则化)。稀疏性惩罚项控制了激活的“概念”的数量,从而保证了表示的稀疏性。论文中可能还涉及了对SAE的超参数(例如隐藏层大小、稀疏性惩罚系数)的调整,以获得最佳的性能。此外,桥接分数的计算可能涉及对概念激活模式和几何关系的分析,例如计算概念向量之间的余弦相似度。
🖼️ 关键图片
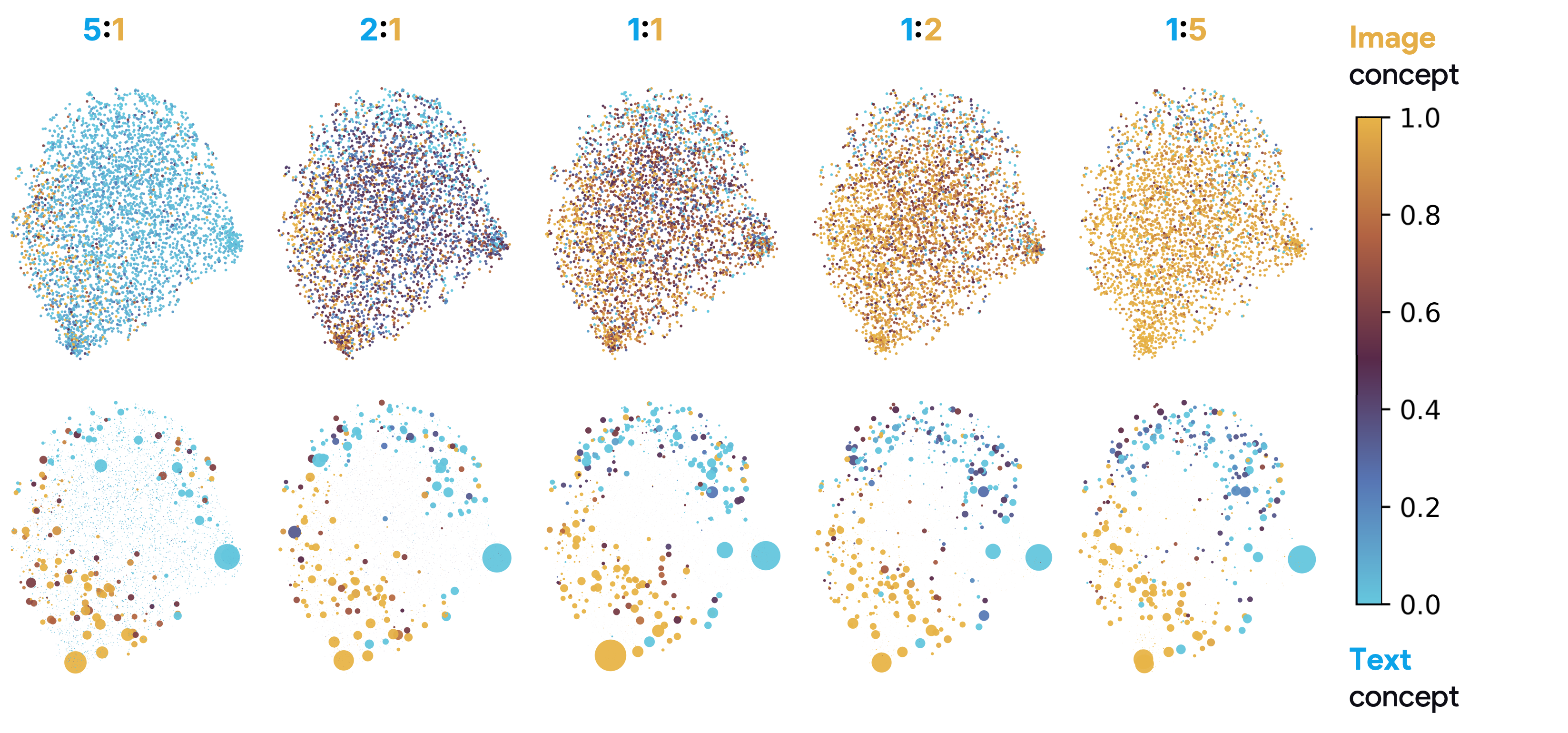
📊 实验亮点
实验结果表明,SAE能够有效地重建VLM的嵌入,并揭示其潜在的线性结构。研究发现,常用的概念在多次训练中表现出很高的稳定性,而罕见的、特定的概念则容易发生变化。此外,研究还发现,许多概念编码跨模态语义,并通过“桥接分数”量化了概念对之间的跨模态关联。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型的理解能力和可解释性,例如通过识别和操控关键概念来改善模型的生成效果或纠正模型的错误行为。此外,该方法还可以用于分析不同VLM模型的差异,从而指导模型设计和选择。该研究对于开发更可靠、更可控的多模态人工智能系统具有重要意义。
📄 摘要(原文)
Vision-language models encode images and text in a joint space, minimizing the distance between corresponding image and text pairs. How are language and images organized in this joint space, and how do the models encode meaning and modality? To investigate this, we train and release sparse autoencoders (SAEs) on the embedding spaces of four vision-language models (CLIP, SigLIP, SigLIP2, and AIMv2). SAEs approximate model embeddings as sparse linear combinations of learned directions, or "concepts". We find that, compared to other methods of linear feature learning, SAEs are better at reconstructing the real embeddings, while also able to retain the most sparsity. Retraining SAEs with different seeds or different data diet leads to two findings: the rare, specific concepts captured by the SAEs are liable to change drastically, but we also show that commonly-activating concepts are remarkably stable across runs. Interestingly, while most concepts activate primarily for one modality, we find they are not merely encoding modality per se. Many are almost orthogonal to the subspace that defines modality, and the concept directions do not function as good modality classifiers, suggesting that they encode cross-modal semantics. To quantify this bridging behavior, we introduce the Bridge Score, a metric that identifies concept pairs which are both co-activated across aligned image-text inputs and geometrically aligned in the shared space. This reveals that even single-modality concepts can collaborate to support cross-modal integration. We release interactive demos of the SAEs for all models, allowing researchers to explore the organization of the concept spaces. Overall, our findings uncover a sparse linear structure within VLM embedding spaces that is shaped by modality, yet stitched together through latent bridges, offering new insight into how multimodal meaning is constructed.