HUMOTO: A 4D Dataset of Mocap Human Object Interactions
作者: Jiaxin Lu, Chun-Hao Paul Huang, Uttaran Bhattacharya, Qixing Huang, Yi Zhou
分类: cs.CV
发布日期: 2025-04-14 (更新: 2025-10-15)
备注: ICCV 2025, 19 pages, 15 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
HUMOTO:用于动作生成和人机交互研究的高质量4D人体-物体交互数据集
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体-物体交互 动作捕捉 数据集 动作生成 机器人 具身智能 LLM 4D数据
📋 核心要点
- 现有人体-物体交互数据集在规模、质量和交互复杂性方面存在不足,限制了相关领域的研究进展。
- HUMOTO利用场景驱动的LLM脚本生成流程和优化的动作捕捉系统,创建了包含多种交互任务的高质量数据集。
- 该数据集经过专业清理和验证,并提供了与其他数据集的基准比较,为相关研究提供了可靠的数据基础。
📝 摘要(中文)
本文提出了Human Motions with Objects (HUMOTO),一个高保真的人体-物体交互数据集,用于动作生成、计算机视觉和机器人应用。HUMOTO包含735个序列(30fps下7875秒),捕捉了与63个精确建模的物体和72个可动部件的交互。该数据集的创新之处包括一个场景驱动的LLM脚本生成流程,用于创建完整、有目的且具有自然进展的任务,以及一个能够有效处理遮挡的动作捕捉和相机记录设置。HUMOTO涵盖了从烹饪到户外野餐等多种活动,既保证了物理准确性,又保证了逻辑任务流程。专业艺术家对每个序列进行严格的清理和验证,最大限度地减少了脚部滑动和物体穿透。此外,论文还提供了与其他数据集的基准比较。HUMOTO全面的全身运动和同步多物体交互解决了关键的数据捕获挑战,并为推进动画、机器人和具身AI系统中逼真的人体-物体交互建模提供了机会。
🔬 方法详解
问题定义:现有的人体-物体交互数据集通常规模较小,交互场景单一,难以覆盖真实世界中复杂的人机交互行为。此外,数据质量也参差不齐,存在脚部滑动、物体穿透等问题,影响了模型的训练效果。因此,需要一个大规模、高质量、多样化的人体-物体交互数据集,以推动相关领域的研究进展。
核心思路:HUMOTO的核心思路是利用场景驱动的LLM脚本生成流程,自动生成具有自然进展和逻辑任务流程的交互脚本。然后,通过优化的动作捕捉和相机记录系统,捕捉高质量的人体和物体运动数据。最后,由专业艺术家对数据进行清理和验证,确保数据的准确性和可靠性。
技术框架:HUMOTO的数据集构建流程主要包括以下几个阶段:1) 利用LLM生成场景驱动的交互脚本;2) 使用动作捕捉系统和多视角相机记录人体和物体的运动数据;3) 对原始数据进行处理,包括骨骼重建、物体姿态估计等;4) 由专业艺术家对数据进行清理和验证,消除脚部滑动、物体穿透等问题。
关键创新:HUMOTO的关键创新在于其场景驱动的LLM脚本生成流程。该流程能够自动生成具有自然进展和逻辑任务流程的交互脚本,从而避免了人工设计脚本的繁琐和主观性。此外,HUMOTO还采用了优化的动作捕捉和相机记录系统,能够有效处理遮挡问题,提高数据质量。
关键设计:HUMOTO使用了OptiTrack动作捕捉系统,配备了多个红外摄像头,能够精确捕捉人体和物体的运动轨迹。同时,使用了多个RGB相机,从不同角度记录场景图像,用于辅助骨骼重建和物体姿态估计。在数据清理和验证阶段,使用了专门的软件工具,能够自动检测和修复脚部滑动、物体穿透等问题。
🖼️ 关键图片
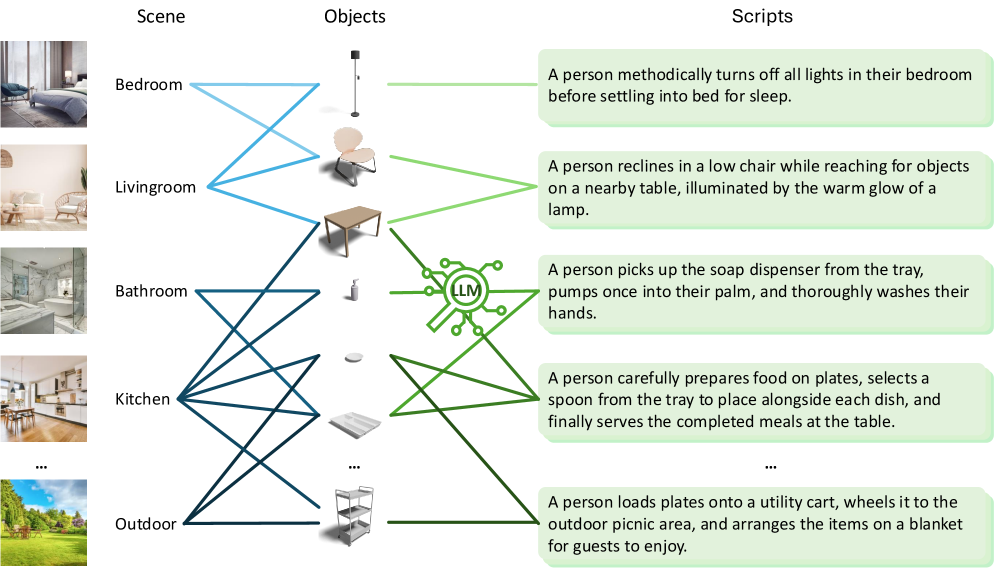

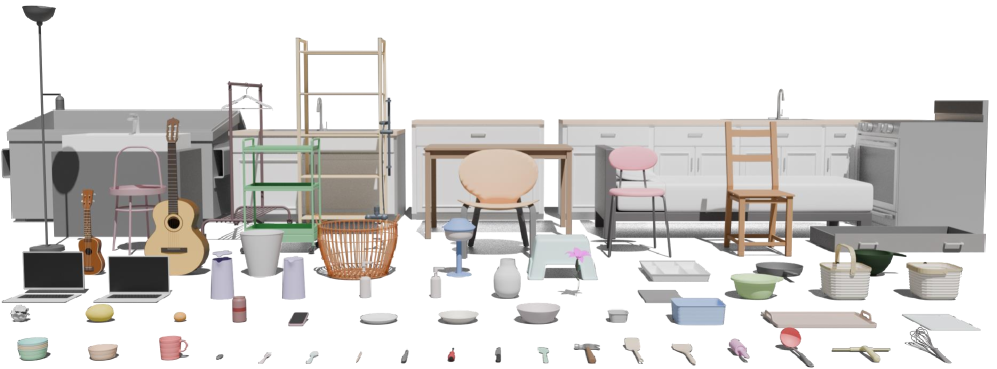
📊 实验亮点
HUMOTO数据集包含735个序列,总时长超过7875秒,涵盖了从烹饪到户外野餐等多种活动。与现有数据集相比,HUMOTO在规模、质量和交互复杂性方面均有显著提升。通过与其他数据集的基准比较,证明了HUMOTO在动作生成和人机交互建模方面的优越性。例如,在动作预测任务上,使用HUMOTO训练的模型能够显著降低预测误差。
🎯 应用场景
HUMOTO数据集可广泛应用于动画制作、机器人控制、具身智能等领域。例如,可以利用该数据集训练动作生成模型,生成逼真的人体-物体交互动画。也可以用于训练机器人控制策略,使机器人能够安全有效地与人类进行交互。此外,还可以用于开发具身智能系统,使智能体能够理解和执行复杂的任务。
📄 摘要(原文)
We present Human Motions with Objects (HUMOTO), a high-fidelity dataset of human-object interactions for motion generation, computer vision, and robotics applications. Featuring 735 sequences (7,875 seconds at 30 fps), HUMOTO captures interactions with 63 precisely modeled objects and 72 articulated parts. Our innovations include a scene-driven LLM scripting pipeline creating complete, purposeful tasks with natural progression, and a mocap-and-camera recording setup to effectively handle occlusions. Spanning diverse activities from cooking to outdoor picnics, HUMOTO preserves both physical accuracy and logical task flow. Professional artists rigorously clean and verify each sequence, minimizing foot sliding and object penetrations. We also provide benchmarks compared to other datasets. HUMOTO's comprehensive full-body motion and simultaneous multi-object interactions address key data-capturing challenges and provide opportunities to advance realistic human-object interaction modeling across research domains with practical applications in animation, robotics, and embodied AI systems. Project: https://jiaxin-lu.github.io/humoto/ .