Parameter-Free Fine-tuning via Redundancy Elimination for Vision Foundation Models
作者: Jiahuan Long, Tingsong Jiang, Wen Yao, Yizhe Xiong, Zhengqin Xu, Shuai Jia, Hanqing Liu, Chao Ma
分类: cs.CV, cs.AI
发布日期: 2025-04-11 (更新: 2025-11-09)
备注: Accepted by AAAI 2026
💡 一句话要点
提出基于冗余消除的免参数微调方法,用于视觉基础模型适应下游任务
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础模型 免参数微调 冗余消除 通道选择 特征重用
📋 核心要点
- 现有视觉基础模型微调方法需要更新大量参数,计算成本高昂,且容易过拟合。
- 该论文提出一种免参数微调方法,通过选择、重用和增强预训练特征来适应下游任务。
- 实验表明,该方法在图像分割、深度估计和图像分类等任务上有效,且能与现有微调策略集成。
📝 摘要(中文)
视觉基础模型(VFMs)在学习通用视觉表示方面表现出卓越的能力。然而,将这些模型适配到下游任务通常需要参数更新,即使是参数高效的微调方法也需要修改数千到数百万个权重。本文研究了分割一切模型(SAM)中的冗余,并提出了一种新颖的免参数微调方法。与调整参数的传统微调方法不同,我们的方法强调选择、重用和增强预训练特征,为微调基础模型提供了一个新的视角。具体来说,我们引入了一种基于模型输出差异的通道选择算法,以识别冗余和有效的通道。通过选择性地用更有效的通道替换冗余通道,我们过滤掉不太有用的特征,并将更多与任务无关的特征重用到下游任务,从而增强特定于任务的特征表示。在领域外和领域内数据集上的实验表明,我们的方法在不同的视觉任务(例如,图像分割、深度估计和图像分类)中具有效率和有效性。值得注意的是,我们的方法可以与现有的微调策略(例如,LoRA、Adapter)无缝集成,进一步提高已经微调的模型的性能。此外,由于我们的通道选择仅涉及模型推理,因此我们的方法显著降低了GPU内存开销。
🔬 方法详解
问题定义:现有视觉基础模型微调方法,即使是参数高效的方法,仍然需要更新大量的模型参数,这导致计算资源消耗大,微调过程耗时,并且在数据量较小的下游任务上容易出现过拟合现象。因此,如何高效地将视觉基础模型适配到下游任务,同时避免参数更新带来的问题,是一个重要的研究问题。
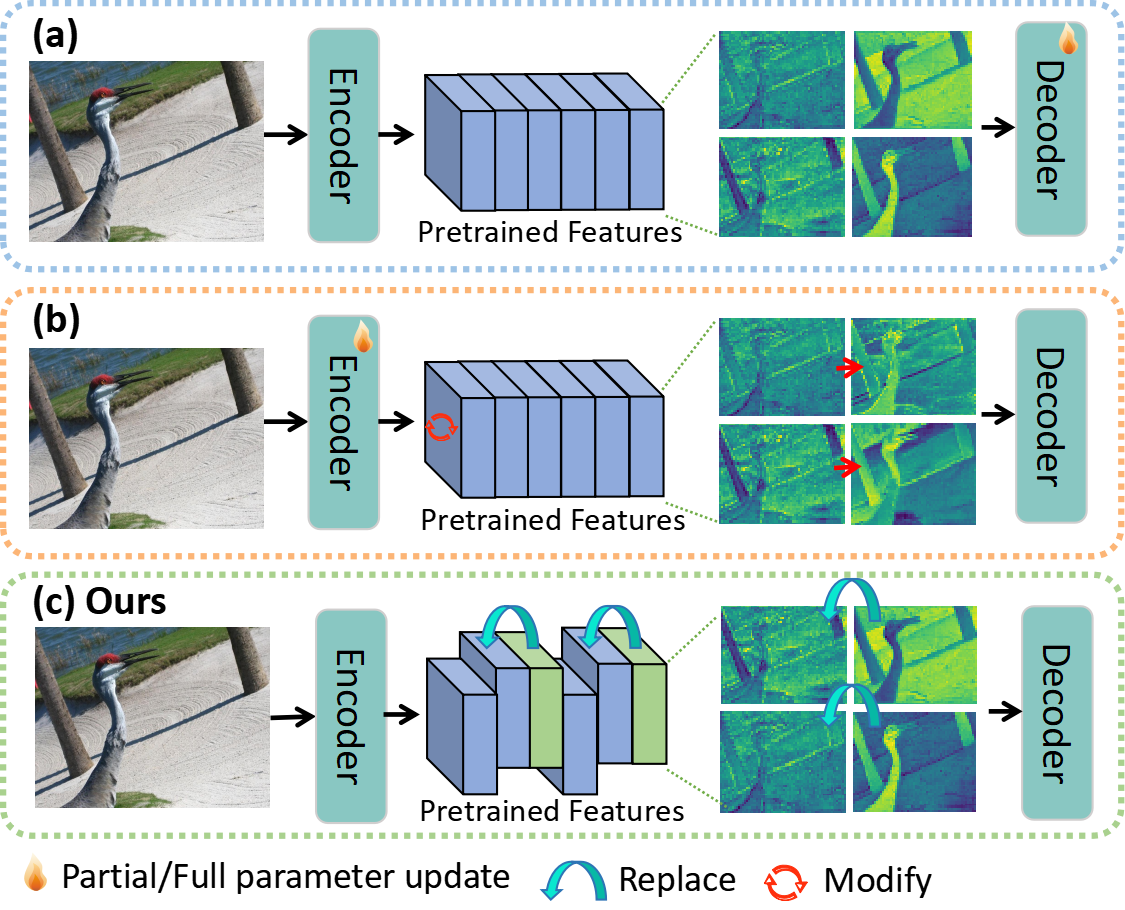
核心思路:该论文的核心思路是,视觉基础模型中存在冗余的特征通道,这些通道对于特定下游任务的贡献较小。通过识别并替换这些冗余通道,可以有效地增强模型对下游任务的适应性,而无需修改模型的任何参数。这种方法的核心在于选择、重用和增强预训练特征,而不是像传统微调方法那样调整模型权重。
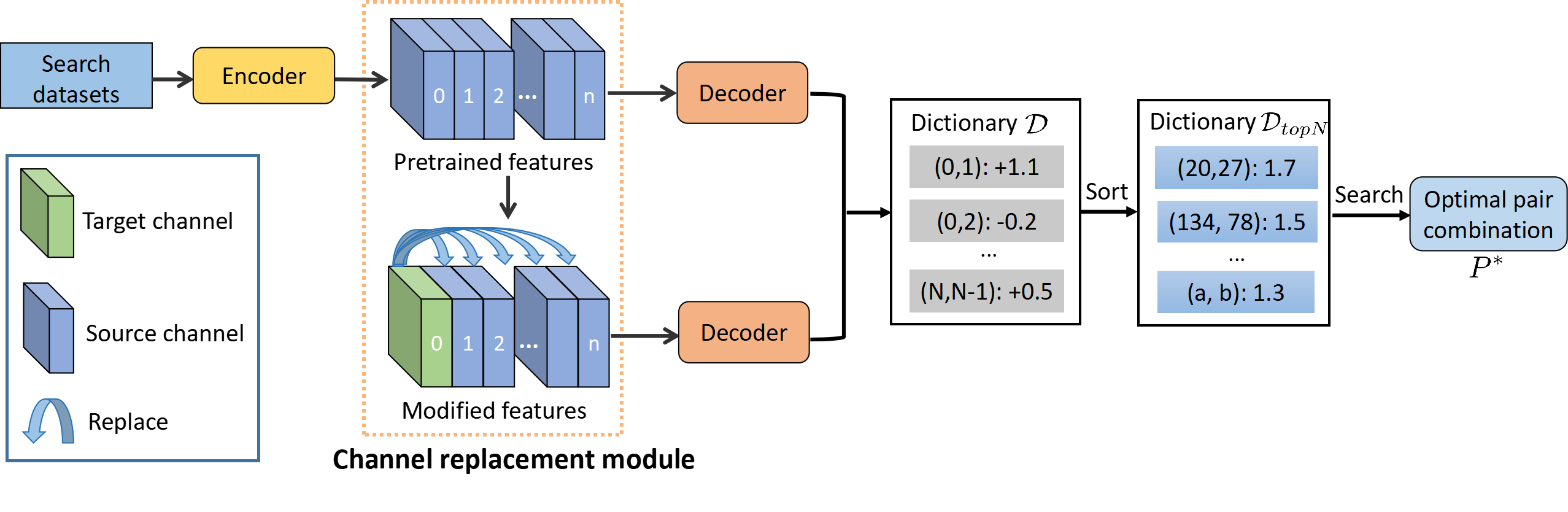
技术框架:该方法主要包含以下几个阶段:1) 特征提取:使用预训练的视觉基础模型提取输入图像的特征。2) 通道选择:基于模型输出差异,设计通道选择算法,识别冗余和有效的通道。具体来说,通过计算移除某个通道后模型输出的变化,来评估该通道的重要性。3) 通道替换:将识别出的冗余通道替换为更有效的通道。更有效的通道可能是从其他层或模型中选择的,也可能是通过某种方式增强的。4) 模型推理:使用修改后的特征进行下游任务的推理。
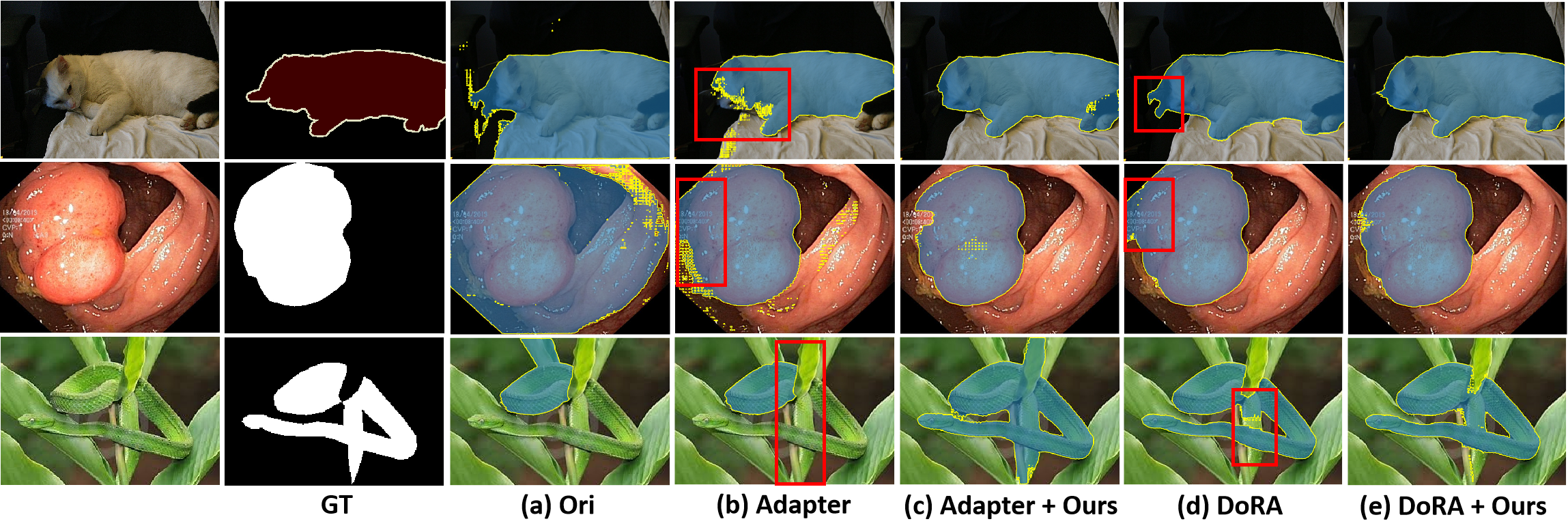
关键创新:该方法最重要的创新点在于提出了免参数微调的概念,通过选择和重用预训练特征,避免了传统微调方法中参数更新带来的问题。与现有方法相比,该方法不需要修改模型权重,因此计算成本更低,且不容易过拟合。此外,该方法还可以与现有的参数高效微调方法(如LoRA、Adapter)集成,进一步提升性能。
关键设计:通道选择算法是该方法中的关键设计。该算法基于模型输出差异来评估通道的重要性,具体实现方式未知,论文中可能使用了某种特定的度量方式来衡量输出差异。此外,如何选择更有效的通道来替换冗余通道也是一个关键设计,论文中可能使用了某种启发式方法或优化算法来解决这个问题。具体的参数设置、损失函数和网络结构等技术细节未知,需要参考论文原文。
🖼️ 关键图片
📊 实验亮点
该方法在领域外和领域内数据集上进行了实验,结果表明其在图像分割、深度估计和图像分类等任务上具有良好的性能。值得注意的是,该方法可以与现有的微调策略(例如,LoRA、Adapter)无缝集成,进一步提高已经微调的模型的性能。由于该方法仅涉及模型推理,因此显著降低了GPU内存开销。
🎯 应用场景
该研究成果可广泛应用于各种视觉任务,如图像分割、深度估计、图像分类等。尤其适用于计算资源受限的场景,例如移动设备或嵌入式系统。此外,该方法可以加速视觉基础模型在新的领域或任务上的部署,降低微调成本,并提高模型的泛化能力。未来,该方法有望成为视觉基础模型微调的一种标准方法。
📄 摘要(原文)
Vision foundation models (VFMs) have demonstrated remarkable capabilities in learning universal visual representations. However, adapting these models to downstream tasks conventionally requires parameter updates, with even parameter-efficient fine-tuning methods necessitating the modification of thousands to millions of weights. In this paper, we investigate the redundancies in the segment anything model (SAM) and then propose a novel parameter-free fine-tuning method. Unlike traditional fine-tuning methods that adjust parameters, our method emphasizes selecting, reusing, and enhancing pre-trained features, offering a new perspective on fine-tuning foundation models. Specifically, we introduce a channel selection algorithm based on the model's output difference to identify redundant and effective channels. By selectively replacing the redundant channels with more effective ones, we filter out less useful features and reuse more task-irrelevant features to downstream tasks, thereby enhancing the task-specific feature representation. Experiments on both out-of-domain and in-domain datasets demonstrate the efficiency and effectiveness of our method in different vision tasks (e.g., image segmentation, depth estimation and image classification). Notably, our approach can seamlessly integrate with existing fine-tuning strategies (e.g., LoRA, Adapter), further boosting the performance of already fine-tuned models. Moreover, since our channel selection involves only model inference, our method significantly reduces GPU memory overhead.