Enhancing Multi-task Learning Capability of Medical Generalist Foundation Model via Image-centric Multi-annotation Data
作者: Xun Zhu, Fanbin Mo, Zheng Zhang, Jiaxi Wang, Yiming Shi, Ming Wu, Chuang Zhang, Miao Li, Ji Wu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-04-14
💡 一句话要点
提出IMAX数据集,提升医学通用Foundation模型的多任务学习能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像 多任务学习 Foundation模型 数据集构建 X射线 多模态大语言模型 图像标注
📋 核心要点
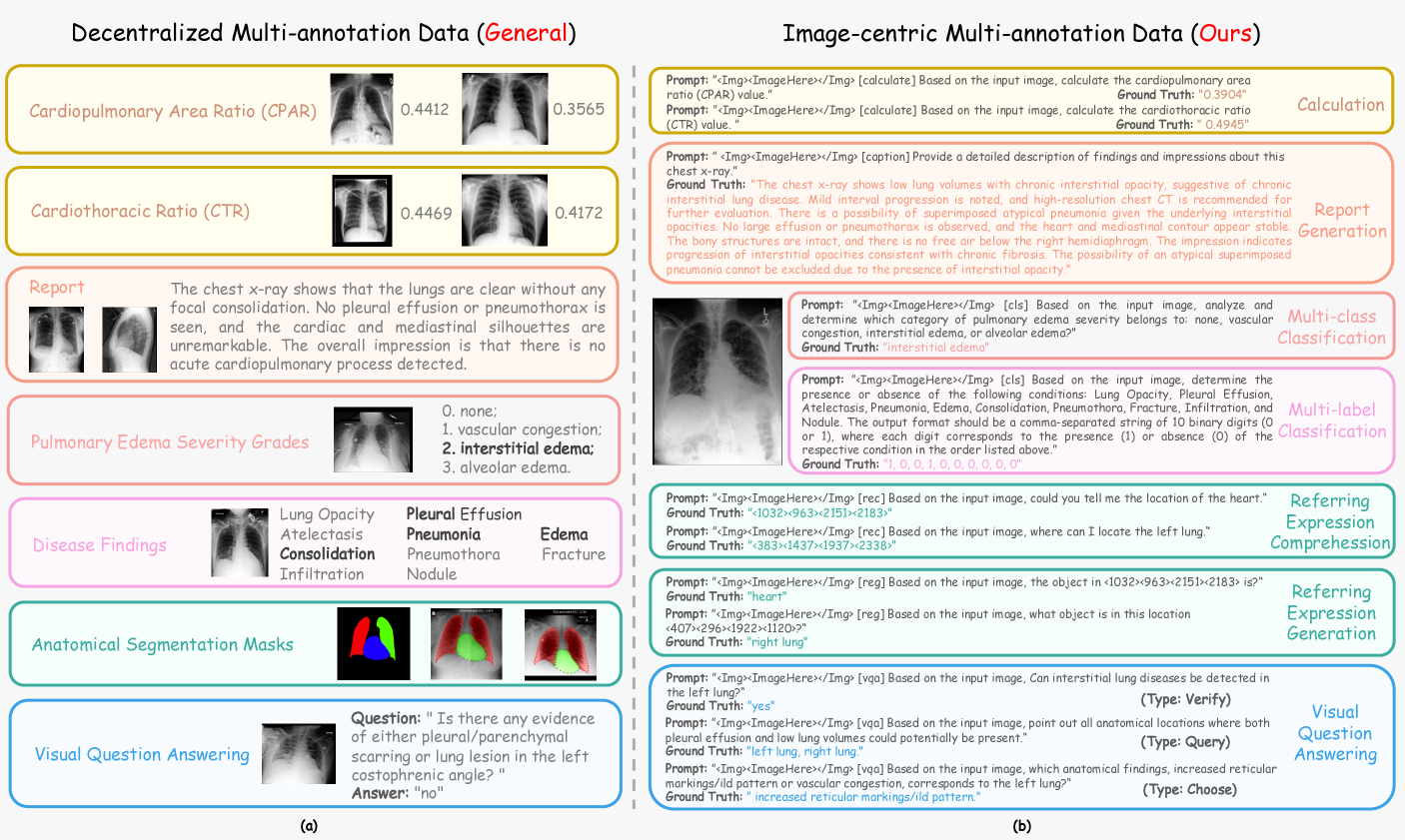
- 现有医学多任务学习方法侧重数据规模和模型架构,忽略了数据质量和图像-任务对齐的重要性。
- 论文提出图像中心的密集标注数据集IMAX,确保每张图像包含丰富的多任务信息,提升模型理解能力。
- 实验表明,IMAX在多个医学MLLM上显著提升多任务平均性能,最高提升达21.05%。
📝 摘要(中文)
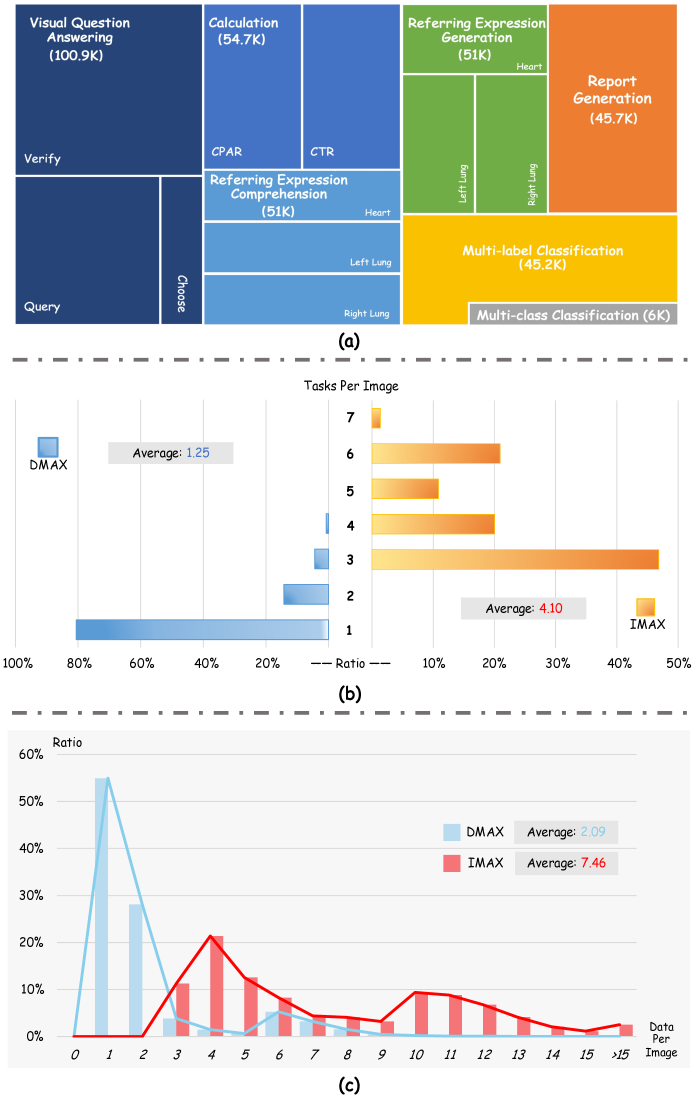
医学通用Foundation模型通过大规模医学数据集上的联合训练,革新了传统的任务特定模型开发模式,旨在更好地处理多项任务。然而,当前的研究主要集中于简单的数据扩展或架构组件增强,而忽略了从数据角度重新审视多任务学习。简单地聚合现有数据资源会导致分散的图像-任务对齐,无法培养全面的图像理解或满足临床对多维度图像解读的需求。本文提出了图像中心的X射线多标注数据集(IMAX),首次尝试从数据构建层面增强医学多模态大语言模型(MLLM)的多任务学习能力。IMAX具有以下特点:1)高质量的数据管理。全面收集了超过354K个适用于七种不同医学任务的条目。2)图像中心密集标注。每张X射线图像平均关联4.10个任务和7.46个训练条目,确保了每张图像的多任务表示丰富性。与通用的分散式多标注X射线数据集(DMAX)相比,IMAX在七个开源最先进的医学MLLM上始终表现出显著的多任务平均性能提升,范围从3.20%到21.05%。此外,我们研究了IMAX和DMAX训练过程所表现出的统计模式差异,探索了优化动态与多任务性能之间的潜在相关性。最后,利用IMAX数据构建的核心概念,我们提出了一种优化的基于DMAX的训练策略,以缓解在实际场景中获取高质量IMAX数据的困境。
🔬 方法详解
问题定义:现有医学多任务学习方法在构建训练数据时,通常简单地聚合现有的数据集,导致图像和任务之间的对应关系分散,即一张图像可能只对应少数几个任务的标注。这种分散的标注方式不利于模型学习到图像的多维度信息,限制了模型的多任务学习能力。现有方法的痛点在于缺乏高质量的、图像中心的多任务标注数据。
核心思路:论文的核心思路是构建一个图像中心的多标注数据集IMAX,确保每张X射线图像都关联多个任务的标注信息。通过这种方式,模型可以学习到图像的多维度表示,从而提升多任务学习能力。IMAX数据集的设计理念是围绕单张图像构建尽可能丰富的标注信息,模拟临床医生对X光片的综合解读过程。
技术框架:论文主要关注数据集的构建和训练策略的优化,并没有提出新的模型架构。整体流程如下:1)构建IMAX数据集,对每张X射线图像进行多任务标注。2)使用IMAX数据集训练多个现有的医学MLLM模型。3)对比IMAX和DMAX数据集的训练效果。4)提出一种优化的基于DMAX的训练策略,以缓解获取高质量IMAX数据的困难。
关键创新:论文最重要的技术创新点在于提出了图像中心的多标注数据构建方法。与传统的分散式标注方法不同,IMAX数据集强调每张图像的多任务表示丰富性。这种数据构建方法更符合临床医生的诊断习惯,有助于模型学习到更全面的图像理解能力。
关键设计:IMAX数据集的关键设计在于其图像中心的密集标注策略。具体来说,每张X射线图像平均关联4.10个任务和7.46个训练条目。论文还研究了IMAX和DMAX数据集在训练过程中的统计模式差异,并探索了优化动态与多任务性能之间的潜在相关性。基于这些研究结果,论文提出了一种优化的基于DMAX的训练策略,通过调整训练样本的采样概率,模拟IMAX数据集的图像中心特性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,IMAX数据集在七个开源医学MLLM上均取得了显著的性能提升,多任务平均性能提升范围为3.20%到21.05%。此外,论文还提出了一种优化的基于DMAX的训练策略,可以在一定程度上缓解获取高质量IMAX数据的困难,为实际应用提供了可行方案。
🎯 应用场景
该研究成果可应用于医学影像辅助诊断领域,提升AI模型在多病种识别、疾病分期等复杂任务中的性能。高质量的多任务数据集和训练策略,有助于开发更可靠、更全面的医学影像分析系统,辅助医生进行更准确的诊断和治疗决策,具有重要的临床应用价值。
📄 摘要(原文)
The emergence of medical generalist foundation models has revolutionized conventional task-specific model development paradigms, aiming to better handle multiple tasks through joint training on large-scale medical datasets. However, recent advances prioritize simple data scaling or architectural component enhancement, while neglecting to re-examine multi-task learning from a data-centric perspective. Critically, simply aggregating existing data resources leads to decentralized image-task alignment, which fails to cultivate comprehensive image understanding or align with clinical needs for multi-dimensional image interpretation. In this paper, we introduce the image-centric multi-annotation X-ray dataset (IMAX), the first attempt to enhance the multi-task learning capabilities of medical multi-modal large language models (MLLMs) from the data construction level. To be specific, IMAX is featured from the following attributes: 1) High-quality data curation. A comprehensive collection of more than 354K entries applicable to seven different medical tasks. 2) Image-centric dense annotation. Each X-ray image is associated with an average of 4.10 tasks and 7.46 training entries, ensuring multi-task representation richness per image. Compared to the general decentralized multi-annotation X-ray dataset (DMAX), IMAX consistently demonstrates significant multi-task average performance gains ranging from 3.20% to 21.05% across seven open-source state-of-the-art medical MLLMs. Moreover, we investigate differences in statistical patterns exhibited by IMAX and DMAX training processes, exploring potential correlations between optimization dynamics and multi-task performance. Finally, leveraging the core concept of IMAX data construction, we propose an optimized DMAX-based training strategy to alleviate the dilemma of obtaining high-quality IMAX data in practical scenarios.