Digital Staining with Knowledge Distillation: A Unified Framework for Unpaired and Paired-But-Misaligned Data
作者: Ziwang Xu, Lanqing Guo, Satoshi Tsutsui, Shuyan Zhang, Alex C. Kot, Bihan Wen
分类: cs.CV, eess.IV
发布日期: 2025-04-14
备注: Accepted to IEEE Transactions on Medical Imaging
💡 一句话要点
提出基于知识蒸馏的数字染色统一框架,解决非配对和错配数据下的细胞染色问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数字染色 知识蒸馏 无监督学习 细胞成像 医学诊断
📋 核心要点
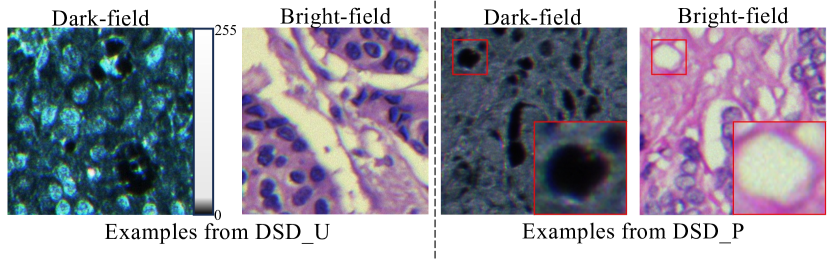
- 传统细胞染色成本高昂且耗时,难以获取大量完美配对的染色/未染色图像数据。
- 论文提出基于知识蒸馏的无监督框架,利用非配对或错配数据进行数字染色。
- 实验表明,该方法在细胞位置和形状上更准确,并在NIQE和PSNR等指标上优于现有方法。
📝 摘要(中文)
细胞染色在细胞成像和医学诊断中至关重要,但面临成本高、耗时、劳动强度大以及组织不可逆改变等挑战。深度学习的最新进展使得通过监督模型训练实现数字染色成为可能。然而,收集大规模、完美对齐的染色和未染色图像对仍然很困难。本文提出了一种新颖的无监督深度学习框架用于数字细胞染色,该框架通过知识蒸馏减少了对大量配对数据的需求。我们探索了两种训练方案:(1)非配对和(2)配对但错配设置。对于非配对情况,我们引入了一个两阶段流程,包括光照增强和着色,作为教师模型。随后,我们通过具有混合非参考损失的知识蒸馏获得学生染色生成器。为了利用相邻切片之间的像素级信息,我们进一步扩展到配对但错配设置,添加了“学习对齐”模块以利用像素级信息。在我们数据集上的实验结果表明,我们提出的无监督深度染色方法可以在两种设置下生成具有更准确位置和细胞目标形状的染色图像。与竞争方法相比,我们的方法在质量和数量上都取得了改进的结果(例如,NIQE和PSNR)。我们将我们的数字染色方法应用于白细胞(WBC)数据集,研究其在医疗应用中的潜力。
🔬 方法详解
问题定义:论文旨在解决数字病理学中细胞染色的问题,特别是当染色图像和未染色图像无法完美配对,或者完全没有配对数据时。现有方法依赖于大量精确配对的数据进行监督学习,这在实际应用中很难满足,因为图像配准过程复杂且容易出错。因此,如何利用非配对或错配的数据进行有效的数字染色是一个关键挑战。
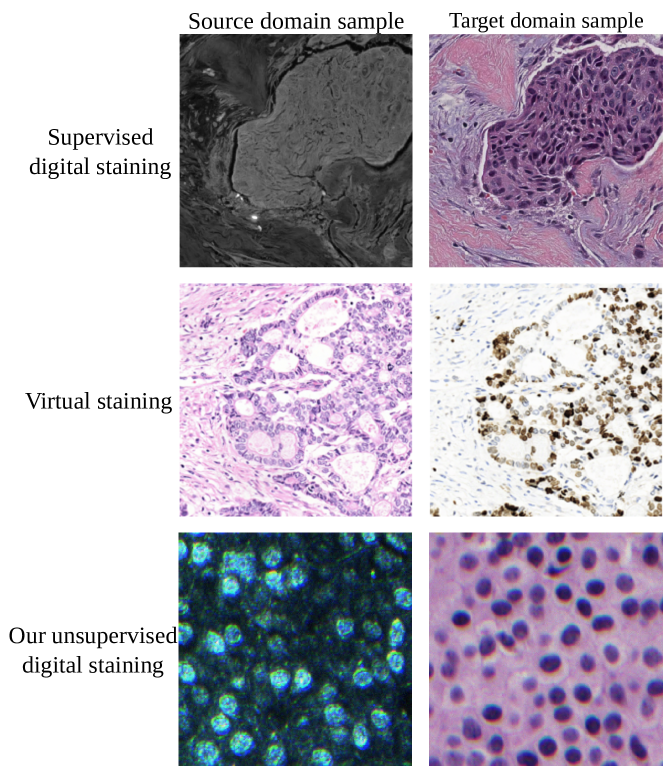
核心思路:论文的核心思路是利用知识蒸馏,将一个预训练的教师模型(teacher model)的知识迁移到一个学生模型(student model)中。教师模型负责生成高质量的染色图像,而学生模型则学习模仿教师模型的输出,从而实现数字染色。通过这种方式,可以减少对精确配对数据的依赖,并提高模型的泛化能力。
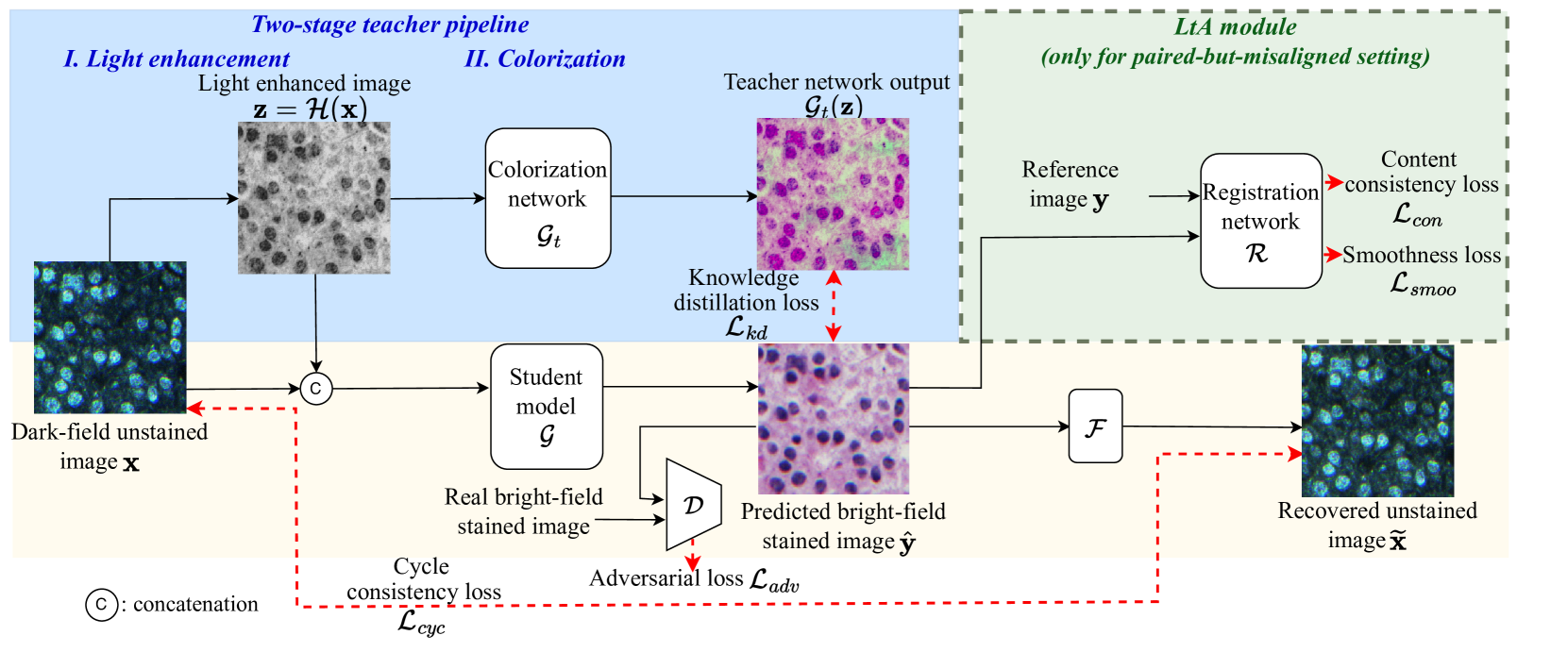
技术框架:该框架包含两个主要的训练方案:非配对设置和配对但错配设置。在非配对设置中,首先使用一个两阶段流程(光照增强和着色)作为教师模型。然后,通过知识蒸馏,利用混合非参考损失训练学生染色生成器。在配对但错配设置中,增加了一个“学习对齐”模块,以利用像素级信息,进一步提高染色效果。整体流程包括数据预处理、教师模型训练、学生模型训练和结果评估等步骤。
关键创新:该论文的关键创新在于提出了一个统一的、基于知识蒸馏的无监督数字染色框架,能够处理非配对和配对但错配的数据。通过引入知识蒸馏,减少了对精确配对数据的依赖,提高了模型的鲁棒性和泛化能力。此外,“学习对齐”模块的引入,进一步提升了在配对但错配数据下的染色效果。
关键设计:在非配对设置中,教师模型采用两阶段流程,首先进行光照增强,然后进行着色。学生模型通过最小化混合非参考损失(例如,NIQE损失和PSNR损失)来学习模仿教师模型的输出。在配对但错配设置中,“学习对齐”模块可能包含可学习的变换参数,用于校正图像之间的错位。具体的网络结构(例如,生成器和判别器的结构)和损失函数的设计细节在论文中应该有更详细的描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在非配对和配对但错配设置下均能生成高质量的染色图像,并在细胞位置和形状的准确性方面优于现有方法。在白细胞(WBC)数据集上的应用表明,该方法具有潜在的医疗应用价值。定量指标方面,例如NIQE和PSNR,均显示出优于其他竞争方法的性能。
🎯 应用场景
该研究成果可广泛应用于数字病理学、细胞成像和医学诊断等领域。通过数字染色技术,可以降低染色成本、缩短染色时间、减少人工操作,并避免组织损伤。此外,该技术还可以用于白细胞分类、肿瘤诊断等医疗应用,为医生提供更准确、更高效的诊断工具。未来,该技术有望与人工智能辅助诊断系统相结合,进一步提高诊断的准确性和效率。
📄 摘要(原文)
Staining is essential in cell imaging and medical diagnostics but poses significant challenges, including high cost, time consumption, labor intensity, and irreversible tissue alterations. Recent advances in deep learning have enabled digital staining through supervised model training. However, collecting large-scale, perfectly aligned pairs of stained and unstained images remains difficult. In this work, we propose a novel unsupervised deep learning framework for digital cell staining that reduces the need for extensive paired data using knowledge distillation. We explore two training schemes: (1) unpaired and (2) paired-but-misaligned settings. For the unpaired case, we introduce a two-stage pipeline, comprising light enhancement followed by colorization, as a teacher model. Subsequently, we obtain a student staining generator through knowledge distillation with hybrid non-reference losses. To leverage the pixel-wise information between adjacent sections, we further extend to the paired-but-misaligned setting, adding the Learning to Align module to utilize pixel-level information. Experiment results on our dataset demonstrate that our proposed unsupervised deep staining method can generate stained images with more accurate positions and shapes of the cell targets in both settings. Compared with competing methods, our method achieves improved results both qualitatively and quantitatively (e.g., NIQE and PSNR).We applied our digital staining method to the White Blood Cell (WBC) dataset, investigating its potential for medical applications.