Automatic Detection of Intro and Credits in Video using CLIP and Multihead Attention
作者: Vasilii Korolkov, Andrey Yanchenko
分类: cs.CV, cs.AI, cs.LG, cs.MM
发布日期: 2025-04-13
备注: 22 pages, 11 figures, submitted as a preprint. ArXiv preprint only, not submitted to a journal yet
💡 一句话要点
提出基于CLIP和多头注意力机制的视频片头片尾自动检测方法,提升内容理解效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频内容理解 片头片尾检测 CLIP模型 多头注意力机制 序列分类 深度学习 视频分析
📋 核心要点
- 视频片头片尾检测是内容理解的关键,但人工标注成本高昂,启发式方法泛化性差。
- 论文提出基于CLIP和多头注意力的序列分类方法,自动区分视频的片头片尾与正片内容。
- 实验结果表明,该方法在精度和速度上均表现出色,F1值达到91%,CPU上帧率达到11.5FPS。
📝 摘要(中文)
本文提出了一种基于深度学习的视频片头/片尾自动检测方法,旨在解决内容分割、索引和推荐系统中的关键问题。人工标注耗时且易出错,而基于启发式的方法泛化能力不足。该方法将问题定义为序列到序列的分类任务,将视频的每一秒标记为“片头/片尾”或“正片”。系统以1 FPS的固定速率提取帧,使用CLIP(对比语言-图像预训练)进行编码,并通过包含学习到的位置编码的多头注意力模型处理特征表示。在测试集上,该系统实现了91.0%的F1分数、89.0%的精确率和97.0%的召回率,并针对实时推理进行了优化,在CPU上达到11.5 FPS,在高端GPU上达到107 FPS。该方法在自动内容索引、高光检测和视频摘要方面具有实际应用价值。未来的工作将探索多模态学习,结合音频特征和字幕以进一步提高检测精度。
🔬 方法详解
问题定义:论文旨在解决视频内容理解中片头/片尾自动检测的问题。现有方法,如人工标注,成本高且容易出错;基于启发式规则的方法,难以适应各种视频风格,泛化能力较弱。因此,需要一种自动、高效且具有良好泛化能力的片头/片尾检测方法。
核心思路:论文的核心思路是将视频片头/片尾检测问题转化为一个序列到序列的分类问题。通过将视频分割成一系列帧,并对每一帧进行分类,判断其属于“片头/片尾”还是“正片”。利用CLIP模型提取视觉特征,并使用多头注意力机制捕捉视频帧之间的时序关系,从而实现准确的分类。
技术框架:该方法的技术框架主要包括三个阶段:1) 帧提取:以固定的帧率(1 FPS)从视频中提取帧。2) 特征编码:使用CLIP模型对每一帧进行编码,提取视觉特征。CLIP模型在大量图像-文本对上进行预训练,能够提取具有语义信息的图像特征。3) 序列分类:将提取的特征序列输入到多头注意力模型中,利用学习到的位置编码捕捉帧之间的时序关系,最终输出每一帧的分类结果(“片头/片尾”或“正片”)。
关键创新:该方法的关键创新在于将CLIP模型和多头注意力机制相结合,用于视频片头/片尾检测。CLIP模型能够提取具有语义信息的图像特征,而多头注意力机制能够有效地捕捉视频帧之间的时序关系。与传统的基于启发式规则的方法相比,该方法具有更强的泛化能力。
关键设计:在关键设计方面,论文采用了以下策略:1) 使用预训练的CLIP模型,避免了从头开始训练图像特征提取器。2) 使用多头注意力机制,能够并行地学习多个注意力权重,从而更好地捕捉视频帧之间的时序关系。3) 引入学习到的位置编码,为多头注意力模型提供帧的位置信息。4) 针对实时推理进行了优化,例如使用较小的模型和高效的计算实现。
🖼️ 关键图片
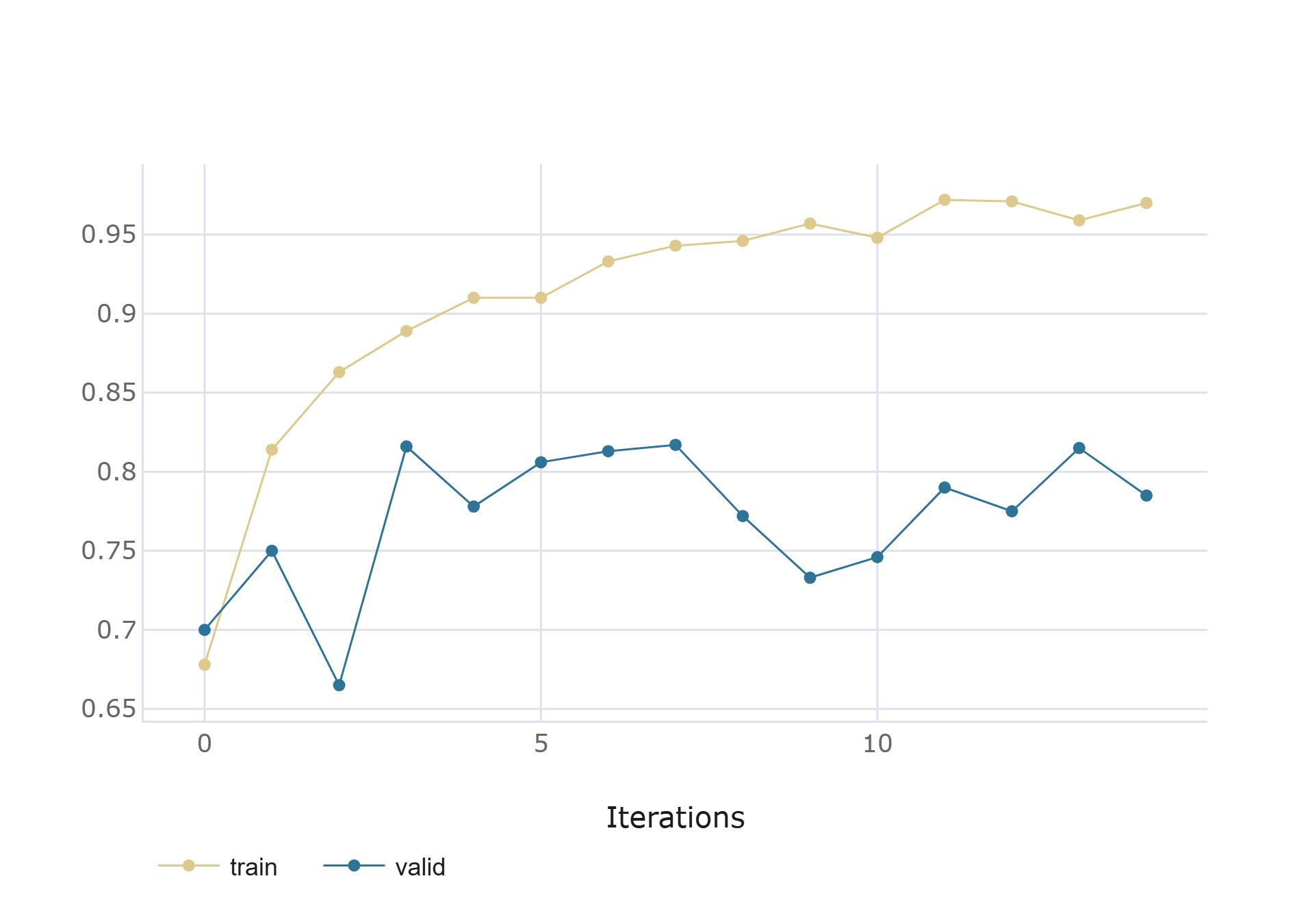

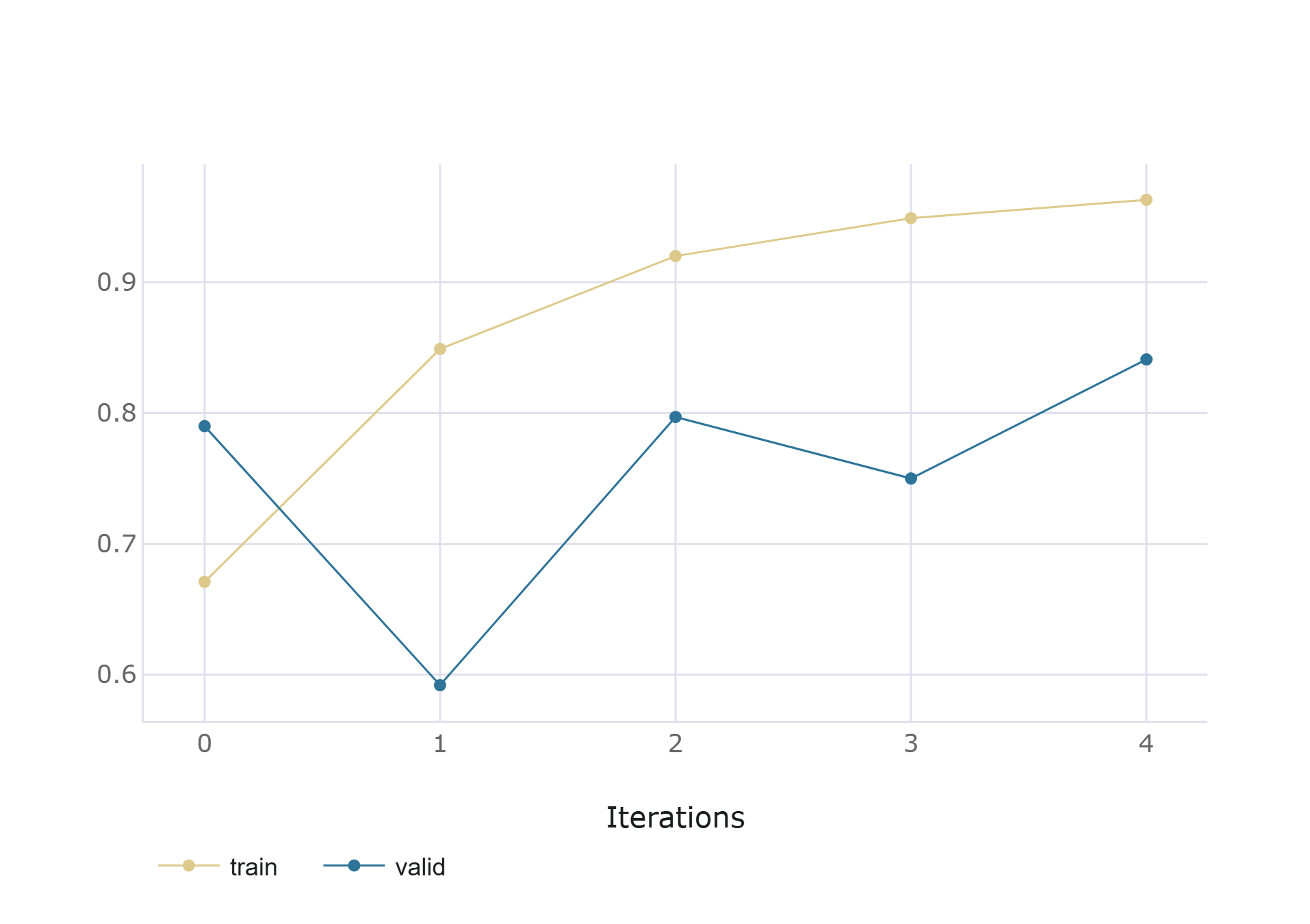
📊 实验亮点
该方法在测试集上取得了显著的性能提升,F1分数达到91.0%,精确率为89.0%,召回率为97.0%。同时,该方法针对实时推理进行了优化,在CPU上实现了11.5 FPS的处理速度,在高端GPU上更是达到了107 FPS,使其具备了实际应用的可能性。这些结果表明,该方法在准确性和效率方面均优于现有方法。
🎯 应用场景
该研究成果可广泛应用于视频内容理解领域,例如自动内容索引、高光时刻检测、视频摘要生成、以及视频推荐系统。通过自动识别视频的片头片尾,可以更精确地进行内容分割,提升用户体验,并为视频平台的内容管理和运营提供技术支持。未来,该技术有望应用于更复杂的视频分析任务,例如场景分割、人物识别和事件检测。
📄 摘要(原文)
Detecting transitions between intro/credits and main content in videos is a crucial task for content segmentation, indexing, and recommendation systems. Manual annotation of such transitions is labor-intensive and error-prone, while heuristic-based methods often fail to generalize across diverse video styles. In this work, we introduce a deep learning-based approach that formulates the problem as a sequence-to-sequence classification task, where each second of a video is labeled as either "intro" or "film." Our method extracts frames at a fixed rate of 1 FPS, encodes them using CLIP (Contrastive Language-Image Pretraining), and processes the resulting feature representations with a multihead attention model incorporating learned positional encoding. The system achieves an F1-score of 91.0%, Precision of 89.0%, and Recall of 97.0% on the test set, and is optimized for real-time inference, achieving 11.5 FPS on CPU and 107 FPS on high-end GPUs. This approach has practical applications in automated content indexing, highlight detection, and video summarization. Future work will explore multimodal learning, incorporating audio features and subtitles to further enhance detection accuracy.