LMM4LMM: Benchmarking and Evaluating Large-multimodal Image Generation with LMMs
作者: Jiarui Wang, Huiyu Duan, Yu Zhao, Juntong Wang, Guangtao Zhai, Xiongkuo Min
分类: cs.CV
发布日期: 2025-04-11
🔗 代码/项目: GITHUB
💡 一句话要点
提出LMM4LMM,一种基于LMM的图像生成自动评估指标与基准数据集EvalMi-50K。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 文本到图像生成 图像质量评估 大型多模态模型 自动评估指标
📋 核心要点
- 现有T2I模型生成的图像在感知质量和文本图像对齐方面存在不足,且人工评估成本高昂。
- 提出LMM4LMM,利用大型多模态模型自动评估T2I生成质量,从感知、对齐和任务精度等多维度进行考量。
- 实验表明,LMM4LMM在EvalMi-50K上达到SOTA,并在其他数据集上展现出良好的泛化能力。
📝 摘要(中文)
大型多模态模型(LMMs)在文本到图像(T2I)生成和图像到文本(I2T)理解方面取得了显著进展。然而,许多生成的图像仍然存在感知质量和文本-图像对齐问题。鉴于手动评估的高成本和低效率,需要一种与人类偏好相符的自动指标。为此,我们提出了EvalMi-50K,这是一个用于评估大型多模态图像生成的综合数据集和基准,其特点是:(i)全面的任务,包含跨20个细粒度任务维度的2100个广泛提示,以及(ii)大规模的人类偏好注释,包括在24个T2I模型生成的50400张图像上标注的10万个平均意见得分(MOSs)和5万个问答(QA)对。基于EvalMi-50K,我们提出LMM4LMM,一种基于LMM的指标,用于从多个维度评估大型多模态T2I生成,包括感知、文本-图像对应和特定于任务的准确性。大量的实验结果表明,LMM4LMM在EvalMi-50K上实现了最先进的性能,并在其他AI生成的图像评估基准数据集上表现出强大的泛化能力,体现了EvalMi-50K数据集和LMM4LMM指标的通用性。EvalMi-50K和LMM4LMM都将在https://github.com/IntMeGroup/LMM4LMM上发布。
🔬 方法详解
问题定义:当前文本到图像(T2I)生成模型虽然取得了显著进展,但生成的图像在感知质量和文本图像对齐方面仍然存在问题。人工评估图像生成质量既昂贵又耗时,因此需要一种能够自动且准确地评估生成图像质量的指标。现有自动评估指标可能无法很好地捕捉人类的偏好,尤其是在多模态场景下。
核心思路:论文的核心思路是利用大型多模态模型(LMM)来模拟人类的评估过程。LMM具备强大的理解和推理能力,可以从多个维度(如感知质量、文本-图像一致性、任务特定准确性)评估生成的图像。通过训练LMM来预测人类对生成图像的偏好,可以得到一个更可靠和高效的自动评估指标。
技术框架:LMM4LMM的整体框架包括以下几个主要步骤:1) 使用多个T2I模型生成大量图像;2) 构建EvalMi-50K数据集,对生成的图像进行人工标注,包括平均意见得分(MOS)和问答(QA)对;3) 使用EvalMi-50K数据集训练LMM,使其能够预测人类对生成图像的偏好;4) 使用训练好的LMM4LMM评估新的T2I模型生成的图像。
关键创新:LMM4LMM的关键创新在于:1) 提出了EvalMi-50K数据集,这是一个大规模、多维度的T2I生成评估基准;2) 利用LMM来构建自动评估指标,能够更准确地捕捉人类的偏好;3) LMM4LMM可以从多个维度评估生成图像的质量,包括感知质量、文本-图像一致性和任务特定准确性。与现有方法相比,LMM4LMM更全面、更准确。
关键设计:EvalMi-50K数据集包含2100个提示,涵盖20个细粒度任务维度。每个图像都标注了MOS和QA对,用于训练LMM。LMM4LMM使用预训练的LMM作为骨干网络,并使用对比学习或回归损失函数进行微调,以预测人类对生成图像的偏好。具体的LMM选择和训练策略未知,需要在论文中进一步查找。
🖼️ 关键图片


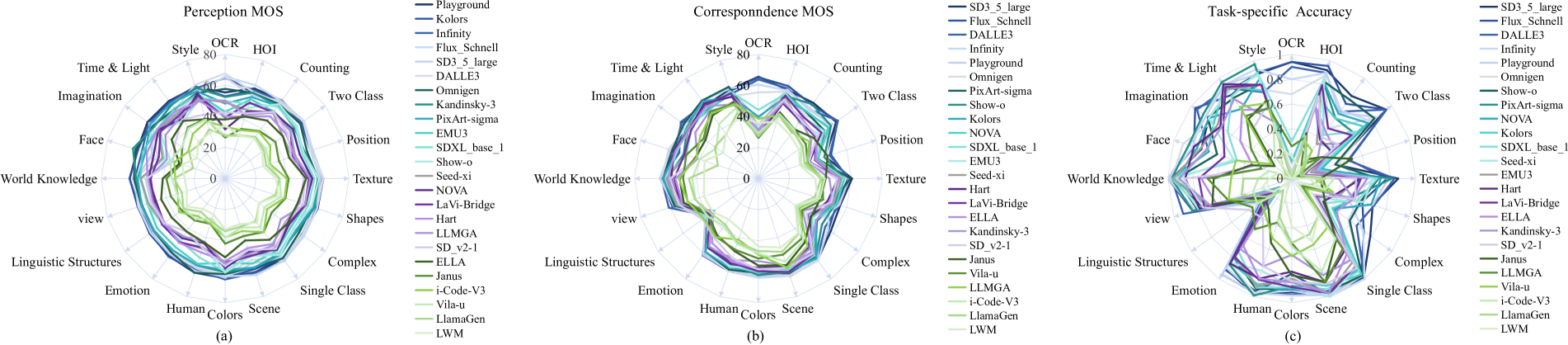
📊 实验亮点
LMM4LMM在EvalMi-50K数据集上取得了state-of-the-art的性能,表明其能够有效评估T2I生成模型的质量。此外,LMM4LMM在其他AI生成图像评估基准数据集上表现出强大的泛化能力,证明了其通用性。具体的性能提升幅度未知,需要在论文中进一步查找。
🎯 应用场景
LMM4LMM可用于自动评估文本到图像生成模型的性能,加速模型迭代和优化。该指标可应用于图像生成模型的训练、评估和选择,并可扩展到其他多模态生成任务,例如视频生成和3D模型生成。EvalMi-50K数据集可作为未来研究的基准,促进多模态生成领域的发展。
📄 摘要(原文)
Recent breakthroughs in large multimodal models (LMMs) have significantly advanced both text-to-image (T2I) generation and image-to-text (I2T) interpretation. However, many generated images still suffer from issues related to perceptual quality and text-image alignment. Given the high cost and inefficiency of manual evaluation, an automatic metric that aligns with human preferences is desirable. To this end, we present EvalMi-50K, a comprehensive dataset and benchmark for evaluating large-multimodal image generation, which features (i) comprehensive tasks, encompassing 2,100 extensive prompts across 20 fine-grained task dimensions, and (ii) large-scale human-preference annotations, including 100K mean-opinion scores (MOSs) and 50K question-answering (QA) pairs annotated on 50,400 images generated from 24 T2I models. Based on EvalMi-50K, we propose LMM4LMM, an LMM-based metric for evaluating large multimodal T2I generation from multiple dimensions including perception, text-image correspondence, and task-specific accuracy. Extensive experimental results show that LMM4LMM achieves state-of-the-art performance on EvalMi-50K, and exhibits strong generalization ability on other AI-generated image evaluation benchmark datasets, manifesting the generality of both the EvalMi-50K dataset and LMM4LMM metric. Both EvalMi-50K and LMM4LMM will be released at https://github.com/IntMeGroup/LMM4LMM.