VideoAds for Fast-Paced Video Understanding
作者: Zheyuan Zhang, Monica Dou, Linkai Peng, Hongyi Pan, Ulas Bagci, Boqing Gong
分类: cs.CV
发布日期: 2025-04-12 (更新: 2025-10-13)
备注: ICCV2025
💡 一句话要点
VideoAds:用于快节奏视频理解的多模态大语言模型基准数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视频理解 广告视频 基准数据集 时序建模
📋 核心要点
- 现有的多模态大语言模型在理解快节奏、高信息密度的广告视频方面面临挑战,缺乏专门的评估基准。
- VideoAds数据集通过提供人工标注的广告视频,涵盖视觉查找、视频摘要和视觉推理三个任务,旨在弥补这一差距。
- 实验表明,开源模型Qwen2.5-VL-72B在VideoAds上表现优于GPT-4o和Gemini-1.5 Pro,但与人类专家相比仍有差距。
📝 摘要(中文)
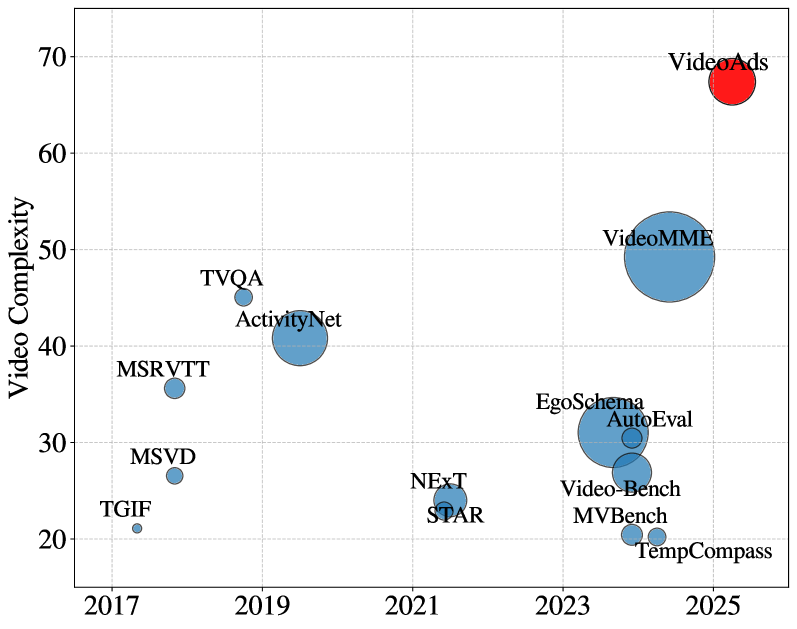
本文介绍VideoAds,这是第一个专门用于评估多模态大语言模型(MLLM)在广告视频上性能的数据集。广告视频包含高质量的视觉、文本和上下文线索,旨在吸引观众,因此信息丰富且有价值。由于其结构化的叙事和快速的场景转换,广告视频通常比类似时长的普通视频更复杂,这对MLLM提出了重大挑战。VideoAds包含精心策划的广告视频,具有复杂的时序结构,并附带人工标注的各种问题,涵盖三个核心任务:视觉查找、视频摘要和视觉推理。本文提出了一种定量方法,用于比较VideoAds与现有基准在视频复杂度方面的差异。通过大量实验发现,开源MLLM Qwen2.5-VL-72B在VideoAds上实现了73.35%的准确率,优于GPT-4o(66.82%)和Gemini-1.5 Pro(69.66%)。特别是,两个专有模型在视频摘要和推理方面落后于开源模型,但在视觉查找方面表现最佳。值得注意的是,人类专家可以轻松达到94.27%的卓越准确率。这些结果强调了提高MLLM时序建模能力的必要性,并突出了VideoAds作为未来研究理解需要高FPS采样的视频的关键基准的潜力。数据集和评估代码将在https://videoadsbenchmark.netlify.app公开。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在理解快节奏、高信息密度的广告视频时面临的挑战。现有方法缺乏针对此类视频的专门评估基准,导致模型性能难以有效衡量和提升。广告视频具有结构化的叙事和快速的场景转换,对MLLM的时序建模能力提出了更高的要求。
核心思路:论文的核心思路是构建一个高质量的广告视频数据集VideoAds,并设计相应的评估任务,以全面评估MLLM在理解此类视频方面的能力。通过人工标注,确保数据集包含多样化的问题,涵盖视觉查找、视频摘要和视觉推理等关键方面。
技术框架:VideoAds数据集包含精心策划的广告视频,并附带人工标注的问答对。评估流程包括:1) 将视频输入MLLM;2) MLLM根据视频内容回答问题;3) 将MLLM的答案与人工标注的答案进行比较,计算准确率。数据集还提供了一种定量方法,用于比较VideoAds与现有基准在视频复杂度方面的差异。
关键创新:该论文的主要创新在于构建了首个专门用于评估MLLM在广告视频上性能的基准数据集VideoAds。该数据集的特点是包含复杂的时序结构和人工标注的多样化问题,能够更全面地评估MLLM的时序建模能力和多模态理解能力。
关键设计:VideoAds数据集包含三个核心任务:视觉查找、视频摘要和视觉推理。每个任务都设计了相应的问答对,以评估MLLM在不同方面的能力。数据集还提供了一种定量方法,用于衡量视频的复杂度,例如场景转换的频率和信息密度。此外,论文还采用了准确率作为评估指标,以衡量MLLM的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,开源模型Qwen2.5-VL-72B在VideoAds数据集上取得了73.35%的准确率,优于GPT-4o(66.82%)和Gemini-1.5 Pro(69.66%)。然而,与人类专家(94.27%)相比,MLLM的性能仍有提升空间,尤其是在视频摘要和推理方面。这表明,提高MLLM的时序建模能力是未来研究的重要方向。
🎯 应用场景
VideoAds数据集可用于训练和评估多模态大语言模型在理解快节奏、高信息密度视频方面的能力。这对于广告推荐、视频内容分析、智能客服等领域具有重要意义。未来,该数据集可以扩展到其他类型的快节奏视频,例如体育赛事集锦和音乐视频,从而推动视频理解技术的进一步发展。
📄 摘要(原文)
Advertisement videos serve as a rich and valuable source of purpose-driven information, encompassing high-quality visual, textual, and contextual cues designed to engage viewers. They are often more complex than general videos of similar duration due to their structured narratives and rapid scene transitions, posing significant challenges to multi-modal large language models (MLLMs). In this work, we introduce VideoAds, the first dataset tailored for benchmarking the performance of MLLMs on advertisement videos. VideoAds comprises well-curated advertisement videos with complex temporal structures, accompanied by \textbf{manually} annotated diverse questions across three core tasks: visual finding, video summary, and visual reasoning. We propose a quantitative measure to compare VideoAds against existing benchmarks in terms of video complexity. Through extensive experiments, we find that Qwen2.5-VL-72B, an opensource MLLM, achieves 73.35\% accuracy on VideoAds, outperforming GPT-4o (66.82\%) and Gemini-1.5 Pro (69.66\%); the two proprietary models especially fall behind the opensource model in video summarization and reasoning, but perform the best in visual finding. Notably, human experts easily achieve a remarkable accuracy of 94.27\%. These results underscore the necessity of advancing MLLMs' temporal modeling capabilities and highlight VideoAds as a potentially pivotal benchmark for future research in understanding video that requires high FPS sampling. The dataset and evaluation code will be publicly available at https://videoadsbenchmark.netlify.app.