AgMMU: A Comprehensive Agricultural Multimodal Understanding Benchmark
作者: Aruna Gauba, Irene Pi, Yunze Man, Ziqi Pang, Vikram S. Adve, Yu-Xiong Wang
分类: cs.CV
发布日期: 2025-04-14 (更新: 2025-07-24)
备注: Project Website: https://agmmu.github.io/ Huggingface: https://huggingface.co/datasets/AgMMU/AgMMU_v1/
💡 一句话要点
提出AgMMU农业多模态理解基准,用于评估和提升视觉-语言模型在农业领域的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 农业AI 多模态理解 视觉-语言模型 知识库 基准数据集
📋 核心要点
- 现有农业领域数据集依赖众包,缺乏真实性和专业性,限制了VLM在该领域的应用。
- AgMMU通过从真实农业专家对话中提取知识,构建高质量的多模态问答数据集和知识库。
- 实验表明,现有VLM在AgMMU上表现不佳,但在AgBase上微调后性能显著提升,验证了数据集的价值。
📝 摘要(中文)
本文提出了AgMMU,一个具有挑战性的真实世界基准,用于评估和提升视觉-语言模型(VLMs)在知识密集的农业领域的性能。与依赖众包提示的先前数据集不同,AgMMU是从日常种植者和美国农业部授权的合作推广专家之间116,231个真实对话中提炼出来的。通过一个三阶段的流程:自动知识提取、问答生成和人工验证,我们构建了(i)AgMMU,一个包含746个多项选择题(MCQs)和746个开放式问题(OEQs)的评估集,以及(ii)AgBase,一个包含57,079个多模态事实的开发语料库,涵盖五个高风险农业主题:昆虫识别、物种识别、疾病分类、症状描述和管理指导。对12个领先的VLMs进行基准测试,揭示了在细粒度感知和事实基础方面的明显差距。开源模型在性能上远远落后于专有模型。在AgBase上进行简单的微调,可使开源模型在具有挑战性的OEQ上的性能平均提高高达11.6%,缩小了这一差距,并激发了未来的研究,以提出更好的知识提取和从AgBase中提炼的策略。我们希望AgMMU能够促进农业AI开发中特定领域知识集成和可信赖决策支持方面的研究。
🔬 方法详解
问题定义:现有农业领域的多模态数据集通常依赖于众包生成,这些数据可能缺乏真实性和专业性,无法充分评估和提升视觉-语言模型(VLM)在农业领域的知识理解能力。因此,需要一个更贴近实际应用场景、包含专业知识的高质量农业多模态数据集,以推动农业AI的发展。
核心思路:本文的核心思路是从真实的农业专家和种植者之间的对话中提取知识,构建一个高质量的多模态问答数据集(AgMMU)和一个知识库(AgBase)。通过这种方式,可以确保数据集的真实性和专业性,并能够更好地评估VLM在农业领域的知识理解能力。
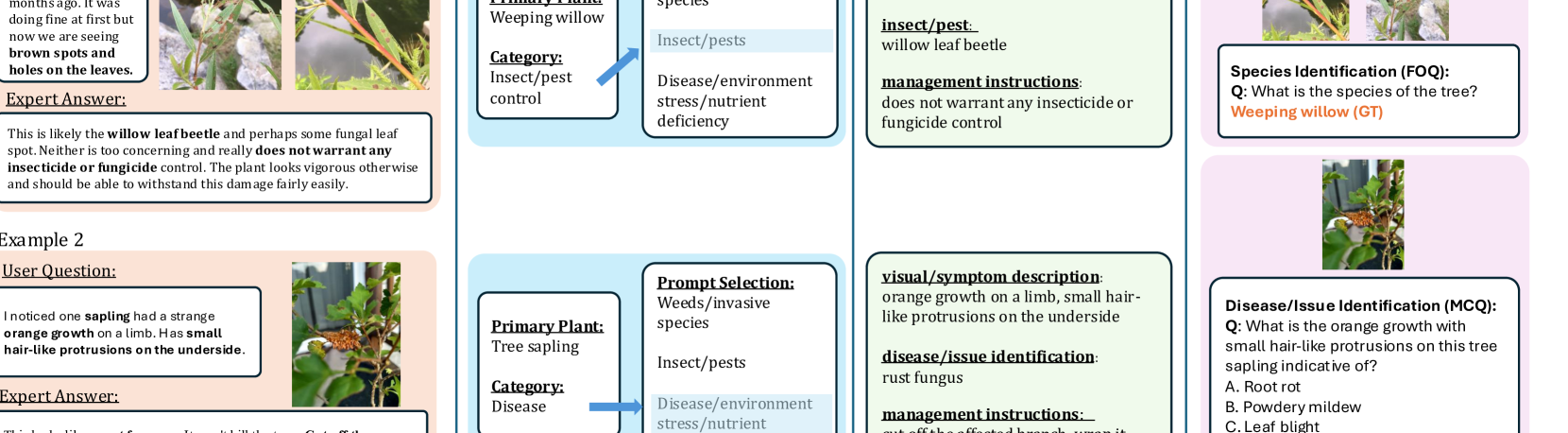
技术框架:AgMMU的构建流程主要包含三个阶段:1) 自动知识提取:从农业专家和种植者的对话中自动提取知识,形成候选知识条目。2) 问答生成:基于提取的知识条目,自动生成多项选择题(MCQs)和开放式问题(OEQs)。3) 人工验证:对生成的问答进行人工审核和验证,确保其质量和准确性。AgBase的构建则主要依赖于自动知识提取阶段的结果,并进行整理和归纳。
关键创新:AgMMU的关键创新在于其数据来源的真实性和专业性。与以往依赖众包的数据集不同,AgMMU的数据来源于真实的农业专家和种植者之间的对话,这保证了数据集的质量和专业性。此外,AgMMU还提供了一个包含多模态事实的知识库(AgBase),可以用于进一步的研究和应用。
关键设计:在自动知识提取阶段,使用了自然语言处理技术,例如命名实体识别、关系抽取等,从对话文本中提取关键信息。在问答生成阶段,设计了多种模板和规则,以生成不同类型的问答。在人工验证阶段,聘请了农业领域的专家对生成的问答进行审核,确保其准确性和合理性。
🖼️ 关键图片

📊 实验亮点
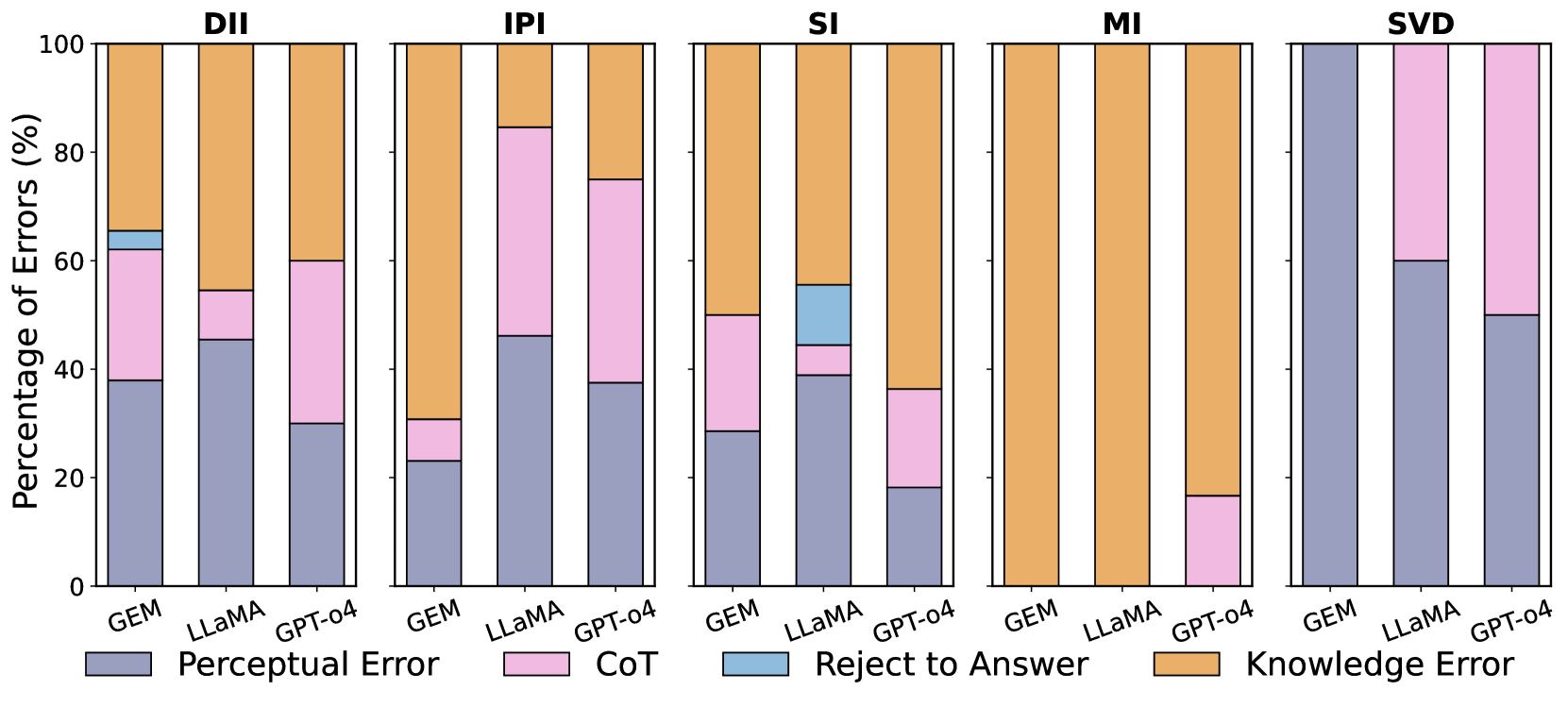
在AgMMU基准测试中,开源VLM的性能显著低于专有模型,表明领域知识的缺乏是制约其性能的关键因素。通过在AgBase上进行微调,开源模型在开放式问题上的性能平均提升了11.6%,有效缩小了与专有模型的差距,验证了AgBase的有效性。
🎯 应用场景
AgMMU可用于训练和评估农业领域的AI模型,例如病虫害识别、作物诊断和智能农业咨询系统。该数据集能够帮助农民快速准确地获取农业知识,提高农业生产效率,并促进农业可持续发展。未来,AgMMU可以扩展到更多农业领域,并与其他农业数据源集成,构建更全面的农业知识图谱。
📄 摘要(原文)
We present AgMMU, a challenging real-world benchmark for evaluating and advancing vision-language models (VLMs) in the knowledge-intensive domain of agriculture. Unlike prior datasets that rely on crowdsourced prompts, AgMMU is distilled from 116,231 authentic dialogues between everyday growers and USDA-authorized Cooperative Extension experts. Through a three-stage pipeline: automated knowledge extraction, QA generation, and human verification, we construct (i) AgMMU, an evaluation set of 746 multiple-choice questions (MCQs) and 746 open-ended questions (OEQs), and (ii) AgBase, a development corpus of 57,079 multimodal facts covering five high-stakes agricultural topics: insect identification, species identification, disease categorization, symptom description, and management instruction. Benchmarking 12 leading VLMs reveals pronounced gaps in fine-grained perception and factual grounding. Open-sourced models trail after proprietary ones by a wide margin. Simple fine-tuning on AgBase boosts open-sourced model performance on challenging OEQs for up to 11.6% on average, narrowing this gap and also motivating future research to propose better strategies in knowledge extraction and distillation from AgBase. We hope AgMMU stimulates research on domain-specific knowledge integration and trustworthy decision support in agriculture AI development.