PathVLM-R1: A Reinforcement Learning-Driven Reasoning Model for Pathology Visual-Language Tasks
作者: Jianyu Wu, Hao Yang, Xinhua Zeng, Guibing He, Zhiyu Chen, Zihui Li, Xiaochuan Zhang, Yangyang Ma, Run Fang, Yang Liu
分类: cs.CV, cs.MM
发布日期: 2025-04-12 (更新: 2025-04-18)
💡 一句话要点
PathVLM-R1:基于强化学习的病理视觉语言推理模型,提升诊断准确性和泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 病理图像 视觉语言模型 强化学习 推理模型 医学诊断
📋 核心要点
- 现有病理视觉语言模型缺乏有效的推理能力,且监督过程不足,影响了诊断的可靠性。
- PathVLM-R1通过监督微调赋予模型病理知识,并利用强化学习优化推理过程,提升模型性能。
- 实验表明,PathVLM-R1在病理图像问答任务中准确率提升14%,且域外数据迁移性能显著提高。
📝 摘要(中文)
病理图像诊断常受限于专家资源和区域差异,因此利用视觉语言模型(VLM)实现自动化诊断至关重要。传统多模态模型通常侧重于结果而非推理过程,影响临床决策的可靠性。为解决病理VLM中推理能力薄弱和缺乏监督过程的问题,我们创新性地提出了PathVLM-R1,一种专为病理图像设计的视觉语言模型。该模型基于Qwen2.5-VL-7B-Instruct,并通过精心设计的后训练策略增强其在病理任务中的性能。首先,我们进行病理数据引导的监督微调,使模型具备基础病理知识,形成新的病理基础模型。其次,我们引入了组相对策略优化(GRPO),并提出了一种双重奖励驱动的强化学习优化,通过跨模态过程奖励和结果准确性奖励,严格约束推理过程的逻辑监督和结果准确性。在病理图像问答任务中,PathVLM-R1的测试结果显示,与基线方法相比,准确率提高了14%,并且在参数规模显著较小的情况下,表现优于Qwen2.5-VL-32B版本。此外,在涉及四种医学成像模式(计算机断层扫描(CT)、皮肤镜检查、眼底摄影和光学相干断层扫描(OCT))的域外数据评估中,PathVLM-R1的迁移性能比传统的SFT方法平均提高了17.3%。这些结果清楚地表明,PathVLM-R1不仅提高了准确性,而且具有广泛的适用性和扩展潜力。
🔬 方法详解
问题定义:病理图像的自动诊断面临推理能力不足和缺乏有效监督的问题。现有视觉语言模型在病理图像理解和推理方面表现欠佳,难以提供可靠的临床决策支持。传统方法侧重于结果预测,忽略了推理过程的逻辑性和可解释性,导致模型在复杂病理案例中容易出错。
核心思路:PathVLM-R1的核心思路是结合监督学习和强化学习,构建一个具有强大推理能力的病理视觉语言模型。首先通过监督微调赋予模型病理领域的先验知识,然后利用强化学习优化模型的推理过程,使其能够更准确、更可靠地进行病理诊断。这种结合的方式旨在弥补传统方法在推理和监督方面的不足。
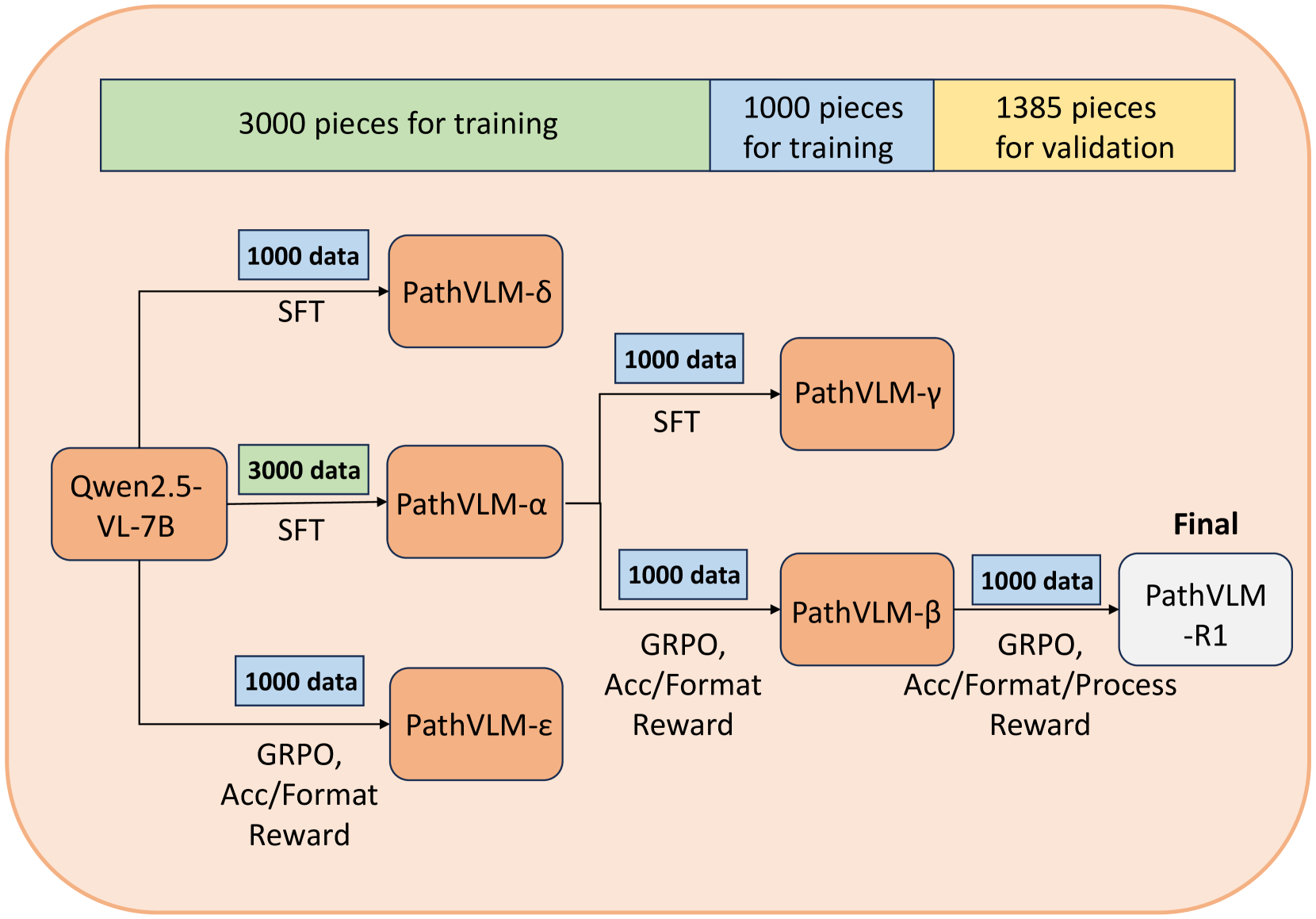
技术框架:PathVLM-R1基于Qwen2.5-VL-7B-Instruct模型,主要包含两个阶段:监督微调(SFT)和强化学习优化(RL)。在SFT阶段,使用病理图像数据对模型进行微调,使其具备基础的病理知识。在RL阶段,引入组相对策略优化(GRPO)和双重奖励机制,通过跨模态过程奖励和结果准确性奖励来指导模型的推理过程。整体流程是先通过SFT构建病理基础模型,再通过RL进一步提升其推理能力和泛化性能。
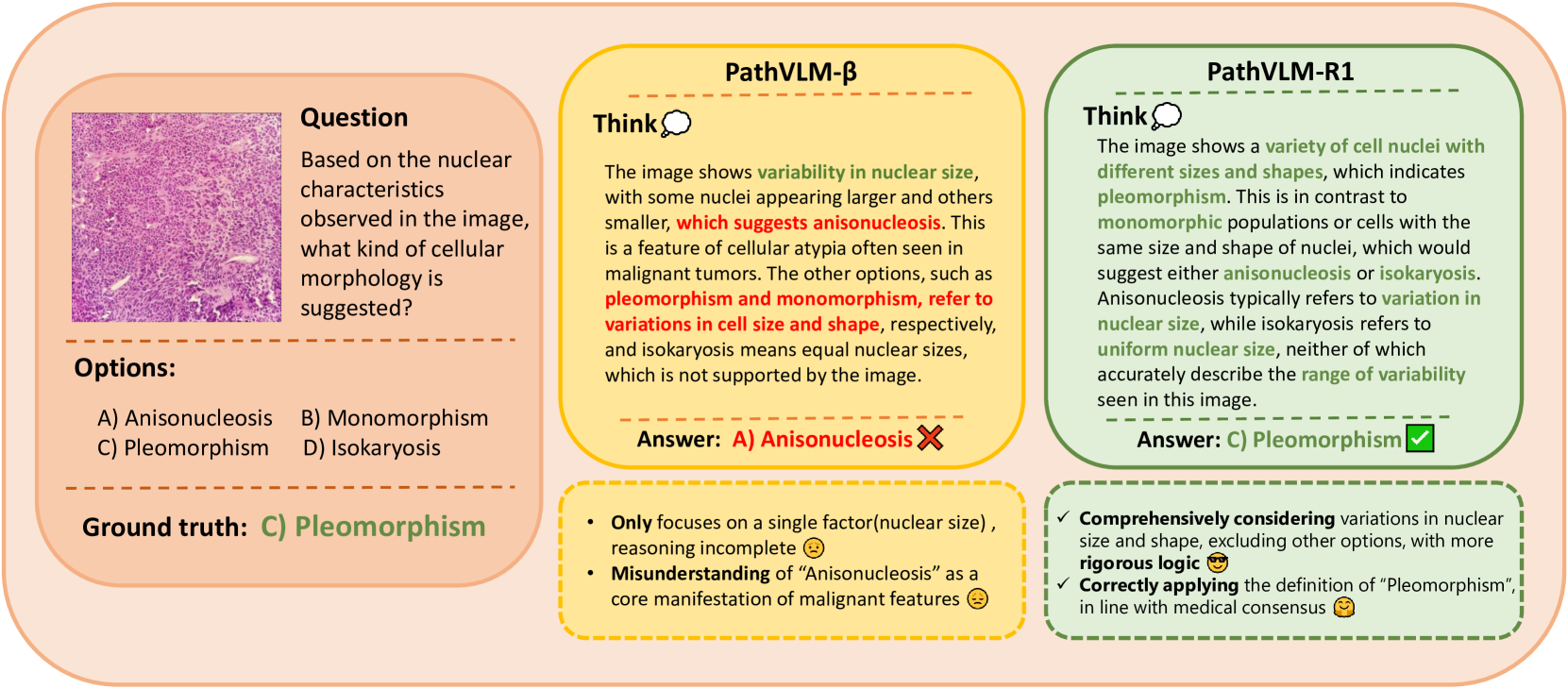
关键创新:PathVLM-R1的关键创新在于引入了双重奖励驱动的强化学习优化方法,并结合组相对策略优化(GRPO)。传统的强化学习方法通常只关注最终结果的奖励,而忽略了推理过程的逻辑性和可解释性。PathVLM-R1通过引入跨模态过程奖励,鼓励模型生成符合逻辑的推理步骤,从而提高诊断的可靠性。GRPO则进一步提升了策略学习的效率和稳定性。
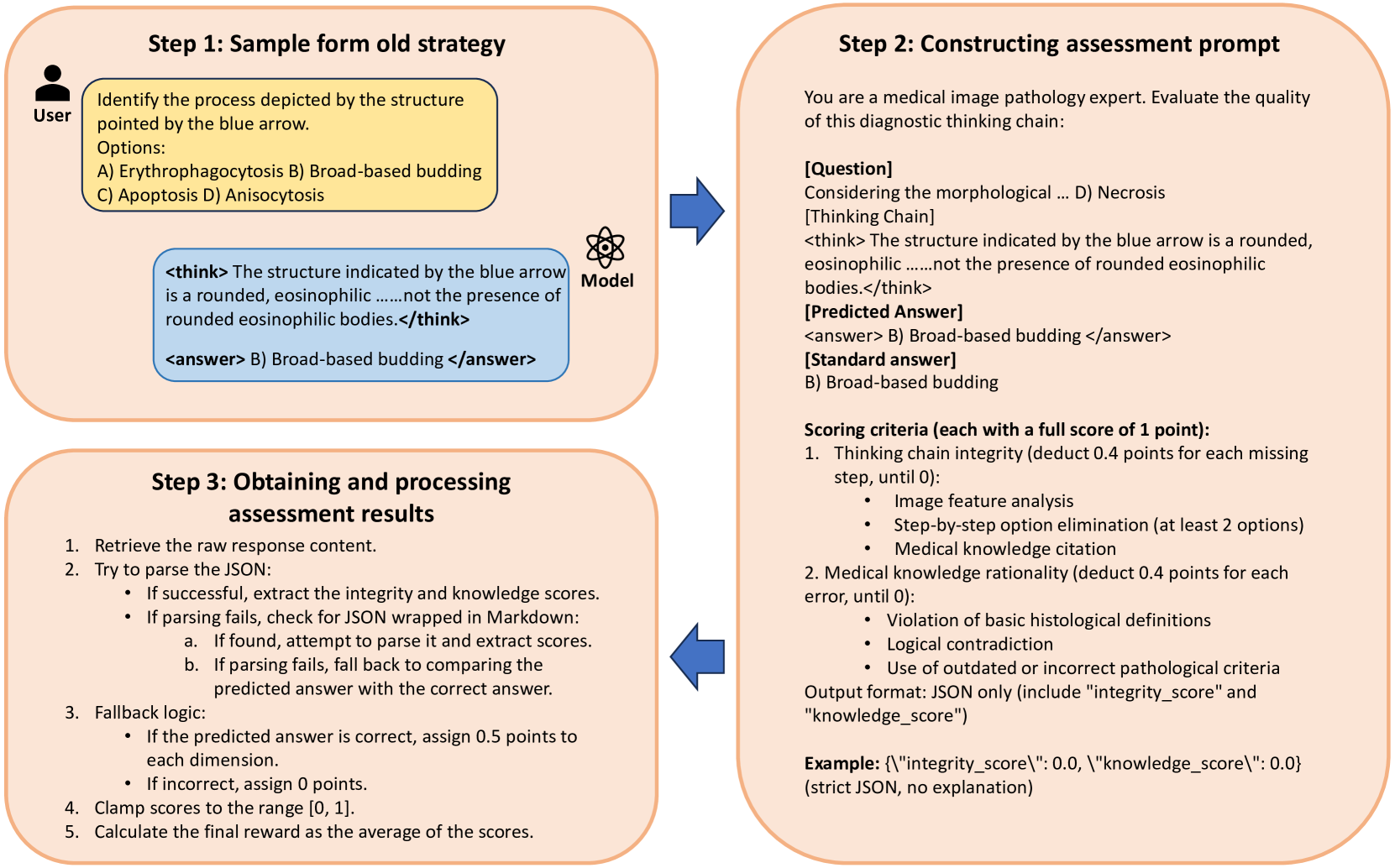
关键设计:在强化学习阶段,设计了跨模态过程奖励和结果准确性奖励。跨模态过程奖励基于文本和图像之间的对齐程度,鼓励模型生成与图像内容相关的推理步骤。结果准确性奖励则基于最终诊断结果的准确性。此外,GRPO通过对策略梯度进行归一化,减少了不同组别之间的差异,提高了策略学习的稳定性。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
PathVLM-R1在病理图像问答任务中,相比基线方法准确率提升了14%,并且在参数量远小于Qwen2.5-VL-32B的情况下,取得了更优的性能。在域外数据评估中,PathVLM-R1的迁移性能比传统SFT方法平均提高了17.3%,表明该模型具有良好的泛化能力和应用潜力。
🎯 应用场景
PathVLM-R1可应用于病理图像的自动诊断、辅助诊断和远程会诊等场景。该模型能够帮助病理医生提高诊断效率和准确性,尤其是在资源匮乏地区,可以缓解专家不足的问题。此外,该模型还可用于医学教育和研究,为病理学学习者提供辅助工具,并为病理学研究者提供新的研究思路。
📄 摘要(原文)
The diagnosis of pathological images is often limited by expert availability and regional disparities, highlighting the importance of automated diagnosis using Vision-Language Models (VLMs). Traditional multimodal models typically emphasize outcomes over the reasoning process, compromising the reliability of clinical decisions. To address the weak reasoning abilities and lack of supervised processes in pathological VLMs, we have innovatively proposed PathVLM-R1, a visual language model designed specifically for pathological images. We have based our model on Qwen2.5-VL-7B-Instruct and enhanced its performance for pathological tasks through meticulously designed post-training strategies. Firstly, we conduct supervised fine-tuning guided by pathological data to imbue the model with foundational pathological knowledge, forming a new pathological base model. Subsequently, we introduce Group Relative Policy Optimization (GRPO) and propose a dual reward-driven reinforcement learning optimization, ensuring strict constraint on logical supervision of the reasoning process and accuracy of results via cross-modal process reward and outcome accuracy reward. In the pathological image question-answering tasks, the testing results of PathVLM-R1 demonstrate a 14% improvement in accuracy compared to baseline methods, and it demonstrated superior performance compared to the Qwen2.5-VL-32B version despite having a significantly smaller parameter size. Furthermore, in out-domain data evaluation involving four medical imaging modalities: Computed Tomography (CT), dermoscopy, fundus photography, and Optical Coherence Tomography (OCT) images: PathVLM-R1's transfer performance improved by an average of 17.3% compared to traditional SFT methods. These results clearly indicate that PathVLM-R1 not only enhances accuracy but also possesses broad applicability and expansion potential.