H-MoRe: Learning Human-centric Motion Representation for Action Analysis
作者: Zhanbo Huang, Xiaoming Liu, Yu Kong
分类: cs.CV
发布日期: 2025-04-14
备注: 15 pages, 14 figures, 7 tables, accepted to CVPR 2025 (Highlight)
💡 一句话要点
提出H-MoRe,学习以人为中心的运动表征,用于动作分析。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人体运动表征 自监督学习 动作分析 步态识别 动作识别 视频生成 世界-局部流
📋 核心要点
- 现有方法依赖合成数据进行全监督学习,难以适应真实场景的复杂性和多样性。
- H-MoRe通过自监督学习,直接从真实场景中提取人体姿态和体型信息,学习精确的运动表征。
- 实验表明,H-MoRe在步态识别、动作识别和视频生成等任务上取得了显著的性能提升。
📝 摘要(中文)
本文提出了一种新颖的H-MoRe流程,用于学习精确的以人为中心的运动表征。我们的方法动态地保留相关的身体运动,同时过滤掉背景运动。值得注意的是,与之前依赖于合成数据进行全监督学习的方法不同,H-MoRe以自监督的方式直接从真实场景中学习,融合了人体姿态和体型信息。受到运动学的启发,H-MoRe以矩阵格式表示每个身体点的绝对和相对运动,捕捉细微的运动细节,称为世界-局部流。H-MoRe提供了对人体运动的精细洞察,可以无缝集成到各种与动作相关的应用中。实验结果表明,H-MoRe在各种下游任务中带来了显著的改进,包括步态识别(CL@R1: +16.01%)、动作识别(Acc@1: +8.92%)和视频生成(FVD: -67.07%)。此外,H-MoRe具有很高的推理效率(34 fps),使其适用于大多数实时场景。模型和代码将在发表后发布。
🔬 方法详解
问题定义:现有动作分析方法通常依赖于全监督学习,需要大量标注数据,且在合成数据上训练的模型泛化能力有限。这些方法难以有效区分人体运动与背景干扰,无法精确捕捉细微的运动信息。因此,如何从真实场景中自监督地学习鲁棒且精细的人体运动表征是一个关键问题。
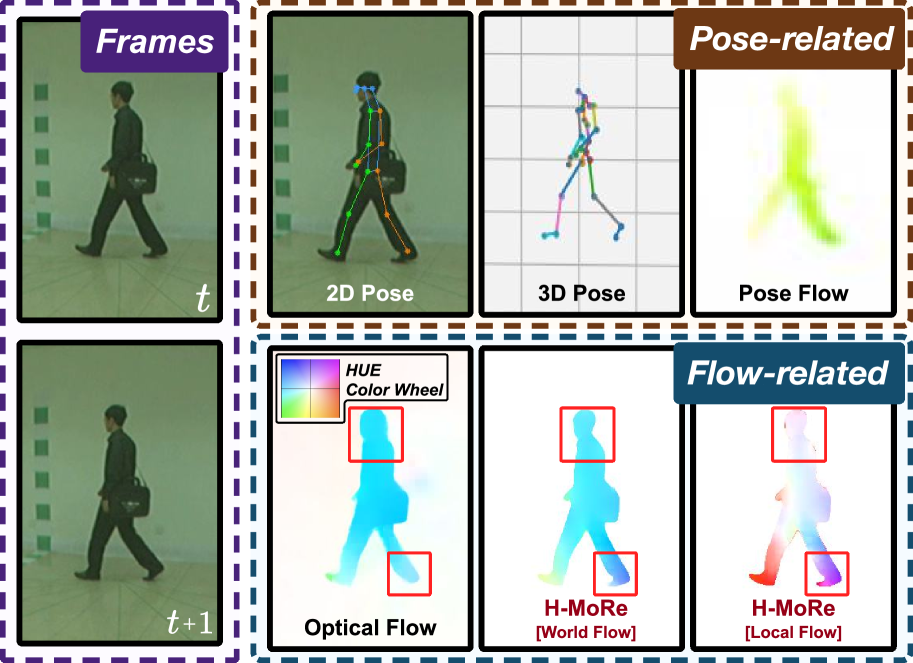
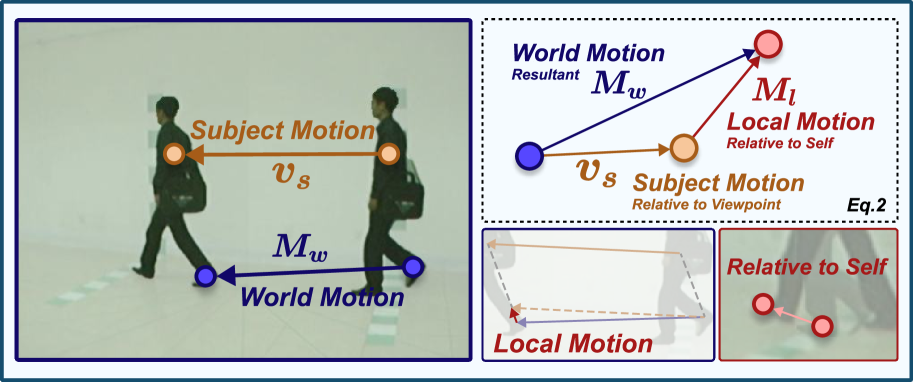
核心思路:H-MoRe的核心思路是利用自监督学习,直接从真实世界的视频中学习人体运动表征。它借鉴运动学原理,将人体运动分解为绝对运动和相对运动,并使用世界-局部流(world-local flows)来表示这些运动。通过这种方式,H-MoRe能够捕捉到细微的运动细节,并有效过滤掉背景干扰。
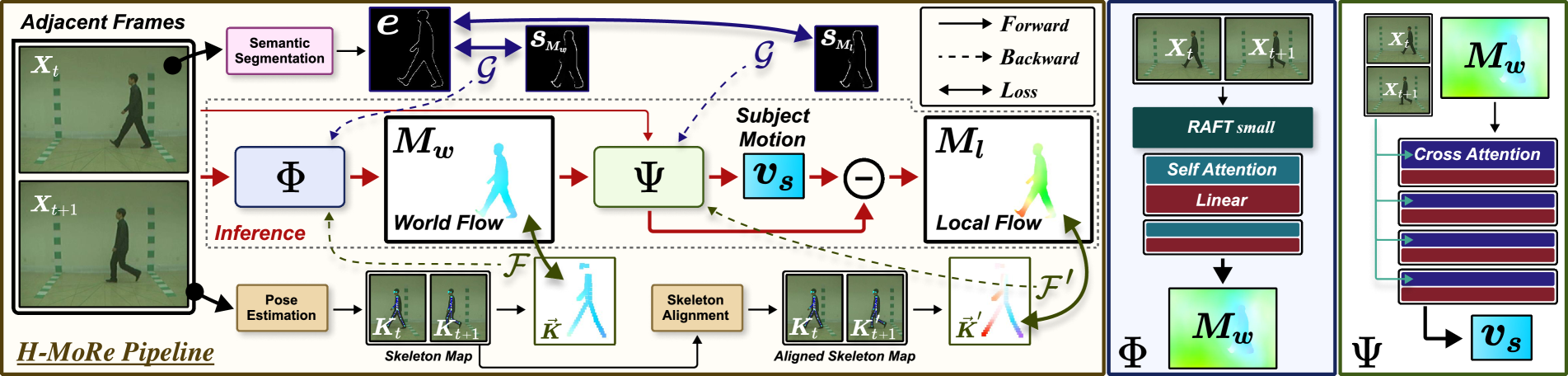
技术框架:H-MoRe的整体框架包含以下几个主要模块:1) 人体姿态和体型估计模块,用于提取视频中每一帧的人体姿态和体型信息;2) 世界-局部流计算模块,用于计算每个身体点的绝对运动和相对运动,并将其表示为世界-局部流;3) 自监督学习模块,用于训练模型,使其能够从世界-局部流中学习到鲁棒的人体运动表征。该模块使用对比学习等技术,鼓励模型学习到区分不同动作的特征。
关键创新:H-MoRe最重要的创新点在于其自监督学习方法和世界-局部流的表示方式。与现有方法相比,H-MoRe无需依赖合成数据进行全监督学习,而是直接从真实场景中学习,从而提高了模型的泛化能力。世界-局部流能够有效地捕捉细微的运动细节,并过滤掉背景干扰,从而提高了运动表征的精度。
关键设计:H-MoRe的关键设计包括:1) 使用预训练的人体姿态和体型估计模型,以提高姿态估计的准确性;2) 设计了特定的损失函数,用于优化自监督学习过程,例如对比损失和运动一致性损失;3) 世界-局部流的计算方式,通过矩阵运算高效地表示绝对和相对运动。
🖼️ 关键图片
📊 实验亮点
H-MoRe在多个下游任务上取得了显著的性能提升。在步态识别任务中,CL@R1指标提升了16.01%;在动作识别任务中,Acc@1指标提升了8.92%;在视频生成任务中,FVD指标降低了67.07%。此外,H-MoRe还具有较高的推理效率,达到34 fps,使其适用于实时应用场景。这些结果表明,H-MoRe能够有效地学习到鲁棒且精细的人体运动表征。
🎯 应用场景
H-MoRe在多个领域具有广泛的应用前景,包括:安全监控(异常行为检测)、智能家居(手势识别与控制)、人机交互(自然动作理解)、医疗健康(步态分析与康复评估)以及虚拟现实/增强现实(逼真的人物动画生成)。该研究能够提升相关系统的智能化水平和用户体验,具有重要的实际应用价值。
📄 摘要(原文)
In this paper, we propose H-MoRe, a novel pipeline for learning precise human-centric motion representation. Our approach dynamically preserves relevant human motion while filtering out background movement. Notably, unlike previous methods relying on fully supervised learning from synthetic data, H-MoRe learns directly from real-world scenarios in a self-supervised manner, incorporating both human pose and body shape information. Inspired by kinematics, H-MoRe represents absolute and relative movements of each body point in a matrix format that captures nuanced motion details, termed world-local flows. H-MoRe offers refined insights into human motion, which can be integrated seamlessly into various action-related applications. Experimental results demonstrate that H-MoRe brings substantial improvements across various downstream tasks, including gait recognition(CL@R1: +16.01%), action recognition(Acc@1: +8.92%), and video generation(FVD: -67.07%). Additionally, H-MoRe exhibits high inference efficiency (34 fps), making it suitable for most real-time scenarios. Models and code will be released upon publication.