Cut-and-Splat: Leveraging Gaussian Splatting for Synthetic Data Generation
作者: Bram Vanherle, Brent Zoomers, Jeroen Put, Frank Van Reeth, Nick Michiels
分类: cs.CV
发布日期: 2025-04-11
备注: Accepted at the International Conference on Robotics, Computer Vision and Intelligent Systems 2025 (ROBOVIS)
💡 一句话要点
利用高斯溅射进行合成数据生成,提升实例分割模型训练效果
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 合成数据生成 高斯溅射 实例分割 深度估计 计算机视觉
📋 核心要点
- 现有合成数据生成方法难以兼顾3D模型精度和光照、相机伪影的真实性,限制了视觉模型训练效果。
- 利用高斯溅射技术,从目标物体视频中提取高质量3D模型,并将其逼真地渲染到随机背景中。
- 实验表明,该方法在合成数据生成方面优于Cut-and-Paste和扩散模型,提升了实例分割模型的性能。
📝 摘要(中文)
本文提出了一种利用高斯溅射(Gaussian Splatting)生成合成图像的pipeline,旨在为计算机视觉模型训练提供低成本、带标注的数据。该方法克服了传统方法在获取精确3D模型以及模拟真实光照和相机伪影方面的挑战。该pipeline仅需目标对象的视频,即可自动训练高斯溅射模型并提取对象。随后,利用高斯溅射将对象渲染到随机背景图像上,并通过单目深度估计将对象放置在合理的姿态中。论文引入了一个新的数据集来验证该方法,结果表明,该方法优于其他数据生成方法,如Cut-and-Paste和基于扩散模型的方法。
🔬 方法详解
问题定义:论文旨在解决计算机视觉模型训练中,高质量、带标注的合成数据获取成本高昂的问题。现有方法,如人工建模或使用传统渲染引擎,难以兼顾3D模型的精度和渲染的真实感,尤其是在光照效果和相机伪影的模拟方面,导致合成数据与真实数据存在较大差距,影响模型泛化能力。
核心思路:论文的核心思路是利用高斯溅射(Gaussian Splatting)技术,从目标物体的视频中学习得到高质量的3D模型,并利用其快速渲染能力,将目标物体逼真地渲染到随机背景中。通过这种方式,可以生成大量具有真实感和精确标注的合成数据,从而提升计算机视觉模型的训练效果。
技术框架:该合成数据生成pipeline主要包含以下几个阶段:1) 目标物体视频采集;2) 利用视频训练高斯溅射模型;3) 从高斯溅射模型中提取目标物体;4) 从图像数据集中随机选择背景图像;5) 利用高斯溅射将目标物体渲染到背景图像上;6) 使用单目深度估计调整目标物体在场景中的姿态和尺度;7) 生成实例分割标注。
关键创新:该方法最重要的创新点在于将高斯溅射技术应用于合成数据生成。与传统的基于Mesh或体素的3D模型相比,高斯溅射能够更高效地表示复杂场景,并实现高质量的渲染效果。此外,该方法还结合了单目深度估计,使得合成数据在场景布局方面更加合理。
关键设计:该pipeline的关键设计包括:1) 使用高质量的视频数据训练高斯溅射模型,以保证3D模型的精度;2) 采用随机背景图像,增加合成数据的多样性;3) 利用单目深度估计,将目标物体放置在合理的深度位置,并调整其尺度,使其与背景环境相协调;4) 自动生成实例分割标注,减少人工标注成本。具体的参数设置和损失函数细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

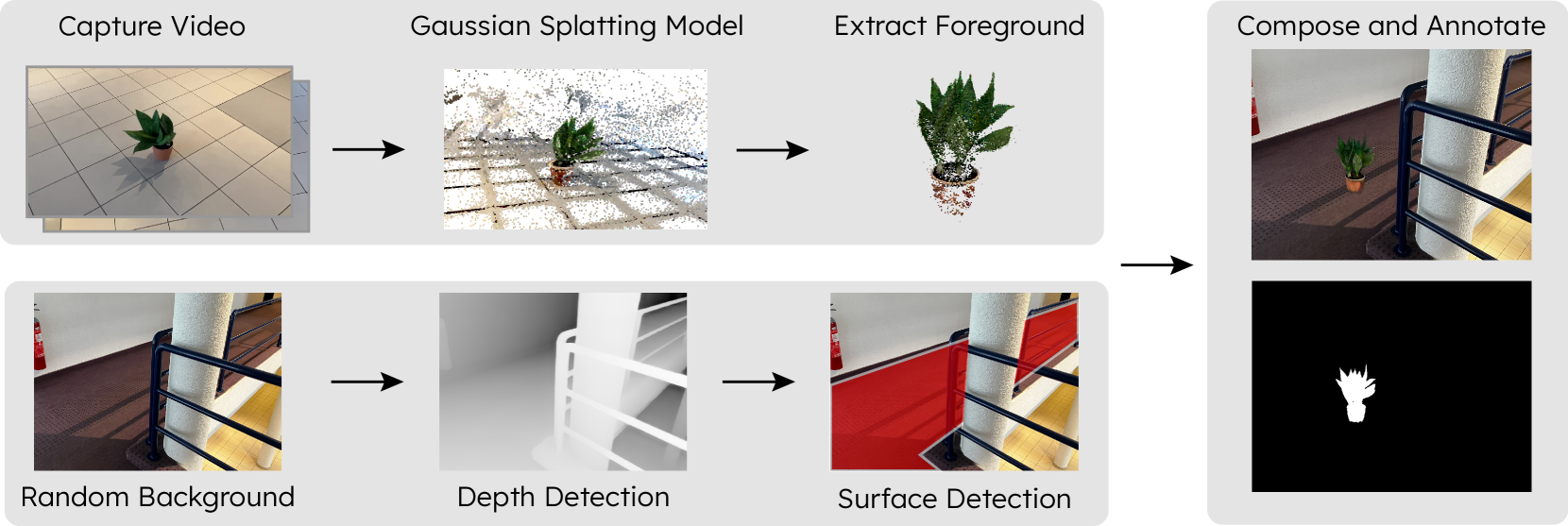
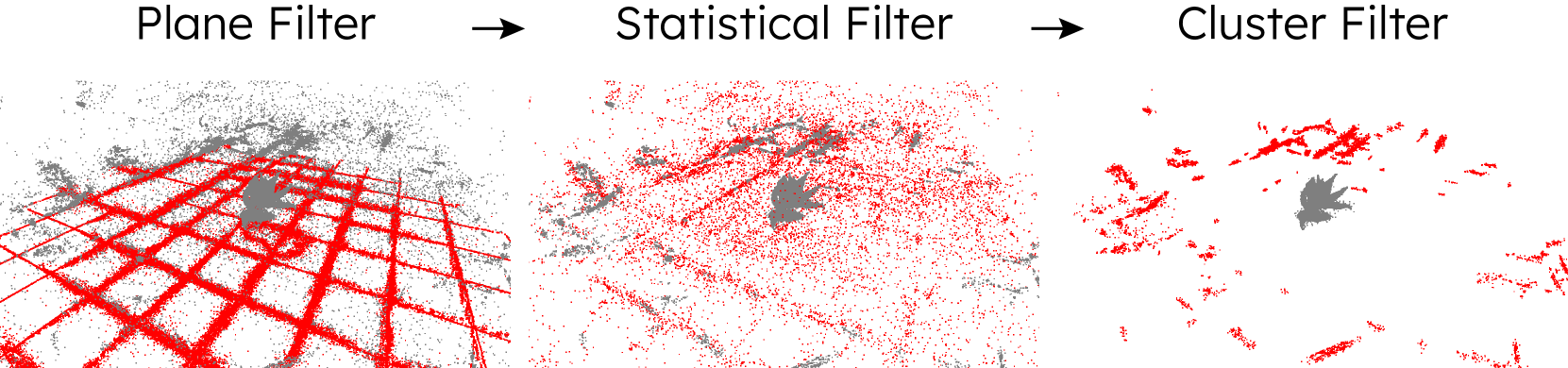
📊 实验亮点
论文通过实验验证了所提出的合成数据生成方法的有效性。实验结果表明,使用该方法生成的合成数据训练的实例分割模型,在性能上优于使用Cut-and-Paste和基于扩散模型方法生成的数据训练的模型。具体的性能提升数据在摘要中未给出,属于未知信息,但结论表明了该方法的优越性。
🎯 应用场景
该研究成果可广泛应用于计算机视觉模型的训练,尤其是在数据标注成本高昂或难以获取的场景下,例如自动驾驶、机器人导航、工业检测等领域。通过生成大量高质量的合成数据,可以有效提升模型的泛化能力和鲁棒性,降低对真实数据的依赖,加速相关技术的落地应用。
📄 摘要(原文)
Generating synthetic images is a useful method for cheaply obtaining labeled data for training computer vision models. However, obtaining accurate 3D models of relevant objects is necessary, and the resulting images often have a gap in realism due to challenges in simulating lighting effects and camera artifacts. We propose using the novel view synthesis method called Gaussian Splatting to address these challenges. We have developed a synthetic data pipeline for generating high-quality context-aware instance segmentation training data for specific objects. This process is fully automated, requiring only a video of the target object. We train a Gaussian Splatting model of the target object and automatically extract the object from the video. Leveraging Gaussian Splatting, we then render the object on a random background image, and monocular depth estimation is employed to place the object in a believable pose. We introduce a novel dataset to validate our approach and show superior performance over other data generation approaches, such as Cut-and-Paste and Diffusion model-based generation.