Integrating Vision and Location with Transformers: A Multimodal Deep Learning Framework for Medical Wound Analysis
作者: Ramin Mousa, Hadis Taherinia, Khabiba Abdiyeva, Amir Ali Bengari, Mohammadmahdi Vahediahmar
分类: cs.CV
发布日期: 2025-04-14
💡 一句话要点
提出基于Transformer的多模态深度学习框架,用于医学伤口图像的分类与定位分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 伤口诊断 多模态学习 Vision Transformer 离散小波变换 群体智能优化 医学图像分析 深度学习
📋 核心要点
- 传统机器学习模型在伤口诊断中存在特征选择困难和模型复杂等问题,限制了准确识别。
- 论文提出结合Vision Transformer、DWT和小波变换的多模态深度学习框架,融合图像和位置信息进行伤口分类。
- 实验结果表明,通过群体智能优化算法优化模型权重,能够有效提升伤口诊断的准确率。
📝 摘要(中文)
本研究提出了一种基于深度学习的多模态分类器,用于伤口图像的分类,并结合伤口位置信息,将伤口分为糖尿病溃疡、压疮、手术伤口和静脉溃疡等多种类型。该模型利用Vision Transformer从输入图像中提取分层特征,使用离散小波变换(DWT)层捕获低频和高频分量,并使用Transformer提取空间特征。此外,还创建了一个身体地图以提供位置数据,帮助伤口专家更有效地标记伤口位置。通过三种基于群体智能的优化技术(Monster Gorilla Toner (MGTO), Improved Gray Wolf Optimization (IGWO), and Fox Optimization Algorithm)优化神经元数量和权重向量。评估结果表明,使用优化算法优化权重向量可以提高诊断准确率。在使用原始身体地图进行分类时,该模型使用图像数据实现了0.8123的准确率,结合图像数据和伤口位置信息实现了0.8007的准确率。结合优化模型后,模型的准确率在0.7801到0.8342之间变化。
🔬 方法详解
问题定义:现有伤口诊断方法依赖人工特征提取,效率低且易出错。深度学习方法虽有潜力,但仍需提升效率和准确性。本研究旨在解决伤口类型自动分类问题,并结合伤口位置信息,辅助医生进行更精确的诊断。
核心思路:论文的核心思路是将伤口图像的视觉特征与伤口的位置信息相结合,利用多模态深度学习模型进行分类。通过Transformer架构提取图像和位置信息的有效特征,并利用优化算法提升模型性能。
技术框架:该模型包含以下主要模块:1) Vision Transformer:从伤口图像中提取分层视觉特征。2) 离散小波变换(DWT)层:捕获图像的低频和高频信息,增强特征表达。3) Transformer:提取伤口位置的空间特征。4) 分类器:基于提取的特征进行伤口类型分类。5) 优化算法:使用群体智能优化算法优化模型参数。
关键创新:该研究的关键创新在于:1) 结合Vision Transformer和DWT提取图像特征,增强特征表达能力。2) 融合图像和位置信息,利用多模态学习提升分类准确率。3) 使用群体智能优化算法优化模型参数,进一步提升模型性能。与现有方法相比,该方法能够更有效地利用图像和位置信息,实现更准确的伤口分类。
关键设计:Vision Transformer采用标准Transformer结构,DWT层使用haar小波基。位置信息通过身体地图编码,并输入到Transformer中。损失函数采用交叉熵损失。优化算法包括Monster Gorilla Toner (MGTO), Improved Gray Wolf Optimization (IGWO), and Fox Optimization Algorithm,用于优化神经元数量和权重向量。
🖼️ 关键图片

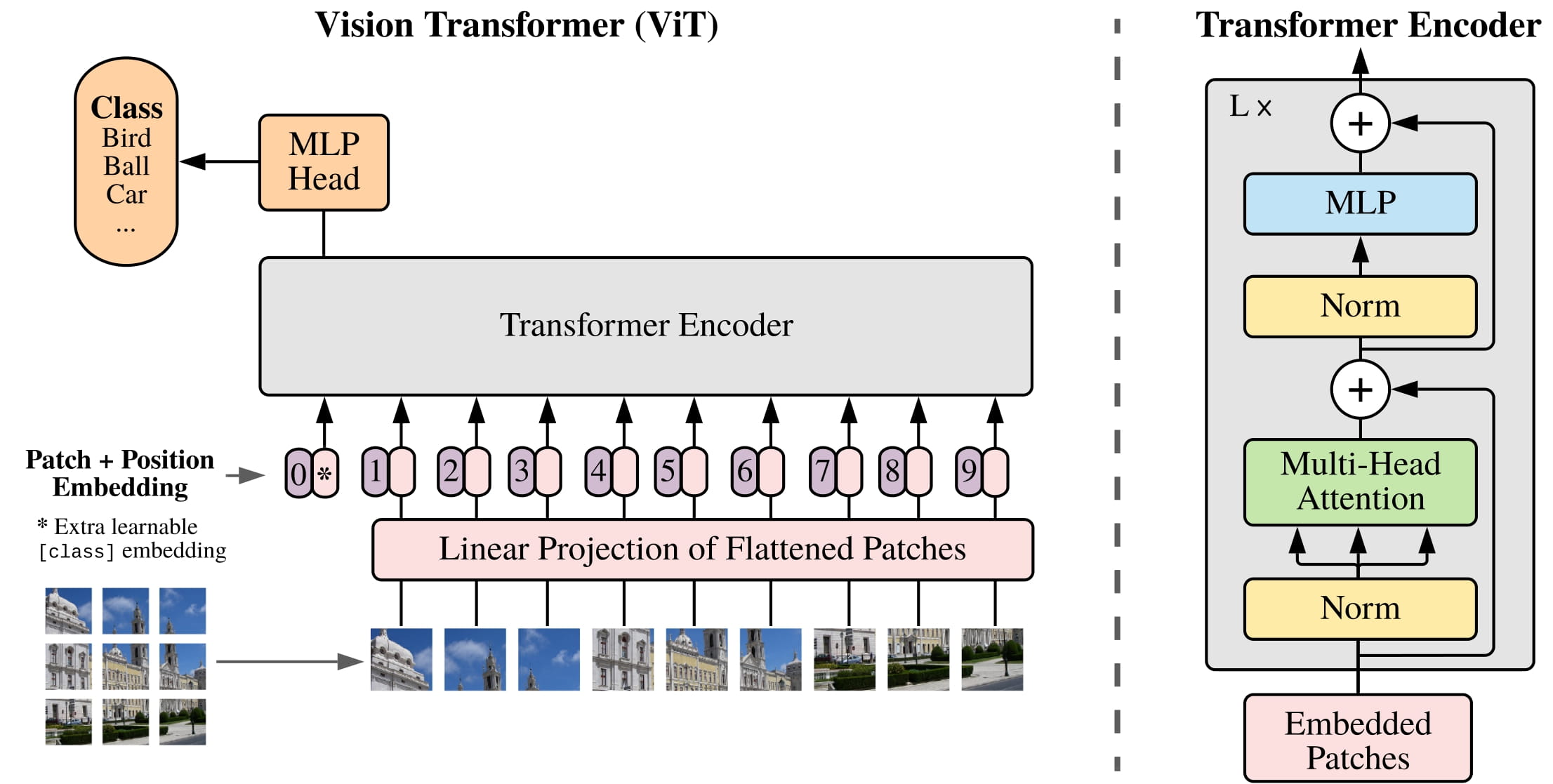
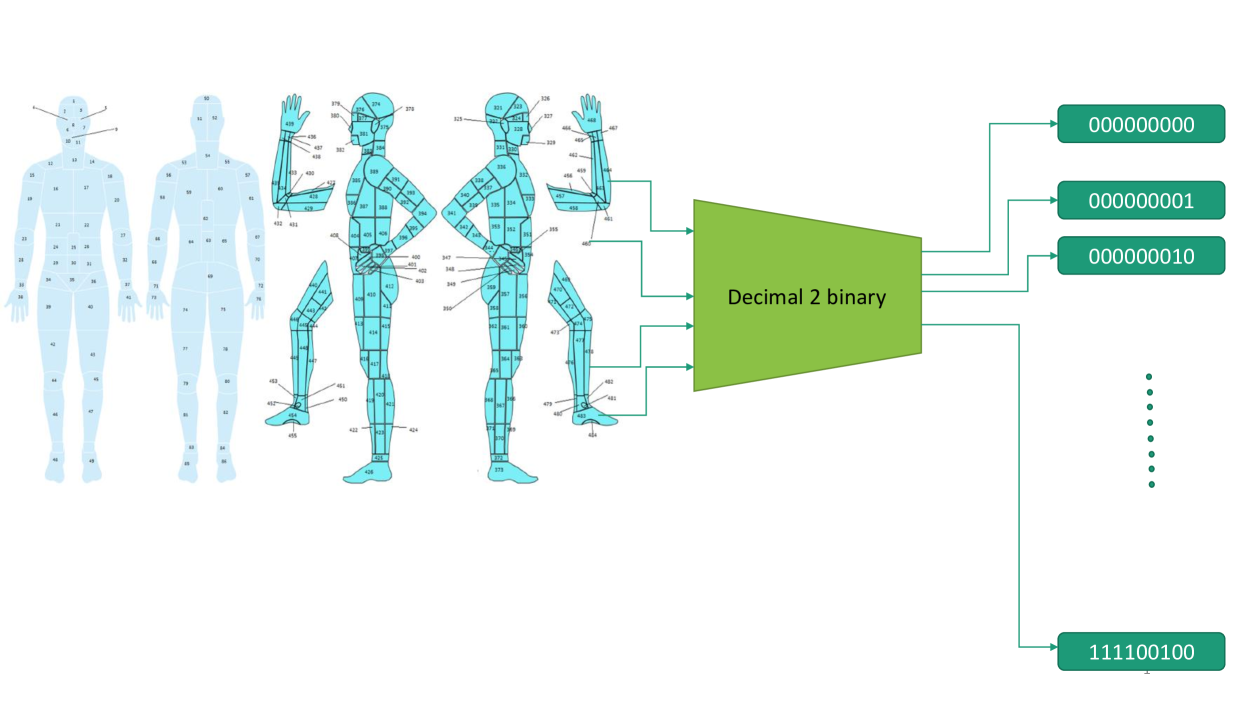
📊 实验亮点
实验结果表明,该模型在使用原始身体地图进行分类时,使用图像数据实现了0.8123的准确率,结合图像数据和伤口位置信息实现了0.8007的准确率。结合优化模型后,模型的准确率在0.7801到0.8342之间变化。这些结果表明,结合图像和位置信息,并使用优化算法可以有效提升伤口分类的准确率。
🎯 应用场景
该研究成果可应用于医疗辅助诊断系统,帮助医生更快速、准确地诊断伤口类型,制定更优的治疗方案。通过自动化的伤口分类和定位,可以降低医疗成本,提高诊断效率,并为远程医疗提供技术支持。未来,该技术有望扩展到其他医学图像分析领域,例如皮肤病诊断等。
📄 摘要(原文)
Effective recognition of acute and difficult-to-heal wounds is a necessary step in wound diagnosis. An efficient classification model can help wound specialists classify wound types with less financial and time costs and also help in deciding on the optimal treatment method. Traditional machine learning models suffer from feature selection and are usually cumbersome models for accurate recognition. Recently, deep learning (DL) has emerged as a powerful tool in wound diagnosis. Although DL seems promising for wound type recognition, there is still a large scope for improving the efficiency and accuracy of the model. In this study, a DL-based multimodal classifier was developed using wound images and their corresponding locations to classify them into multiple classes, including diabetic, pressure, surgical, and venous ulcers. A body map was also created to provide location data, which can help wound specialists label wound locations more effectively. The model uses a Vision Transformer to extract hierarchical features from input images, a Discrete Wavelet Transform (DWT) layer to capture low and high frequency components, and a Transformer to extract spatial features. The number of neurons and weight vector optimization were performed using three swarm-based optimization techniques (Monster Gorilla Toner (MGTO), Improved Gray Wolf Optimization (IGWO), and Fox Optimization Algorithm). The evaluation results show that weight vector optimization using optimization algorithms can increase diagnostic accuracy and make it a very effective approach for wound detection. In the classification using the original body map, the proposed model was able to achieve an accuracy of 0.8123 using image data and an accuracy of 0.8007 using a combination of image data and wound location. Also, the accuracy of the model in combination with the optimization models varied from 0.7801 to 0.8342.