FVQ: A Large-Scale Dataset and an LMM-based Method for Face Video Quality Assessment
作者: Sijing Wu, Yunhao Li, Ziwen Xu, Yixuan Gao, Huiyu Duan, Wei Sun, Guangtao Zhai
分类: cs.CV
发布日期: 2025-04-12 (更新: 2025-10-05)
备注: Accepted by ACM MM 2025. Project page: https://github.com/wsj-sjtu/FVQ
💡 一句话要点
提出大规模人脸视频质量评估数据集FVQ-20K及基于LMM的评估方法FVQ-Rater
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人脸视频质量评估 大规模数据集 多模态模型 指令微调 LoRA 视频质量评估 FVQA FVQ-20K
📋 核心要点
- 现有方法缺乏大规模真实人脸视频质量评估数据集,限制了FVQA的研究进展。
- FVQ-Rater利用大型多模态模型,提取多维特征并进行指令微调,实现类人评分。
- 实验表明,FVQ-20K数据集和FVQ-Rater方法在FVQA任务上表现出显著的潜力。
📝 摘要(中文)
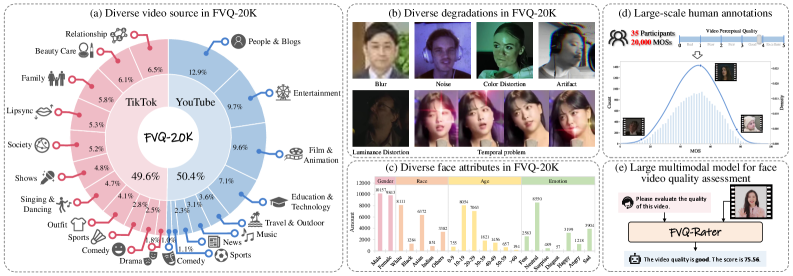
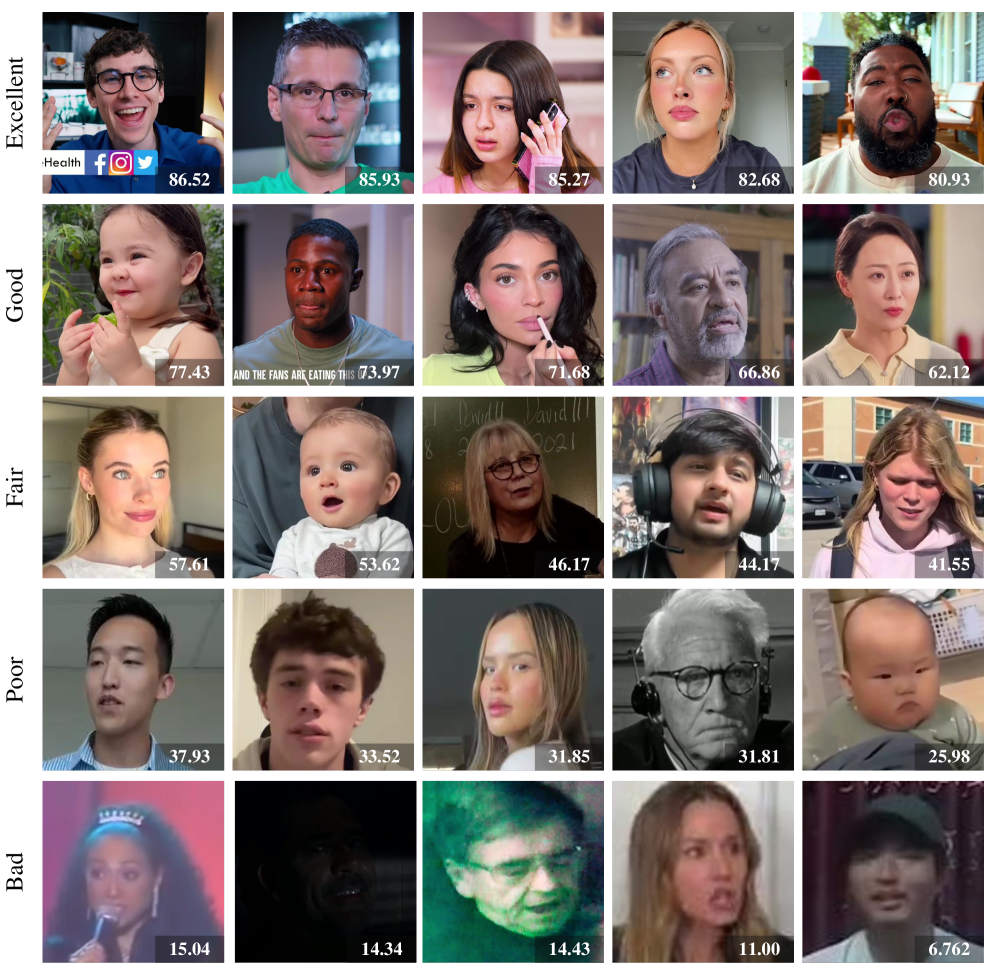
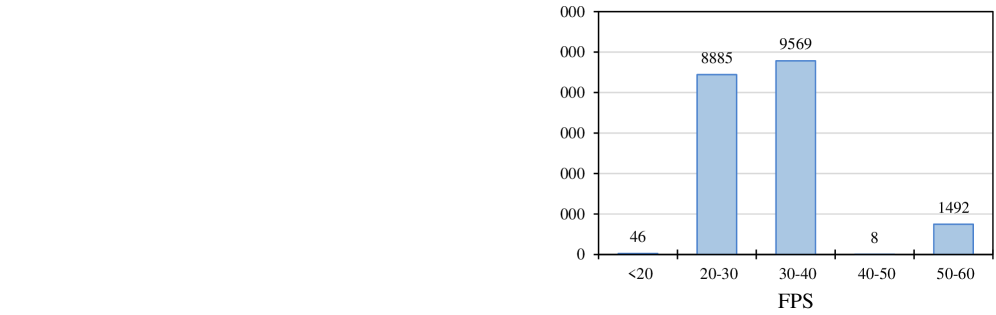
人脸视频质量评估(FVQA)值得深入研究,因为它与通用视频质量评估(VQA)不同,人脸视频是社交媒体平台上的主要内容,并且人类视觉系统(HVS)对人脸特别敏感。然而,由于缺乏大规模的FVQA数据集,FVQA很少被探索。为了填补这一空白,我们提出了第一个大规模的真实场景FVQA数据集FVQ-20K,其中包含20,000个真实场景的人脸视频以及相应的平均意见得分(MOS)注释。伴随FVQ-20K数据集,我们进一步提出了一种专门的FVQA方法,名为FVQ-Rater,以实现人脸视频类人评分和打分,这是首次尝试探索大型多模态模型(LMM)在FVQA任务中的潜力。具体而言,我们精心提取多维特征,包括空间特征、时间特征和人脸特定特征(即,肖像特征和人脸嵌入)以提供全面的视觉信息,并利用基于LoRA的指令调优技术来实现质量特定的微调,这在FVQ-20K和CFVQA数据集上都表现出卓越的性能。广泛的实验和全面的分析表明了FVQ-20K数据集和FVQ-Rater方法在促进FVQA发展方面的巨大潜力。
🔬 方法详解
问题定义:论文旨在解决人脸视频质量评估(FVQA)问题。现有方法缺乏大规模的真实场景数据集,难以训练出鲁棒性强、泛化能力好的FVQA模型。此外,如何有效利用多模态信息(如空间、时间、人脸特征)进行质量评估也是一个挑战。
核心思路:论文的核心思路是构建一个大规模的FVQA数据集(FVQ-20K),并提出一种基于大型多模态模型(LMM)的FVQA方法(FVQ-Rater)。通过多维特征提取和指令微调,使模型能够像人类一样对人脸视频的质量进行评分。
技术框架:FVQ-Rater的整体框架包括以下几个主要模块:1) 多维特征提取:提取空间特征、时间特征和人脸特定特征(肖像特征和人脸嵌入)。2) 基于LoRA的指令微调:利用LoRA技术对大型多模态模型进行微调,使其能够根据指令对人脸视频质量进行评分。3) 质量评分:根据微调后的模型输出,得到人脸视频的质量评分。
关键创新:该论文的关键创新在于:1) 构建了第一个大规模的真实场景FVQA数据集FVQ-20K。2) 首次尝试将大型多模态模型应用于FVQA任务,并提出了FVQ-Rater方法。3) 采用基于LoRA的指令微调技术,有效提升了模型的性能。与现有方法相比,该方法能够更好地利用多模态信息,实现更准确的人脸视频质量评估。
关键设计:在特征提取方面,论文采用了多种技术来提取不同类型的特征。例如,使用卷积神经网络提取空间特征,使用循环神经网络提取时间特征,使用预训练的人脸识别模型提取人脸嵌入。在指令微调方面,论文设计了合适的指令模板,并调整了LoRA的参数,以获得最佳的性能。损失函数采用均方误差损失函数,优化器采用AdamW优化器。
🖼️ 关键图片
📊 实验亮点
FVQ-Rater在FVQ-20K和CFVQA数据集上都取得了优异的性能。具体来说,在FVQ-20K数据集上,FVQ-Rater的性能显著优于现有的VQA方法。实验结果表明,FVQ-Rater能够有效地利用多模态信息,实现更准确的人脸视频质量评估。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、视频监控系统的人脸识别质量评估、视频会议软件的图像质量优化等领域。高质量的人脸视频有助于提升用户体验,提高人脸识别的准确率,并为相关应用提供更好的视觉基础。未来,该研究可进一步扩展到其他类型的视频质量评估任务中。
📄 摘要(原文)
Face video quality assessment (FVQA) deserves to be explored in addition to general video quality assessment (VQA), as face videos are the primary content on social media platforms and human visual system (HVS) is particularly sensitive to human faces. However, FVQA is rarely explored due to the lack of large-scale FVQA datasets. To fill this gap, we present the first large-scale in-the-wild FVQA dataset, FVQ-20K, which contains 20,000 in-the-wild face videos together with corresponding mean opinion score (MOS) annotations. Along with the FVQ-20K dataset, we further propose a specialized FVQA method named FVQ-Rater to achieve human-like rating and scoring for face video, which is the first attempt to explore the potential of large multimodal models (LMMs) for the FVQA task. Concretely, we elaborately extract multi-dimensional features including spatial features, temporal features, and face-specific features (i.e., portrait features and face embeddings) to provide comprehensive visual information, and take advantage of the LoRA-based instruction tuning technique to achieve quality-specific fine-tuning, which shows superior performance on both FVQ-20K and CFVQA datasets. Extensive experiments and comprehensive analysis demonstrate the significant potential of the FVQ-20K dataset and FVQ-Rater method in promoting the development of FVQA.