Vision-Language Model for Object Detection and Segmentation: A Review and Evaluation
作者: Yongchao Feng, Yajie Liu, Shuai Yang, Wenrui Cai, Jinqing Zhang, Qiqi Zhan, Ziyue Huang, Hongxi Yan, Qiao Wan, Chenguang Liu, Junzhe Wang, Jiahui Lv, Ziqi Liu, Tengyuan Shi, Qingjie Liu, Yunhong Wang
分类: cs.CV, cs.AI
发布日期: 2025-04-13
备注: A Review and Evaluation about Vision-Language Model for Object Detection and Segmentation
🔗 代码/项目: GITHUB
💡 一句话要点
系统性评测视觉-语言模型在目标检测与分割任务中的性能与局限性
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 目标检测 图像分割 开放词汇 模型评估
📋 核心要点
- 现有视觉-语言模型在开放词汇任务表现出色,但在传统视觉任务上的性能未被充分评估。
- 该研究将视觉-语言模型视为基础模型,并首次在多个下游检测和分割任务上进行全面评估。
- 通过系统性评估,揭示了不同VLM架构在各种任务中的优势与局限性,并分析了任务特性、模型架构和训练方法之间的关联。
📝 摘要(中文)
视觉-语言模型(VLM)已在开放词汇(OV)目标检测和分割任务中得到广泛应用。尽管它们在OV相关任务上表现出潜力,但它们在传统视觉任务中的有效性尚未得到评估。本文对基于VLM的检测和分割进行了系统性回顾,将VLM视为基础模型,并首次对多个下游任务进行了全面评估:1)评估涵盖八个检测场景(闭集检测、领域自适应、拥挤对象等)和八个分割场景(少样本、开放世界、小对象等),揭示了各种VLM架构在不同任务中的明显性能优势和局限性。2)对于检测任务,我们在三种微调粒度下评估VLM:零预测、视觉微调和文本提示,并进一步分析不同的微调策略如何影响不同任务下的性能。3)基于经验发现,我们深入分析了任务特征、模型架构和训练方法之间的相关性,为未来的VLM设计提供了见解。4)我们相信这项工作对于计算机视觉、多模态学习和视觉基础模型领域的模式识别专家来说是有价值的,因为它向他们介绍了问题,并使他们熟悉了当前的进展状况,同时为未来的研究提供了有希望的方向。
🔬 方法详解
问题定义:论文旨在评估视觉-语言模型(VLM)在传统目标检测和分割任务中的性能,并分析其优势和局限性。现有方法主要集中在开放词汇任务上,忽略了VLM在更广泛的视觉任务中的潜力,缺乏系统性的评估和比较。
核心思路:论文的核心思路是将VLM视为一个通用的基础模型,通过在多个不同的检测和分割场景下进行评估,来全面了解其性能。通过分析任务特性、模型架构和训练方法之间的关系,为未来的VLM设计提供指导。
技术框架:该研究的技术框架主要包括以下几个部分:1)选择具有代表性的VLM模型;2)构建包含多种检测和分割场景的评估数据集;3)设计不同的微调策略(零预测、视觉微调、文本提示);4)进行实验评估,并分析结果。
关键创新:该研究的关键创新在于首次对VLM在传统视觉任务中进行了系统性的评估,并深入分析了任务特性、模型架构和训练方法之间的关系。通过这种全面的评估,揭示了VLM在不同任务中的优势和局限性,为未来的VLM设计提供了有价值的见解。
关键设计:在检测任务中,论文评估了三种微调粒度:零预测(zero-shot)、视觉微调(visual fine-tuning)和文本提示(text prompt)。针对不同的任务,选择了合适的评估指标。例如,在闭集检测任务中,使用了标准的mAP指标;在领域自适应任务中,使用了跨域的mAP指标。具体模型架构和训练细节未在摘要中详细说明,需参考原文。
🖼️ 关键图片
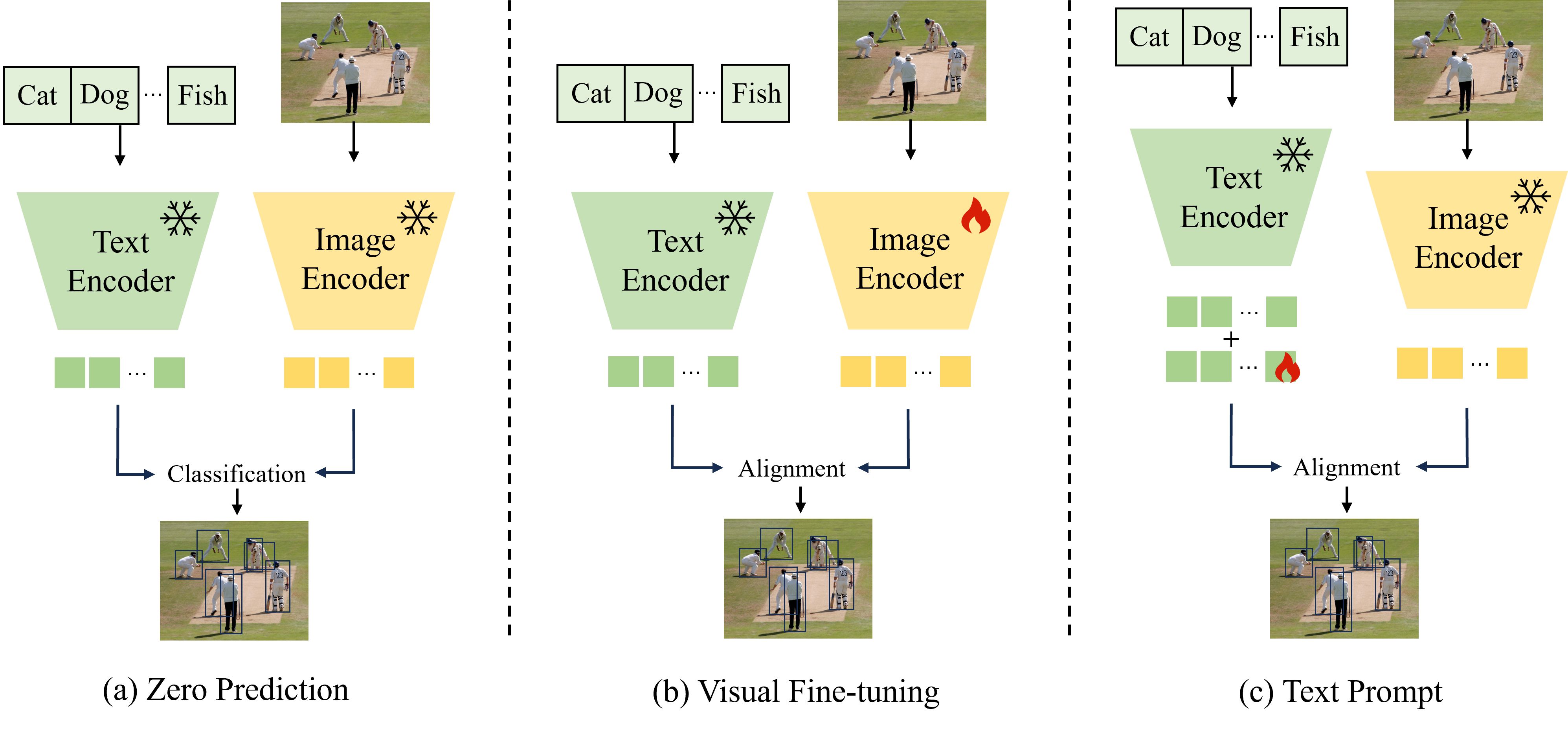
📊 实验亮点
该研究在八个检测场景和八个分割场景中进行了全面的评估,揭示了不同VLM架构在不同任务中的性能差异。例如,在领域自适应任务中,某些VLM模型表现出较好的泛化能力;而在小目标检测任务中,VLM模型的性能相对较差。通过对比不同的微调策略,发现视觉微调通常能够带来更好的性能提升。
🎯 应用场景
该研究成果可应用于更广泛的视觉任务中,例如智能监控、自动驾驶、医学图像分析等。通过深入了解VLM的性能和局限性,可以更好地选择和优化VLM模型,从而提高视觉任务的性能和效率。未来的研究可以基于该评估结果,设计更有效的VLM模型和训练方法。
📄 摘要(原文)
Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.