DSM: Constructing a Diverse Semantic Map for 3D Visual Grounding
作者: Qinghongbing Xie, Zijian Liang, Fuhao Li, Long Zeng
分类: cs.CV, cs.RO
发布日期: 2025-04-11 (更新: 2025-10-14)
备注: 8 pages, 6 figures, Project Page: https://binicey.github.io/DSM
💡 一句话要点
提出多样化语义地图DSM,用于提升3D视觉定位性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 场景表示 视觉语言模型 语义地图 机器人导航
📋 核心要点
- 现有3D视觉定位方法受限于几何和视觉线索,缺乏复杂推理所需的多维语义属性。
- 提出多样化语义地图(DSM)框架,融合VLM语义信息,构建更全面的场景表示。
- DSM-Grounding在ScanRefer上超越现有方法10%,并在机器人导航和抓取任务中验证了实用性。
📝 摘要(中文)
本文提出了一种名为多样化语义地图(DSM)的新型场景表示框架,旨在丰富3D视觉定位的场景表示。现有方法通常只关注几何和视觉线索,或者像传统的3D场景图一样,缺乏复杂推理所需的多维属性。DSM通过融合时间滑动窗口内的多视角观测,在线构建持久且全面的世界模型,从而弥补了这一差距。DSM利用视觉语言模型(VLM)导出的语义信息,包括外观、物理属性和可供性,增强了鲁棒的几何模型。在此基础上,本文提出DSM-Grounding范式,将定位从自由形式的VLM查询转变为在语义丰富的地图上进行结构化推理,显著提高了准确性和可解释性。大量评估验证了该方法的优越性。在ScanRefer基准测试中,DSM-Grounding实现了59.06%的IoU@0.5总体准确率,超过其他方法10%。在语义分割方面,DSM达到了67.93%的F-mIoU,优于所有基线,包括特权基线。在物理机器人上的复杂导航和抓取任务的成功部署证实了该框架在现实场景中的实用性。
🔬 方法详解
问题定义:现有3D视觉定位方法要么只关注几何和视觉特征,要么像传统3D场景图一样,缺乏足够的多维语义属性,难以进行复杂的推理,限制了定位的准确性和可解释性。因此,如何构建一个包含丰富语义信息的场景表示是本文要解决的关键问题。
核心思路:本文的核心思路是利用视觉语言模型(VLM)提取的语义信息,例如外观、物理属性和可供性,来增强传统的几何模型。通过将这些语义信息融合到场景表示中,可以为3D视觉定位提供更丰富的上下文信息,从而提高定位的准确性和可解释性。
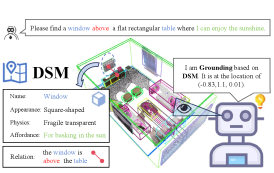
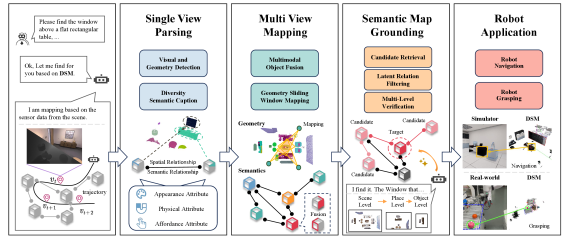
技术框架:DSM框架主要包含以下几个阶段:1) 多视角数据采集:通过多个视角获取场景的图像和深度信息。2) 几何模型构建:利用多视角数据构建场景的几何模型,例如点云或网格模型。3) VLM语义提取:利用视觉语言模型从图像中提取语义信息,例如物体的类别、属性和可供性。4) 语义融合:将VLM提取的语义信息融合到几何模型中,构建多样化语义地图(DSM)。5) DSM-Grounding:利用DSM进行结构化推理,实现3D视觉定位。
关键创新:本文最重要的技术创新点在于提出了多样化语义地图(DSM)这一新型场景表示框架。与传统的场景表示方法相比,DSM不仅包含了几何信息,还包含了丰富的语义信息,从而可以为3D视觉定位提供更全面的上下文信息。此外,DSM-Grounding范式将定位从自由形式的VLM查询转变为在语义丰富的地图上进行结构化推理,提高了定位的准确性和可解释性。
关键设计:DSM的构建依赖于时间滑动窗口内的多视角观测融合,以保证地图的持久性和完整性。VLM的选择和语义信息的提取方式是关键的设计因素。此外,DSM-Grounding的结构化推理过程也需要精心设计,以充分利用DSM中的语义信息。具体的参数设置、损失函数和网络结构等技术细节在论文中有详细描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DSM-Grounding在ScanRefer基准测试中取得了显著的性能提升,总体准确率(IoU@0.5)达到59.06%,超过现有方法10%。在语义分割任务中,DSM达到了67.93%的F-mIoU,优于所有基线方法,包括使用了特权信息的基线。此外,该框架还在实际机器人平台上成功部署,验证了其在复杂导航和抓取任务中的实用性。
🎯 应用场景
该研究成果可广泛应用于机器人导航、智能家居、增强现实、自动驾驶等领域。通过构建包含丰富语义信息的场景表示,可以提高机器人在复杂环境中的感知和理解能力,从而实现更智能、更可靠的交互和操作。例如,机器人可以利用DSM进行更精确的物体识别和抓取,或者在导航过程中更好地理解周围环境。
📄 摘要(原文)
Effective scene representation is critical for the visual grounding ability of representations, yet existing methods for 3D Visual Grounding are often constrained. They either only focus on geometric and visual cues, or, like traditional 3D scene graphs, lack the multi-dimensional attributes needed for complex reasoning. To bridge this gap, we introduce the Diverse Semantic Map (DSM) framework, a novel scene representation framework that enriches robust geometric models with a spectrum of VLM-derived semantics, including appearance, physical properties, and affordances. The DSM is first constructed online by fusing multi-view observations within a temporal sliding window, creating a persistent and comprehensive world model. Building on this foundation, we propose DSM-Grounding, a new paradigm that shifts grounding from free-form VLM queries to a structured reasoning process over the semantic-rich map, markedly improving accuracy and interpretability. Extensive evaluations validate our approach's superiority. On the ScanRefer benchmark, DSM-Grounding achieves a state-of-the-art 59.06% overall accuracy of IoU@0.5, surpassing others by 10%. In semantic segmentation, our DSM attains a 67.93% F-mIoU, outperforming all baselines, including privileged ones. Furthermore, successful deployment on physical robots for complex navigation and grasping tasks confirms the framework's practical utility in real-world scenarios.