TextSplat: Text-Guided Semantic Fusion for Generalizable Gaussian Splatting
作者: Zhicong Wu, Hongbin Xu, Gang Xu, Ping Nie, Zhixin Yan, Jinkai Zheng, Liangqiong Qu, Ming Li, Liqiang Nie
分类: cs.CV, cs.AI
发布日期: 2025-04-13 (更新: 2025-08-21)
💡 一句话要点
TextSplat:文本引导的语义融合,提升可泛化高斯溅射重建效果
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 可泛化高斯溅射 文本引导 语义融合 三维重建 跨模态学习
📋 核心要点
- 现有可泛化高斯溅射方法忽略了文本驱动的语义指导在提升复杂场景细粒度重建方面的潜力。
- TextSplat通过文本引导的语义融合,学习鲁棒的跨模态特征表示,从而改善了几何和语义信息的对齐。
- 实验结果表明,TextSplat在多个基准数据集上优于现有方法,验证了其有效性。
📝 摘要(中文)
本文提出TextSplat,一种文本驱动的可泛化高斯溅射框架,旨在通过文本引导的语义融合来增强三维重建的语义理解能力。现有方法侧重于几何一致性,忽略了文本驱动指导在提升复杂场景中细粒度细节重建方面的潜力。TextSplat利用三个并行模块获取互补表示:扩散先验深度估计器用于精确深度信息,语义感知分割网络用于详细语义信息,多视图交互网络用于精炼跨视图特征。随后,在文本引导的语义融合模块中,通过文本引导和基于注意力的特征聚合机制整合这些表示,从而增强了具有详细语义线索的三维高斯参数。在多个基准数据集上的实验结果表明,与现有方法相比,TextSplat在多个评估指标上均表现出改进的性能,验证了该框架的有效性。代码将会公开。
🔬 方法详解
问题定义:现有可泛化高斯溅射方法主要关注几何一致性,忽略了利用文本信息来指导语义理解,导致在复杂场景中重建细粒度细节时效果不佳。这些方法无法充分利用文本提供的上下文信息来提升三维重建的质量和准确性。
核心思路:TextSplat的核心思路是利用文本信息作为指导,融合来自不同模态的语义线索,从而增强三维高斯参数的语义表达能力。通过将文本信息融入到特征融合过程中,模型能够更好地理解场景的语义信息,从而重建出更精确、更细致的三维模型。
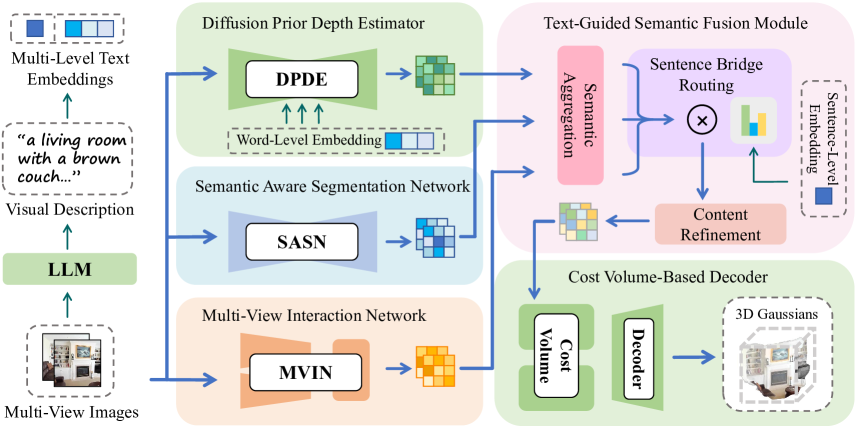
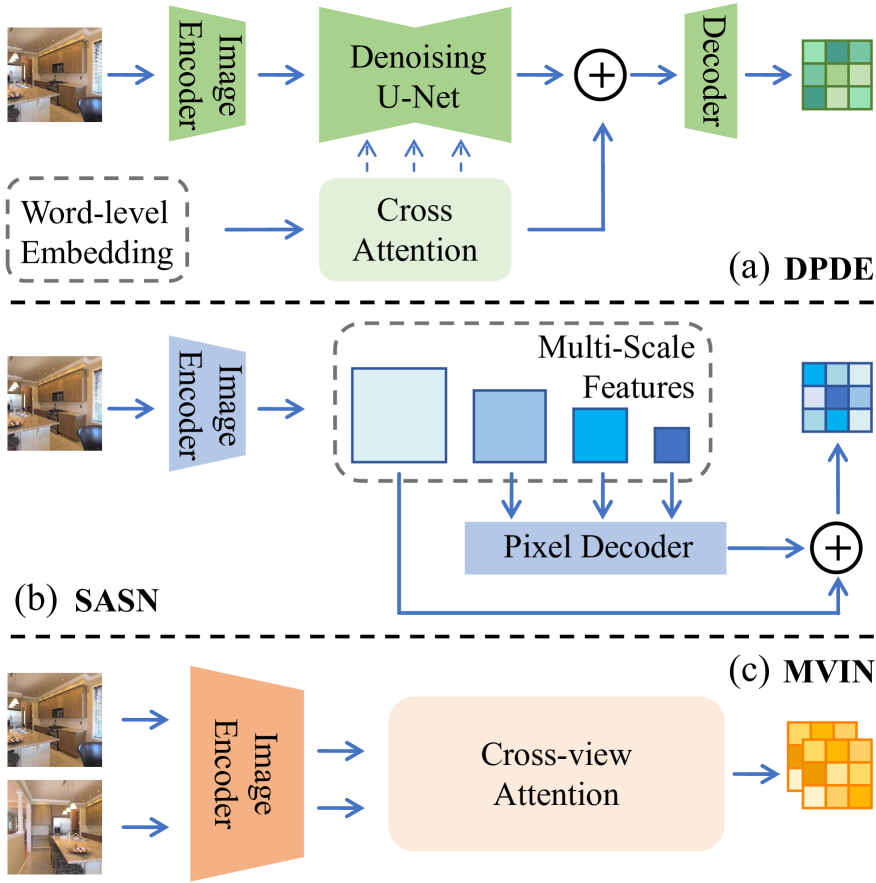
技术框架:TextSplat框架包含三个并行模块和一个文本引导的语义融合模块。三个并行模块分别是:扩散先验深度估计器,用于提供精确的深度信息;语义感知分割网络,用于提取详细的语义信息;多视图交互网络,用于精炼跨视图特征。文本引导的语义融合模块则负责将这三个模块的输出进行融合,生成增强的3D高斯参数。
关键创新:TextSplat的关键创新在于提出了文本引导的语义融合模块,该模块利用文本信息作为指导,通过基于注意力的特征聚合机制,将来自不同模态的特征进行融合。这种融合方式能够有效地利用文本信息来提升三维重建的语义理解能力,从而重建出更精确、更细致的三维模型。这是首次将文本信息引入到可泛化高斯溅射框架中。
关键设计:文本引导的语义融合模块是关键设计。该模块使用Transformer结构,将文本特征作为query,深度、语义分割和多视图特征作为key和value,通过注意力机制实现特征融合。损失函数包括重建损失、深度损失和语义分割损失,用于约束模型的输出。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
TextSplat在多个基准数据集上进行了实验,结果表明,与现有方法相比,TextSplat在多个评估指标上均表现出改进的性能。具体提升幅度未知,但实验结果验证了TextSplat框架的有效性,证明了文本引导的语义融合能够有效地提升三维重建的质量。
🎯 应用场景
TextSplat在三维场景重建、虚拟现实、增强现实、机器人导航等领域具有广泛的应用前景。它可以用于创建更逼真、更细致的虚拟环境,提升用户在虚拟现实和增强现实体验中的沉浸感。此外,TextSplat还可以用于机器人导航,帮助机器人更好地理解周围环境,从而实现更安全、更高效的导航。
📄 摘要(原文)
Recent advancements in Generalizable Gaussian Splatting have enabled robust 3D reconstruction from sparse input views by utilizing feed-forward Gaussian Splatting models, achieving superior cross-scene generalization. However, while many methods focus on geometric consistency, they often neglect the potential of text-driven guidance to enhance semantic understanding, which is crucial for accurately reconstructing fine-grained details in complex scenes. To address this limitation, we propose TextSplat--the first text-driven Generalizable Gaussian Splatting framework. By employing a text-guided fusion of diverse semantic cues, our framework learns robust cross-modal feature representations that improve the alignment of geometric and semantic information, producing high-fidelity 3D reconstructions. Specifically, our framework employs three parallel modules to obtain complementary representations: the Diffusion Prior Depth Estimator for accurate depth information, the Semantic Aware Segmentation Network for detailed semantic information, and the Multi-View Interaction Network for refined cross-view features. Then, in the Text-Guided Semantic Fusion Module, these representations are integrated via the text-guided and attention-based feature aggregation mechanism, resulting in enhanced 3D Gaussian parameters enriched with detailed semantic cues. Experimental results on various benchmark datasets demonstrate improved performance compared to existing methods across multiple evaluation metrics, validating the effectiveness of our framework. The code will be publicly available.