XY-Cut++: Advanced Layout Ordering via Hierarchical Mask Mechanism on a Novel Benchmark
作者: Shuai Liu, Youmeng Li, Jizeng Wei
分类: cs.CV, cs.MM
发布日期: 2025-04-14 (更新: 2025-10-29)
💡 一句话要点
提出XY-Cut++,通过层级掩码机制实现文档布局排序的显著提升
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档图像理解 布局排序 阅读顺序恢复 跨模态匹配 多粒度分割 预掩码处理 RAG LLM
📋 核心要点
- 现有文档阅读顺序恢复方法难以处理复杂布局,且跨模态交互成本高昂,缺乏有效的评估基准。
- XY-Cut++通过预掩码处理、多粒度分割和跨模态匹配,显著提升了复杂文档的布局排序准确性。
- 在DocBench-100数据集上,XY-Cut++超越现有基线高达24%,BLEU值达到98.8,确立了新的SOTA。
📝 摘要(中文)
本文提出了一种先进的布局排序方法XY-Cut++,它集成了预掩码处理、多粒度分割和跨模态匹配,旨在解决文档图像理解中文档阅读顺序恢复这一基本任务的挑战。现有方法在处理复杂布局(如多栏报纸)、跨模态元素(视觉区域和文本语义)之间的高开销交互以及缺乏鲁棒的评估基准方面存在困难。XY-Cut++显著提高了布局排序的准确性,在保持简单性和效率的同时,实现了最先进的性能(总体BLEU值为98.8)。在新的DocBench-100数据集上,XY-Cut++的性能比现有基线提高了高达24%,并在简单和复杂布局中表现出一致的准确性。这项进展为文档结构恢复奠定了可靠的基础,为布局排序任务设定了新标准,并促进了更有效的RAG和LLM预处理。
🔬 方法详解
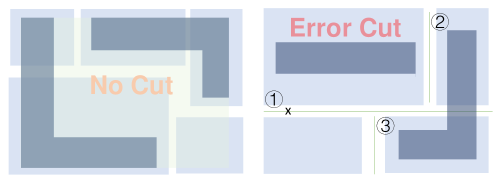
问题定义:文档阅读顺序恢复是文档图像理解中的关键任务,对于增强检索增强生成(RAG)和作为大型语言模型(LLM)的预处理步骤至关重要。现有方法在处理复杂布局(如多栏报纸),以及视觉区域和文本语义之间的高开销交互方面存在困难。此外,缺乏一个鲁棒的评估基准也限制了现有方法的发展。
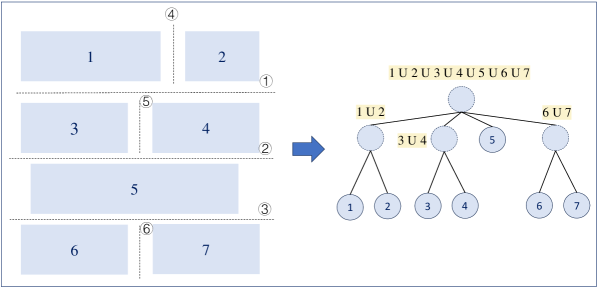
核心思路:XY-Cut++的核心思路是通过引入预掩码处理来减少噪声,利用多粒度分割来适应不同复杂度的布局,并采用跨模态匹配来融合视觉和文本信息,从而更准确地恢复文档的阅读顺序。这种设计旨在克服传统XY-Cut方法在处理复杂文档布局时的局限性。
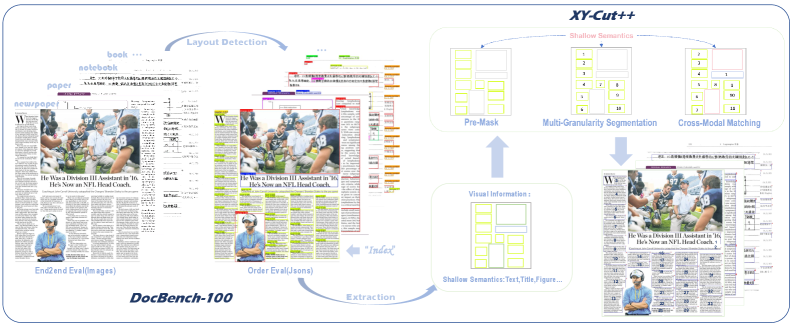
技术框架:XY-Cut++的整体框架包括以下几个主要阶段:1) 预掩码处理:使用预训练模型去除文档图像中的噪声和无关元素。2) 多粒度分割:采用不同粒度的分割策略,以适应文档布局的复杂性。3) 跨模态匹配:融合视觉特征和文本语义信息,以确定最佳的阅读顺序。4) 布局排序:根据分割和匹配的结果,生成最终的文档阅读顺序。
关键创新:XY-Cut++的关键创新在于其层级掩码机制和跨模态匹配策略。层级掩码机制通过预掩码处理有效减少了噪声干扰,提高了分割的准确性。跨模态匹配则充分利用了视觉和文本信息,从而更准确地确定了文档的阅读顺序。与传统XY-Cut方法相比,XY-Cut++能够更好地处理复杂布局,并具有更高的鲁棒性。
关键设计:预掩码处理阶段使用了预训练的视觉模型进行噪声去除。多粒度分割阶段采用了多种分割算法,并根据文档布局的复杂性自适应地选择合适的分割策略。跨模态匹配阶段使用了注意力机制来融合视觉特征和文本语义信息。损失函数的设计旨在最大化预测阅读顺序与真实阅读顺序之间的相似度,例如使用BLEU指标作为优化目标。
🖼️ 关键图片
📊 实验亮点
XY-Cut++在DocBench-100数据集上取得了显著的性能提升,总体BLEU值达到98.8,超越现有基线高达24%。实验结果表明,XY-Cut++在处理简单和复杂布局时均表现出一致的准确性,验证了其鲁棒性和有效性。此外,该方法在保持简单性和效率的同时,实现了最先进的性能。
🎯 应用场景
XY-Cut++在文档图像理解领域具有广泛的应用前景,可用于提升RAG系统的性能,并作为LLM的有效预处理步骤。该方法可应用于数字化图书馆、文档管理系统、自动化办公等场景,实现文档的自动分析和理解,提高信息检索和利用效率。未来,该技术有望应用于更复杂的文档类型,如手写文档和多语言文档。
📄 摘要(原文)
Document Reading Order Recovery is a fundamental task in document image understanding, playing a pivotal role in enhancing Retrieval-Augmented Generation (RAG) and serving as a critical preprocessing step for large language models (LLMs). Existing methods often struggle with complex layouts(e.g., multi-column newspapers), high-overhead interactions between cross-modal elements (visual regions and textual semantics), and a lack of robust evaluation benchmarks. We introduce XY-Cut++, an advanced layout ordering method that integrates pre-mask processing, multi-granularity segmentation, and cross-modal matching to address these challenges. Our method significantly enhances layout ordering accuracy compared to traditional XY-Cut techniques. Specifically, XY-Cut++ achieves state-of-the-art performance (98.8 BLEU overall) while maintaining simplicity and efficiency. It outperforms existing baselines by up to 24\% and demonstrates consistent accuracy across simple and complex layouts on the newly introduced DocBench-100 dataset. This advancement establishes a reliable foundation for document structure recovery, setting a new standard for layout ordering tasks and facilitating more effective RAG and LLM preprocessing.