MineWorld: a Real-Time and Open-Source Interactive World Model on Minecraft
作者: Junliang Guo, Yang Ye, Tianyu He, Haoyu Wu, Yushu Jiang, Tim Pearce, Jiang Bian
分类: cs.CV, cs.AI
发布日期: 2025-04-11
备注: Technical report. Project page https://aka.ms/mineworld
💡 一句话要点
MineWorld:Minecraft上实时开源交互式世界模型,基于视觉-动作自回归Transformer
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 Minecraft 自回归Transformer 实时交互 并行解码
📋 核心要点
- 现有世界模型在复杂动态环境中与人类有效交互方面存在挑战,尤其是在动作跟随能力方面。
- MineWorld通过视觉-动作自回归Transformer,学习游戏状态表示和状态-动作条件关系,实现对Minecraft环境的建模。
- MineWorld通过并行解码算法实现实时交互,并在视觉质量和动作跟随能力上优于现有开源模型。
📝 摘要(中文)
本文提出了MineWorld,一个基于Minecraft的实时交互式世界模型。Minecraft是一个开放的沙盒游戏,常被用作世界建模的测试平台。MineWorld由一个视觉-动作自回归Transformer驱动,该Transformer以配对的游戏场景和相应的动作为输入,并生成跟随这些动作的后续新场景。具体来说,通过使用图像tokenizer和动作tokenizer将视觉游戏场景和动作转换为离散的token id,模型输入由这两种id交错连接组成。然后,模型通过下一个token预测进行训练,以同时学习游戏状态的丰富表示以及状态和动作之间的条件关系。在推理阶段,我们开发了一种新颖的并行解码算法,该算法同时预测每个帧中的空间冗余token,使不同规模的模型能够生成每秒4到7帧,从而实现与游戏玩家的实时交互。在评估方面,我们提出了新的指标,不仅评估视觉质量,还评估生成新场景时的动作跟随能力,这对于世界模型至关重要。全面的评估表明了MineWorld的有效性,显著优于最先进的开源的基于扩散的世界模型。代码和模型已发布。
🔬 方法详解
问题定义:现有世界模型难以在Minecraft这样复杂的开放世界游戏中实现实时交互,尤其是在生成新场景时,难以保证动作的准确跟随。现有方法,如基于扩散的模型,虽然视觉效果较好,但在动作控制和实时性方面存在不足。
核心思路:MineWorld的核心思路是利用视觉-动作自回归Transformer,将游戏场景和动作转化为离散的token序列,并通过预测下一个token的方式学习游戏世界的动态变化。通过交错连接视觉和动作token,模型能够同时学习游戏状态的表示以及状态和动作之间的关系,从而实现对动作的准确跟随。
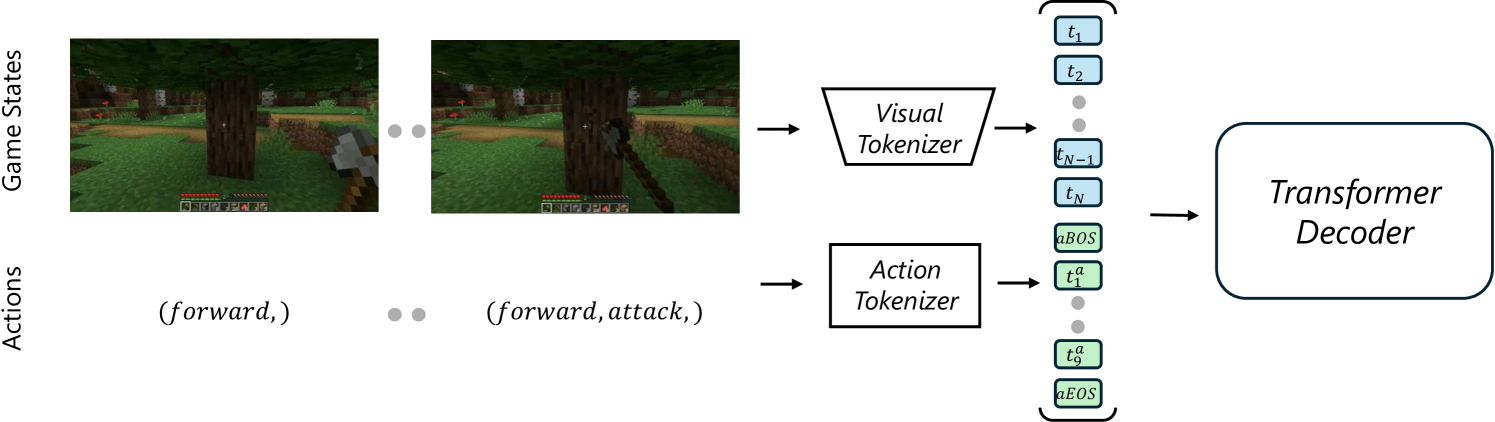
技术框架:MineWorld的整体框架包括三个主要模块:图像Tokenizer、动作Tokenizer和自回归Transformer。图像Tokenizer将游戏场景图像转换为离散的视觉token id,动作Tokenizer将游戏动作转换为离散的动作token id。自回归Transformer以交错连接的视觉和动作token id序列作为输入,通过预测下一个token的方式学习游戏世界的动态变化。在推理阶段,采用并行解码算法加速生成过程。
关键创新:MineWorld的关键创新在于其并行解码算法,该算法能够同时预测每个帧中的空间冗余token,从而显著提高生成速度,实现实时交互。此外,该模型还提出了新的评估指标,用于评估生成新场景时的动作跟随能力,弥补了现有评估指标的不足。
关键设计:图像Tokenizer和动作Tokenizer的具体实现细节未知,但其作用是将连续的视觉和动作信息转换为离散的token表示。自回归Transformer采用标准的Transformer架构,但其输入是交错连接的视觉和动作token id序列。损失函数采用标准的交叉熵损失,用于预测下一个token。并行解码算法的具体实现细节未知,但其目标是加速生成过程。
🖼️ 关键图片

📊 实验亮点
MineWorld在Minecraft环境中实现了实时交互,生成速度达到每秒4到7帧。实验结果表明,MineWorld在视觉质量和动作跟随能力方面均优于最先进的开源的基于扩散的世界模型。具体性能数据未知,但论文强调了MineWorld在动作跟随能力方面的显著提升。
🎯 应用场景
MineWorld可应用于游戏AI、机器人控制、虚拟现实等领域。通过学习游戏世界的动态变化,MineWorld可以帮助AI智能体更好地理解和预测环境,从而做出更合理的决策。此外,MineWorld还可以用于创建更逼真的虚拟现实环境,提升用户体验。未来,该技术有望应用于更复杂的现实世界场景,例如自动驾驶、智能制造等。
📄 摘要(原文)
World modeling is a crucial task for enabling intelligent agents to effectively interact with humans and operate in dynamic environments. In this work, we propose MineWorld, a real-time interactive world model on Minecraft, an open-ended sandbox game which has been utilized as a common testbed for world modeling. MineWorld is driven by a visual-action autoregressive Transformer, which takes paired game scenes and corresponding actions as input, and generates consequent new scenes following the actions. Specifically, by transforming visual game scenes and actions into discrete token ids with an image tokenizer and an action tokenizer correspondingly, we consist the model input with the concatenation of the two kinds of ids interleaved. The model is then trained with next token prediction to learn rich representations of game states as well as the conditions between states and actions simultaneously. In inference, we develop a novel parallel decoding algorithm that predicts the spatial redundant tokens in each frame at the same time, letting models in different scales generate $4$ to $7$ frames per second and enabling real-time interactions with game players. In evaluation, we propose new metrics to assess not only visual quality but also the action following capacity when generating new scenes, which is crucial for a world model. Our comprehensive evaluation shows the efficacy of MineWorld, outperforming SoTA open-sourced diffusion based world models significantly. The code and model have been released.