AGO: Adaptive Grounding for Open World 3D Occupancy Prediction
作者: Peizheng Li, Shuxiao Ding, You Zhou, Qingwen Zhang, Onat Inak, Larissa Triess, Niklas Hanselmann, Marius Cordts, Andreas Zell
分类: cs.CV
发布日期: 2025-04-14 (更新: 2025-11-10)
🔗 代码/项目: GITHUB
💡 一句话要点
提出AGO,通过自适应Grounding实现开放世界3D Occupancy预测。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D Occupancy预测 开放世界学习 视觉语言模型 自适应Grounding 模态对齐
📋 核心要点
- 现有基于VLM的方法依赖预定义标签空间,限制了开放世界场景下的泛化能力,且VLM图像和文本表示不一致导致直接对齐效果不佳。
- AGO通过自适应Grounding,将图像和类提示分别编码为3D和文本嵌入,并使用模态适配器对齐3D和VLM图像嵌入空间,减小模态差异。
- 在Occ3D-nuScenes数据集上,AGO在零样本和少样本迁移中提升了未知对象预测,并在封闭世界自监督学习中取得了SOTA,mIoU提升4.09。
📝 摘要(中文)
开放世界3D语义Occupancy预测旨在从传感器输入生成体素化的3D表示,同时识别已知和未知对象。从视觉-语言模型(VLM)迁移开放词汇知识是一个有希望的方向,但仍然具有挑战性。基于VLM导出的2D伪标签和传统监督的方法受到预定义标签空间的限制,缺乏通用预测能力。另一方面,由于VLM中图像和文本表示的不一致,与预训练图像嵌入的直接对齐通常无法实现可靠的性能。为了解决这些挑战,我们提出AGO,一种具有自适应Grounding的新型3D Occupancy预测框架,以处理各种开放世界场景。AGO首先将周围图像和类提示分别编码为3D和文本嵌入,利用基于相似性的Grounding训练和3D伪标签。此外,模态适配器将3D嵌入映射到与VLM导出的图像嵌入对齐的空间,从而减少模态差距。在Occ3D-nuScenes上的实验表明,AGO在零样本和少样本迁移中提高了未知对象预测,同时实现了最先进的封闭世界自监督性能,超过了先前方法4.09 mIoU。
🔬 方法详解
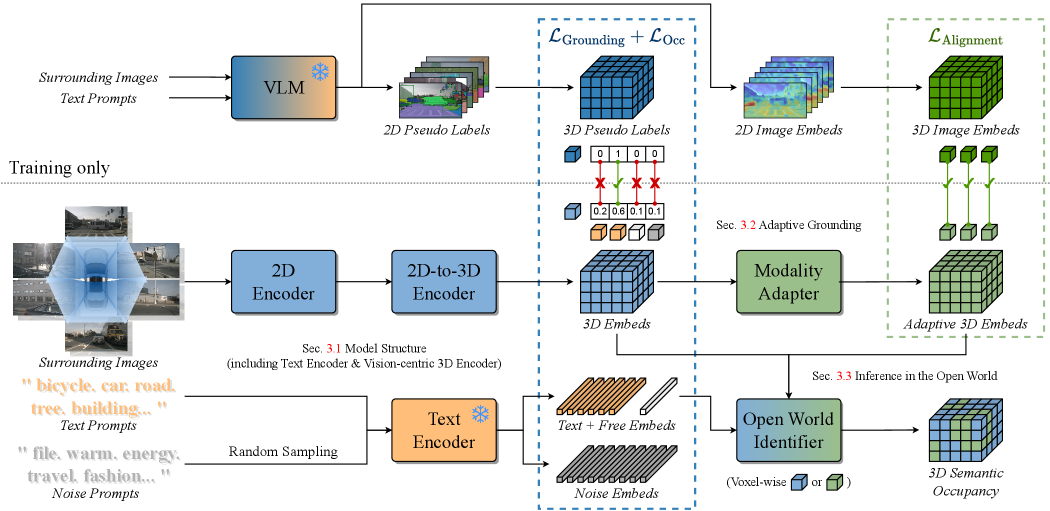
问题定义:开放世界3D Occupancy预测旨在识别场景中所有物体,包括已知和未知类别。现有方法主要依赖于预定义的类别标签,无法有效处理开放世界中不断出现的新类别。此外,直接利用视觉-语言模型(VLM)进行特征对齐时,由于图像和文本模态之间的差异,性能往往不佳。
核心思路:AGO的核心思路是通过自适应Grounding,将视觉信息(图像)和语义信息(文本)进行有效对齐,从而实现对开放世界场景的理解。具体来说,它学习一个共同的嵌入空间,使得相似的图像和文本在嵌入空间中距离更近,从而提高未知物体的识别能力。
技术框架:AGO框架主要包含以下几个模块:1) 图像编码器:将周围图像编码为3D特征嵌入。2) 文本编码器:将类别提示(class prompts)编码为文本嵌入。3) 相似性Grounding模块:利用3D伪标签,通过相似性学习,将图像和文本嵌入对齐。4) 模态适配器:将3D嵌入映射到与VLM导出的图像嵌入对齐的空间,减少模态差距。5) Occupancy预测模块:基于对齐的嵌入,预测3D Occupancy。
关键创新:AGO的关键创新在于其自适应Grounding机制,它能够动态地调整图像和文本嵌入的对齐方式,从而更好地适应开放世界场景中不断变化的物体类别。此外,模态适配器的引入有效减小了3D特征和VLM图像特征之间的模态差异,提升了整体性能。
关键设计:在相似性Grounding模块中,使用了对比损失函数,鼓励相似的图像和文本嵌入距离更近,不相似的距离更远。模态适配器采用简单的MLP结构,将3D嵌入映射到VLM图像嵌入空间。在训练过程中,使用了3D伪标签作为监督信号,引导模型学习有效的特征表示。
🖼️ 关键图片


📊 实验亮点
AGO在Occ3D-nuScenes数据集上取得了显著的性能提升。在封闭世界自监督学习中,AGO超过了之前的SOTA方法4.09 mIoU。在零样本和少样本迁移学习中,AGO也表现出优异的未知物体预测能力,证明了其在开放世界场景下的有效性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。在自动驾驶中,可以提高对未知障碍物的识别能力,增强安全性。在机器人导航中,可以帮助机器人在复杂环境中更好地理解和规划路径。在增强现实中,可以实现更逼真的虚拟物体与真实环境的融合。
📄 摘要(原文)
Open-world 3D semantic occupancy prediction aims to generate a voxelized 3D representation from sensor inputs while recognizing both known and unknown objects. Transferring open-vocabulary knowledge from vision-language models (VLMs) offers a promising direction but remains challenging. However, methods based on VLM-derived 2D pseudo-labels with traditional supervision are limited by a predefined label space and lack general prediction capabilities. Direct alignment with pretrained image embeddings, on the other hand, often fails to achieve reliable performance because of inconsistent image and text representations in VLMs. To address these challenges, we propose AGO, a novel 3D occupancy prediction framework with adaptive grounding to handle diverse open-world scenarios. AGO first encodes surrounding images and class prompts into 3D and text embeddings, respectively, leveraging similarity-based grounding training with 3D pseudo-labels. Additionally, a modality adapter maps 3D embeddings into a space aligned with VLM-derived image embeddings, reducing modality gaps. Experiments on Occ3D-nuScenes show that AGO improves unknown object prediction in zero-shot and few-shot transfer while achieving state-of-the-art closed-world self-supervised performance, surpassing prior methods by 4.09 mIoU. Code is available at: https://github.com/EdwardLeeLPZ/AGO.