GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
作者: Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, Xiaobo Xia
分类: cs.CV, cs.CL, cs.HC
发布日期: 2025-04-14 (更新: 2025-10-01)
💡 一句话要点
GUI-R1:面向GUI代理的通用R1风格视觉-语言-动作模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI代理 视觉-语言模型 强化学习 统一动作空间 策略优化 跨平台 自动化
📋 核心要点
- 现有GUI代理依赖大量数据进行监督微调,泛化能力差,难以应对真实场景的高级任务。
- GUI-R1采用强化学习框架,通过统一动作空间规则建模,提升LVLM的GUI能力。
- 实验表明,GUI-R1仅用少量数据,在多个平台和基准测试中超越了现有最佳方法。
📝 摘要(中文)
现有的构建图形用户界面(GUI)代理的工作主要依赖于在大型视觉-语言模型(LVLM)上进行监督微调的训练范式。然而,这种方法不仅需要大量的训练数据,而且难以有效地理解GUI截图并泛化到未见过的界面。这个问题严重限制了其在实际场景中的应用,尤其是在高层次任务中。受到大型推理模型(例如,DeepSeek-R1)中强化微调(RFT)的启发,RFT有效地增强了大型语言模型在实际环境中的问题解决能力,我们提出了GUI-R1,这是第一个强化学习框架,旨在通过统一的动作空间规则建模来增强LVLM在实际高层次任务场景中的GUI能力。通过利用少量精心策划的跨多个平台(包括Windows、Linux、MacOS、Android和Web)的高质量数据,并采用诸如Group Relative Policy Optimization(GRPO)等策略优化算法来更新模型,GUI-R1仅使用0.02%的数据(3K vs. 13M)就实现了优于先前最先进方法(如OS-Atlas)的性能,涵盖了跨三个不同平台(移动、桌面和Web)的八个基准。这些结果证明了基于统一动作空间规则建模的强化学习在提高LVLM执行实际GUI代理任务能力方面的巨大潜力。
🔬 方法详解
问题定义:现有GUI代理构建方法依赖于大量标注数据进行监督微调,导致模型泛化能力不足,难以适应真实世界中复杂多变的GUI界面。尤其是在高层次任务中,模型难以有效理解GUI截图并做出正确的动作决策,严重限制了其应用。
核心思路:GUI-R1借鉴了强化微调(RFT)在提升大型语言模型推理能力方面的成功经验,将强化学习引入GUI代理的训练中。核心思路是通过奖励机制引导模型学习如何在不同的GUI环境中执行任务,从而提高模型的泛化能力和任务完成率。统一动作空间规则建模是关键,它使得模型能够处理来自不同平台的GUI。
技术框架:GUI-R1的整体框架包括以下几个主要模块:1) 视觉-语言模型(LVLM):作为基础模型,负责处理GUI截图和任务描述,并生成动作序列。2) 统一动作空间:定义了一套通用的GUI动作规则,使得模型可以在不同的平台上执行相同的动作。3) 强化学习模块:使用策略优化算法(如GRPO)更新LVLM的策略,使其能够更好地完成任务。4) 奖励函数:根据模型执行动作的结果,给予相应的奖励或惩罚,引导模型学习最优策略。
关键创新:GUI-R1的关键创新在于将强化学习与统一动作空间规则建模相结合,用于提升LVLM在GUI代理任务中的性能。与传统的监督学习方法相比,GUI-R1能够利用少量数据学习到更强的泛化能力。此外,统一动作空间的设计使得模型可以跨平台工作,大大提高了其适用性。
关键设计:GUI-R1的关键设计包括:1) 精心策划的高质量数据集:包含来自多个平台(Windows、Linux、MacOS、Android和Web)的GUI截图和任务描述。2) Group Relative Policy Optimization (GRPO) 算法:用于优化LVLM的策略,提高其任务完成率。3) 奖励函数的设计:根据任务的完成情况,给予模型相应的奖励或惩罚。例如,如果模型成功完成任务,则给予正向奖励;如果模型执行了无效动作或未能完成任务,则给予负向奖励。
🖼️ 关键图片
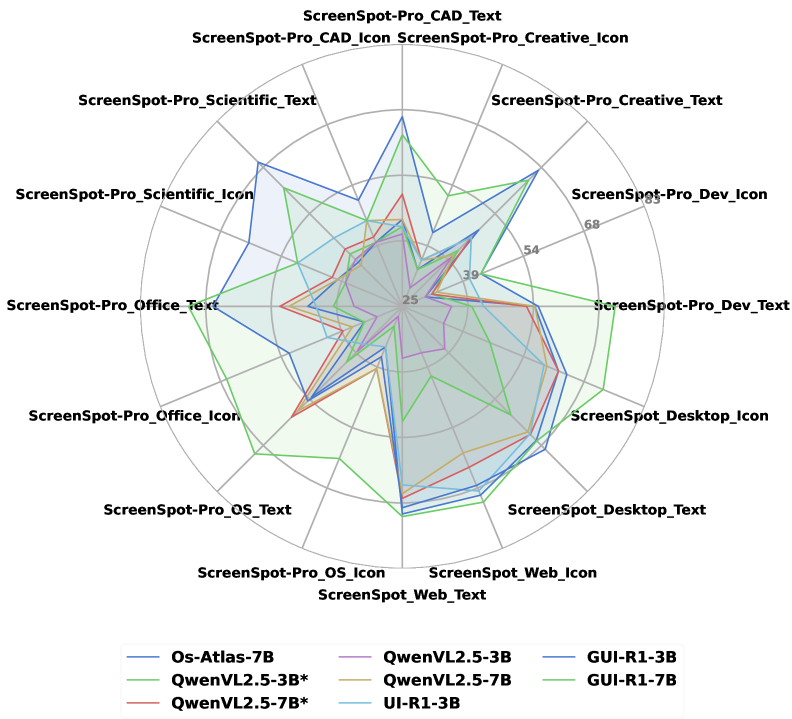
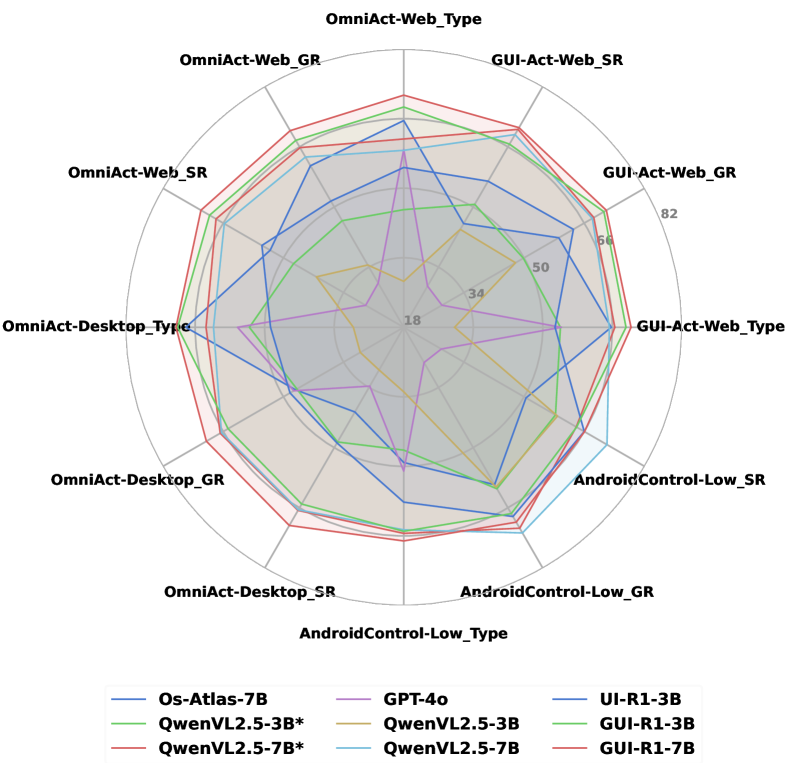
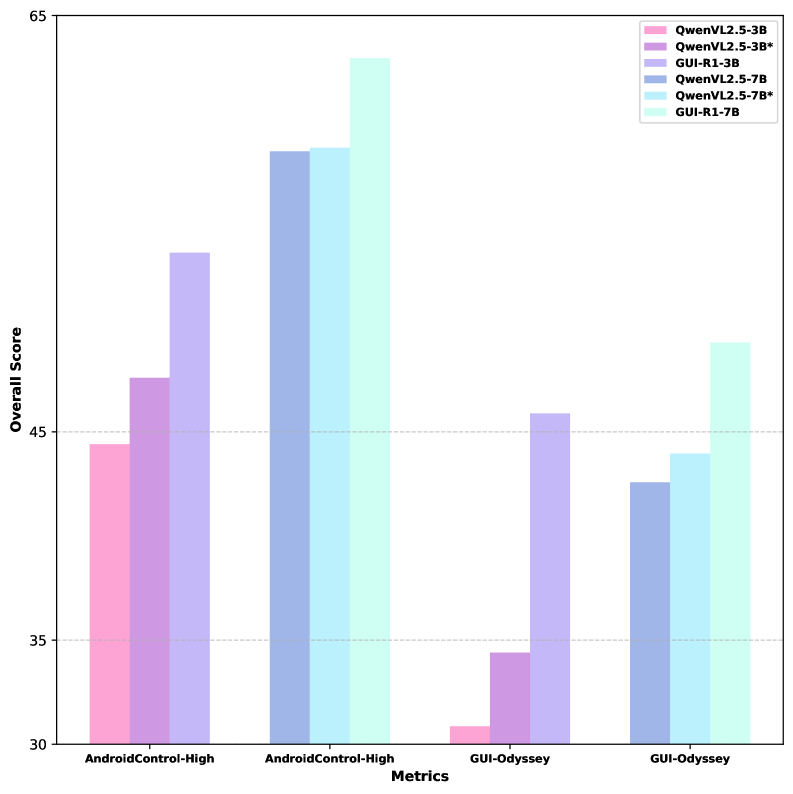
📊 实验亮点
GUI-R1在八个基准测试中,跨移动、桌面和Web三个平台,仅使用OS-Atlas 0.02% 的数据(3K vs. 13M),就超越了OS-Atlas等现有最佳方法。这证明了基于统一动作空间规则建模的强化学习在提升LVLM执行实际GUI代理任务能力方面的巨大潜力。
🎯 应用场景
GUI-R1具有广泛的应用前景,可用于开发智能自动化工具,例如自动化测试、RPA(机器人流程自动化)和智能助手。它可以帮助用户自动完成重复性的GUI操作,提高工作效率。此外,GUI-R1还可以应用于辅助残疾人使用计算机,例如通过语音控制GUI界面。
📄 摘要(原文)
Existing efforts in building Graphical User Interface (GUI) agents largely rely on the training paradigm of supervised fine-tuning on Large Vision-Language Models (LVLMs). However, this approach not only demands extensive amounts of training data but also struggles to effectively understand GUI screenshots and generalize to unseen interfaces. The issue significantly limits its application in real-world scenarios, especially for high-level tasks. Inspired by Reinforcement Fine-Tuning (RFT) in large reasoning models (e.g., DeepSeek-R1), which efficiently enhances the problem-solving capabilities of large language models in real-world settings, we propose \name, the first reinforcement learning framework designed to enhance the GUI capabilities of LVLMs in high-level real-world task scenarios, through unified action space rule modeling. By leveraging a small amount of carefully curated high-quality data across multiple platforms (including Windows, Linux, MacOS, Android, and Web) and employing policy optimization algorithms such as Group Relative Policy Optimization (GRPO) to update the model, \name achieves superior performance using only 0.02\% of the data (3K vs. 13M) compared to previous state-of-the-art methods like OS-Atlas across eight benchmarks spanning three different platforms (mobile, desktop, and web). These results demonstrate the immense potential of reinforcement learning based on unified action space rule modeling in improving the execution capabilities of LVLMs for real-world GUI agent tasks.