Multimodal Representation Learning Techniques for Comprehensive Facial State Analysis
作者: Kaiwen Zheng, Xuri Ge, Junchen Fu, Jun Peng, Joemon M. Jose
分类: cs.CV
发布日期: 2025-04-14
备注: Accepted by ICME2025
期刊: ICME2025
💡 一句话要点
提出多层多模态面部基础模型(MF^2)用于全面面部状态分析,提升AU和情感识别性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 面部状态分析 动作单元识别 情感识别 跨模态融合 深度学习 计算机视觉
📋 核心要点
- 现有方法在理解面部状态(如AU和情感)时,缺乏有效桥接视觉和语言模态的全面框架,限制了性能。
- 论文提出多层多模态面部基础模型(MF^2),通过局部和全局视觉特征建模,对齐视觉表示与结构化描述,实现跨模态融合。
- 实验结果表明,所提出的方法在AU和情感检测任务中取得了优异的性能,验证了模型的有效性。
📝 摘要(中文)
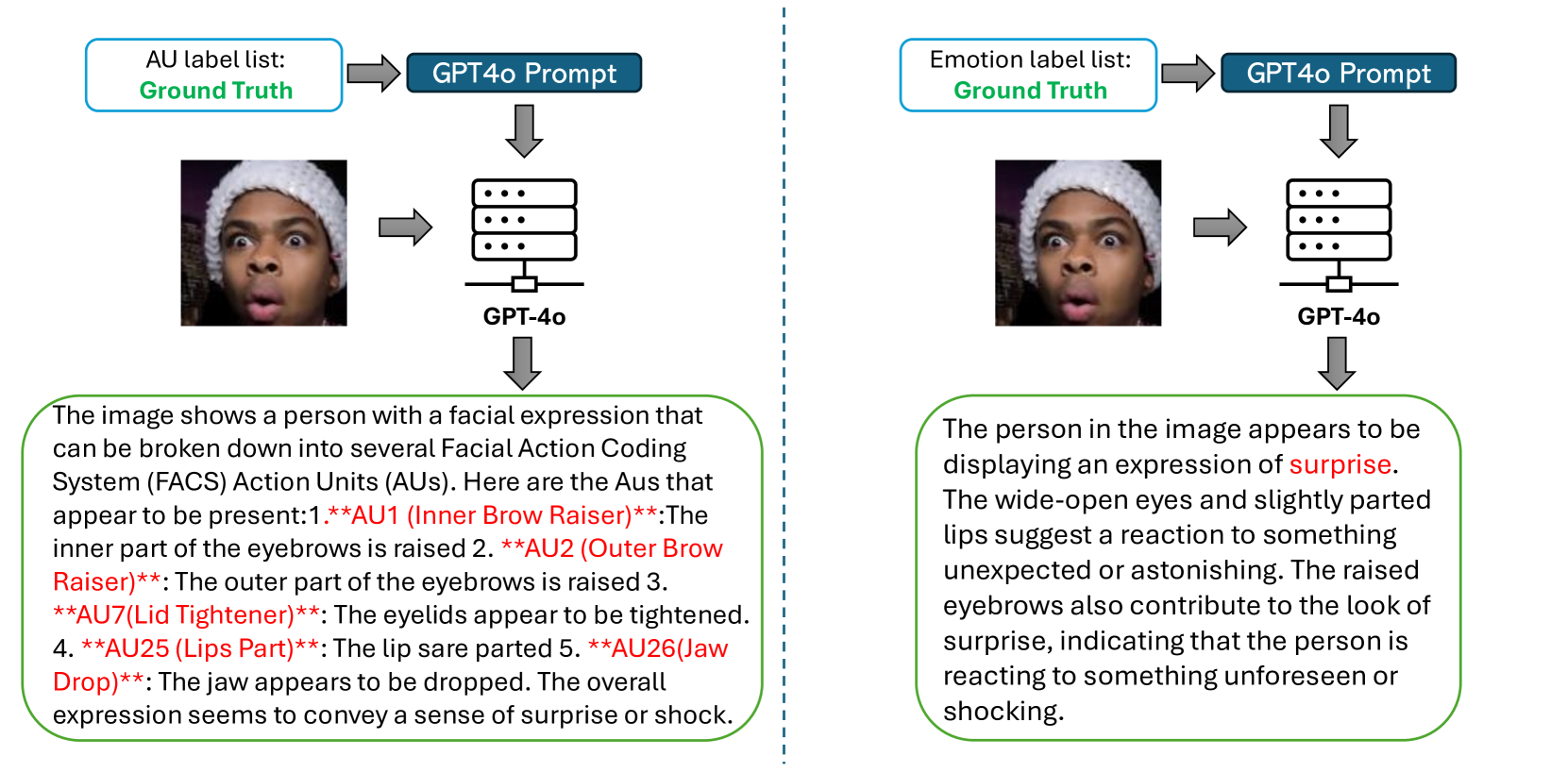
多模态基础模型通过整合来自多个模态的信息,显著提升了特征表示能力,使其非常适合更广泛的应用。然而,对于理解感知的多模态面部表示的探索仍然有限。理解和分析面部状态,如动作单元(AU)和情感,需要一个桥接视觉和语言模态的全面而鲁棒的框架。本文提出了一个用于多模态面部状态分析的完整流程。首先,我们利用GPT-4o生成面部的详细多层次语言描述,包括动作单元(AU)和情感描述,从而构建了一个新的多模态面部数据集(MFA)。其次,我们引入了一种新颖的多层多模态面部基础模型(MF^2),专门用于动作单元(AU)和情感识别。我们的模型在面部图像的局部和全局层面都融入了全面的视觉特征建模,增强了其表示详细面部外观的能力。这种设计将视觉表示与结构化的AU和情感描述对齐,确保了有效的跨模态融合。第三,我们开发了一个解耦微调网络(DFN),可以有效地将MF^2适配到各种任务和数据集。这种方法不仅降低了计算开销,还拓宽了基础模型在各种场景中的适用性。实验表明,该方法在AU和情感检测任务中表现出卓越的性能。
🔬 方法详解
问题定义:现有方法在面部状态分析,特别是动作单元(AU)和情感识别方面,面临着如何有效融合视觉和语言信息,以及如何构建一个既能捕捉局部细节又能理解全局上下文的鲁棒特征表示的挑战。现有方法通常难以充分利用多模态信息,导致性能瓶颈。
核心思路:论文的核心思路是构建一个多层多模态面部基础模型(MF^2),该模型能够同时处理面部图像的局部和全局视觉特征,并将这些特征与结构化的语言描述(如AU和情感描述)对齐。通过这种方式,模型可以学习到更全面、更鲁棒的面部状态表示,从而提升AU和情感识别的准确性。
技术框架:整体框架包含三个主要部分:1) 多模态面部数据集(MFA)的构建,利用GPT-4o生成详细的面部描述;2) 多层多模态面部基础模型(MF^2)的设计,包含视觉特征建模模块和跨模态融合模块;3) 解耦微调网络(DFN)的开发,用于高效地将MF^2适配到不同的任务和数据集。
关键创新:最重要的技术创新点在于MF^2模型的设计,它不仅考虑了面部图像的局部和全局视觉特征,还通过与结构化的语言描述对齐,实现了有效的跨模态融合。此外,DFN的解耦微调策略也降低了计算开销,提高了模型的泛化能力。
关键设计:MF^2模型在视觉特征建模方面,可能采用了卷积神经网络(CNN)或Transformer等结构来提取局部和全局特征。在跨模态融合方面,可能使用了注意力机制或对比学习等方法来对齐视觉和语言表示。DFN的解耦微调策略可能涉及到将模型参数分为不同的组,并采用不同的学习率进行微调。
🖼️ 关键图片


📊 实验亮点
论文实验结果表明,提出的MF^2模型在AU和情感检测任务中取得了显著的性能提升。具体数据未知,但摘要中明确指出“Experimentation show superior performance for AU and emotion detection tasks.”,表明该方法优于现有基线方法。
🎯 应用场景
该研究成果可应用于人机交互、情感计算、安全监控、医疗诊断等领域。例如,在人机交互中,可以利用该模型更准确地理解用户的情绪状态,从而提供更个性化的服务。在医疗诊断中,可以辅助医生识别面部表情中的微小变化,从而帮助诊断疾病。未来,该技术有望在更广泛的领域发挥重要作用。
📄 摘要(原文)
Multimodal foundation models have significantly improved feature representation by integrating information from multiple modalities, making them highly suitable for a broader set of applications. However, the exploration of multimodal facial representation for understanding perception has been limited. Understanding and analyzing facial states, such as Action Units (AUs) and emotions, require a comprehensive and robust framework that bridges visual and linguistic modalities. In this paper, we present a comprehensive pipeline for multimodal facial state analysis. First, we compile a new Multimodal Face Dataset (MFA) by generating detailed multilevel language descriptions of face, incorporating Action Unit (AU) and emotion descriptions, by leveraging GPT-4o. Second, we introduce a novel Multilevel Multimodal Face Foundation model (MF^2) tailored for Action Unit (AU) and emotion recognition. Our model incorporates comprehensive visual feature modeling at both local and global levels of face image, enhancing its ability to represent detailed facial appearances. This design aligns visual representations with structured AU and emotion descriptions, ensuring effective cross-modal integration. Third, we develop a Decoupled Fine-Tuning Network (DFN) that efficiently adapts MF^2 across various tasks and datasets. This approach not only reduces computational overhead but also broadens the applicability of the foundation model to diverse scenarios. Experimentation show superior performance for AU and emotion detection tasks.