ST-Booster: An Iterative SpatioTemporal Perception Booster for Vision-and-Language Navigation in Continuous Environments
作者: Lu Yue, Dongliang Zhou, Liang Xie, Erwei Yin, Feitian Zhang
分类: cs.CV, cs.RO
发布日期: 2025-04-14 (更新: 2025-12-02)
备注: 11 pages, 7 figures
💡 一句话要点
提出ST-Booster,增强连续环境下的视觉语言导航中时空感知能力。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 连续环境 时空感知 多粒度融合 指令感知 机器人导航 注意力机制
📋 核心要点
- VLN-CE任务在连续空间导航中面临异构视觉记忆和三维重建误差带来的感知挑战。
- ST-Booster通过分层时空编码、多粒度对齐融合和值引导航点生成来增强导航性能。
- 实验结果表明,ST-Booster在复杂环境中优于现有方法,提升了导航性能。
📝 摘要(中文)
本文提出了一种用于连续环境下的视觉语言导航(VLN-CE)的迭代时空增强器ST-Booster。VLN-CE要求智能体基于自然语言指令在未知的连续空间中导航。与离散环境相比,VLN-CE面临两个核心感知挑战:缺乏预定义的观察点导致异构的视觉记忆和减弱的全局空间相关性;三维场景中累积的重建误差引入结构噪声,损害局部特征感知。为了解决这些挑战,ST-Booster通过多粒度感知和指令感知推理来增强导航性能。ST-Booster包含三个关键模块:分层时空编码(HSTE)、多粒度对齐融合(MGAF)和值引导航点生成(VGWG)。HSTE使用拓扑图编码长期全局记忆,并通过网格地图捕获短期局部细节。MGAF通过几何感知知识融合将这些双图表示与指令对齐。生成的表示通过预训练任务迭代细化。在推理过程中,VGWG生成引导注意力热图(GAHs)以显式地建模环境-指令相关性并优化航点选择。大量的对比实验和性能分析表明,ST-Booster优于现有的最先进方法,尤其是在复杂的、易受干扰的环境中。
🔬 方法详解
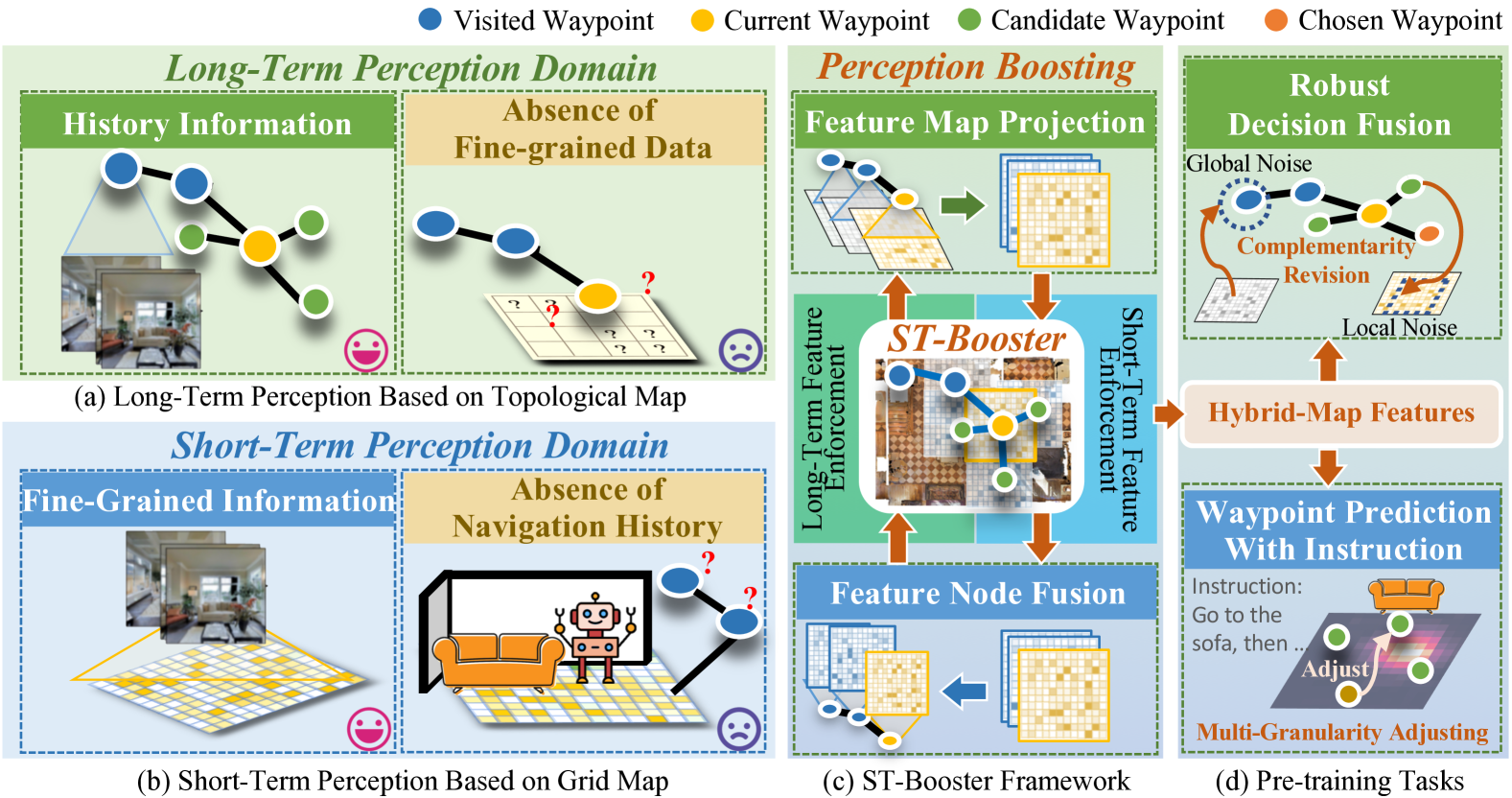
问题定义:视觉语言导航在连续环境(VLN-CE)中,智能体需要在未知的连续空间中根据自然语言指令进行导航。现有方法的痛点在于,缺乏预定义的观察点导致视觉记忆异构,全局空间相关性减弱,同时三维场景重建误差累积,引入结构噪声,损害局部特征感知。
核心思路:ST-Booster的核心思路是通过多粒度感知和指令感知推理来增强导航性能。具体来说,它结合了拓扑图和网格地图两种表示方式,分别编码长期全局记忆和短期局部细节,并通过多粒度对齐融合将这些表示与指令对齐。此外,通过迭代细化表示和生成引导注意力热图,显式建模环境-指令相关性,优化航点选择。
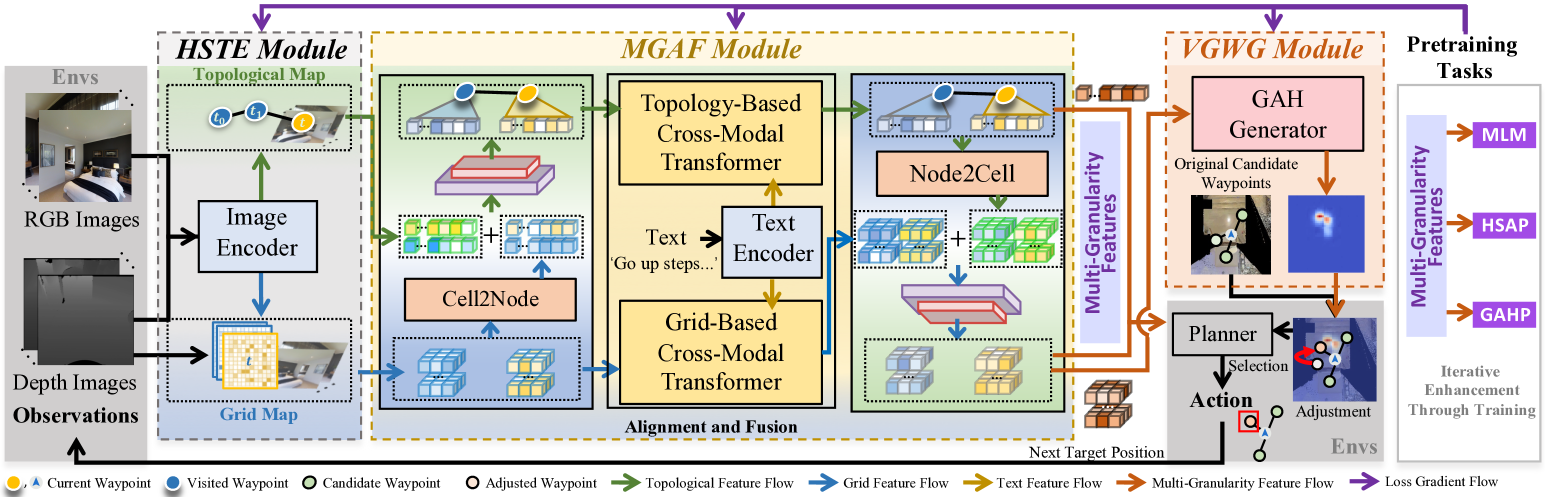
技术框架:ST-Booster的整体架构包含三个主要模块:分层时空编码(HSTE)、多粒度对齐融合(MGAF)和值引导航点生成(VGWG)。HSTE负责编码环境信息,MGAF负责融合环境信息和指令信息,VGWG负责生成航点。整个流程是迭代的,通过预训练任务不断细化表示。
关键创新:ST-Booster的关键创新在于其多粒度的时空感知能力和指令感知的推理方式。它同时利用拓扑图和网格地图来表示环境,并使用几何感知知识融合将这些表示与指令对齐。此外,通过引导注意力热图显式建模环境-指令相关性,从而更有效地选择航点。与现有方法相比,ST-Booster更关注环境的全局结构和局部细节,并能更好地利用指令信息。
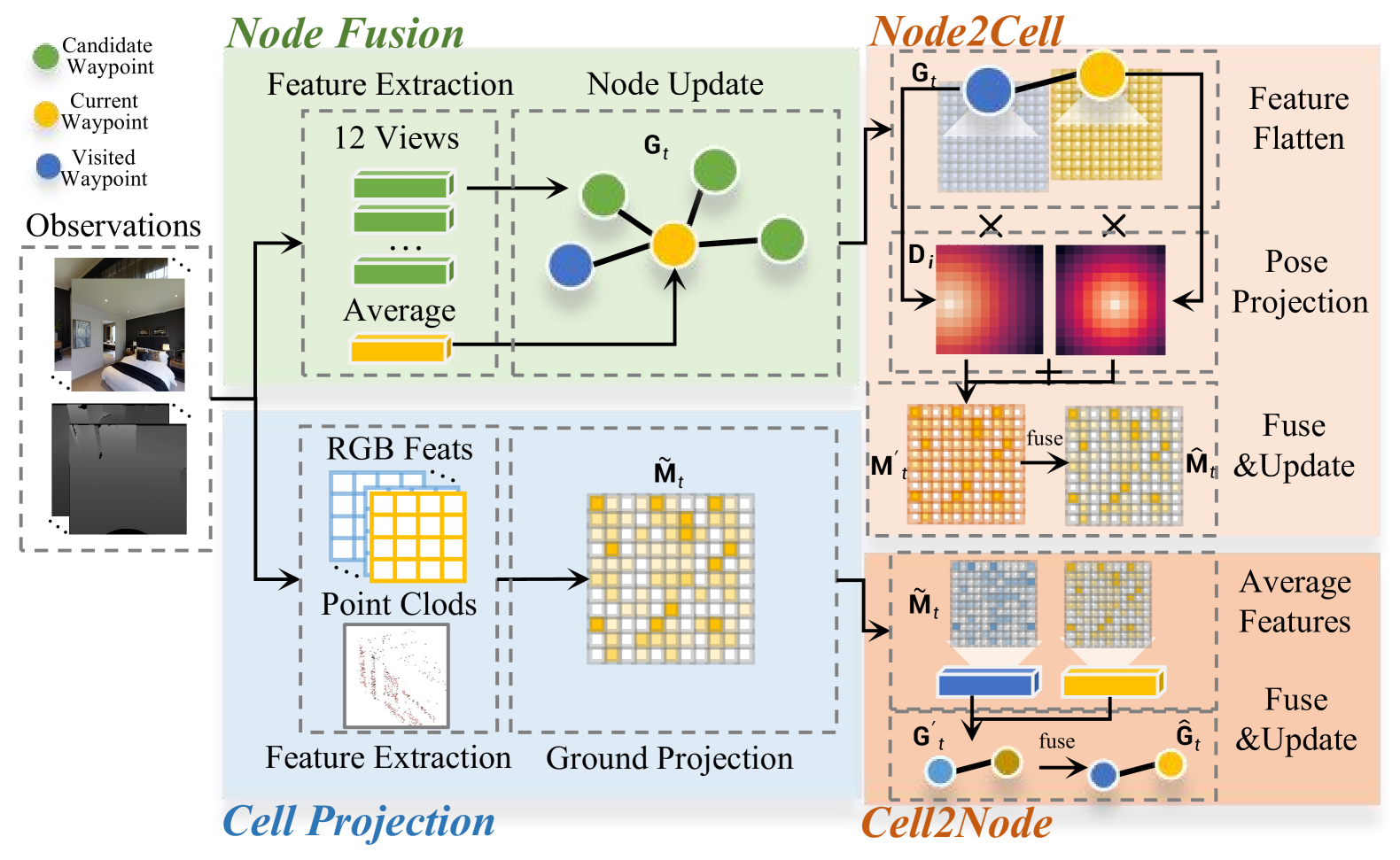
关键设计:HSTE模块使用拓扑图编码长期全局记忆,节点表示关键位置,边表示位置之间的连接关系。网格地图则用于捕获短期局部细节。MGAF模块使用几何感知知识融合,具体实现方式未知。VGWG模块生成引导注意力热图(GAHs),其生成方式和损失函数未知。预训练任务的具体内容未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ST-Booster在VLN-CE任务上取得了显著的性能提升,优于现有的最先进方法。具体性能数据和对比基线未知,但论文强调ST-Booster在复杂的、易受干扰的环境中表现尤为出色,证明了其在实际应用中的潜力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。通过提升智能体在复杂环境中的导航能力,可以实现更智能化的服务机器人、更安全的自动驾驶系统以及更逼真的虚拟现实体验。未来,该技术有望在物流、安防、医疗等领域发挥重要作用。
📄 摘要(原文)
Vision-and-Language Navigation in Continuous Environments (VLN-CE) requires agents to navigate unknown, continuous spaces based on natural language instructions. Compared to discrete settings, VLN-CE poses two core perception challenges. First, the absence of predefined observation points leads to heterogeneous visual memories and weakened global spatial correlations. Second, cumulative reconstruction errors in three-dimensional scenes introduce structural noise, impairing local feature perception. To address these challenges, this paper proposes ST-Booster, an iterative spatiotemporal booster that enhances navigation performance through multi-granularity perception and instruction-aware reasoning. ST-Booster consists of three key modules -- Hierarchical SpatioTemporal Encoding (HSTE), Multi-Granularity Aligned Fusion (MGAF), and ValueGuided Waypoint Generation (VGWG). HSTE encodes long-term global memory using topological graphs and captures shortterm local details via grid maps. MGAF aligns these dualmap representations with instructions through geometry-aware knowledge fusion. The resulting representations are iteratively refined through pretraining tasks. During reasoning, VGWG generates Guided Attention Heatmaps (GAHs) to explicitly model environment-instruction relevance and optimize waypoint selection. Extensive comparative experiments and performance analyses are conducted, demonstrating that ST-Booster outperforms existing state-of-the-art methods, particularly in complex, disturbance-prone environments.