F$^3$Set: Towards Analyzing Fast, Frequent, and Fine-grained Events from Videos
作者: Zhaoyu Liu, Kan Jiang, Murong Ma, Zhe Hou, Yun Lin, Jin Song Dong
分类: cs.CV, cs.AI
发布日期: 2025-04-11 (更新: 2025-04-15)
备注: ICLR 2025; Website URL: https://lzyandy.github.io/f3set-website/
🔗 代码/项目: GITHUB
💡 一句话要点
提出F$^3$Set基准数据集,用于分析视频中快速、频繁和细粒度的事件,并提出F$^3$ED模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 事件检测 细粒度分析 基准数据集 时序动作理解
📋 核心要点
- 现有方法难以准确识别视频中快速、频繁和细粒度的事件,主要受限于运动模糊和视觉差异。
- 论文核心在于构建了大规模、高精度的F$^3$Set基准数据集,并提出了新的F$^3$ED模型。
- 实验表明,现有方法在F$^3$Set上表现不佳,而提出的F$^3$ED模型取得了显著的性能提升。
📝 摘要(中文)
分析视频中快速、频繁和细粒度(F$^3$)的事件,对视频分析和多模态LLM提出了重大挑战。由于运动模糊和细微的视觉差异等挑战,当前的方法难以高精度地识别满足所有F$^3$标准的事件。为了推进视频理解的研究,我们引入了F$^3$Set,这是一个包含视频数据集的基准,用于精确的F$^3$事件检测。F$^3$Set中的数据集以其广泛的规模和全面的细节为特征,通常包含超过1000种事件类型,具有精确的时间戳和支持多层次的粒度。目前,F$^3$Set包含几个体育数据集,并且该框架也可以扩展到其他应用。我们在F$^3$Set上评估了流行的时序动作理解方法,揭示了现有技术的巨大挑战。此外,我们提出了一种新的方法F$^3$ED用于F$^3$事件检测,实现了卓越的性能。数据集、模型和基准代码可在https://github.com/F3Set/F3Set上找到。
🔬 方法详解
问题定义:论文旨在解决视频中快速(Fast)、频繁(Frequent)和细粒度(Fine-grained)事件的检测问题。现有方法在处理此类事件时面临挑战,例如运动模糊导致难以捕捉快速运动,事件频繁发生导致难以区分,以及细粒度事件的视觉差异小导致难以识别。这些问题限制了现有方法在复杂视频场景中的应用。
核心思路:论文的核心思路是构建一个高质量的基准数据集F$^3$Set,该数据集包含大量标注精确的F$^3$事件,从而为相关研究提供可靠的评估平台。同时,论文提出一种新的模型F$^3$ED,该模型专门针对F$^3$事件的特点进行设计,以提高检测精度。
技术框架:论文提出的F$^3$ED模型的整体架构未知,摘要中没有详细描述其具体流程和模块。但可以推测,该模型可能包含以下几个关键阶段:特征提取、事件定位和事件分类。特征提取阶段负责从视频帧中提取有用的视觉特征;事件定位阶段负责确定事件发生的时间范围;事件分类阶段负责识别事件的具体类型。
关键创新:论文的关键创新点在于两个方面:一是构建了F$^3$Set基准数据集,为F$^3$事件检测研究提供了新的资源;二是提出了F$^3$ED模型,该模型针对F$^3$事件的特点进行了优化,可能在特征提取、时序建模或分类策略上有所创新。与现有方法相比,F$^3$ED模型更专注于捕捉快速、频繁和细粒度的事件。
关键设计:由于论文摘要中没有提供关于F$^3$ED模型的具体技术细节,因此无法描述关键的参数设置、损失函数和网络结构等。这些细节可能在论文正文中有所阐述。
🖼️ 关键图片


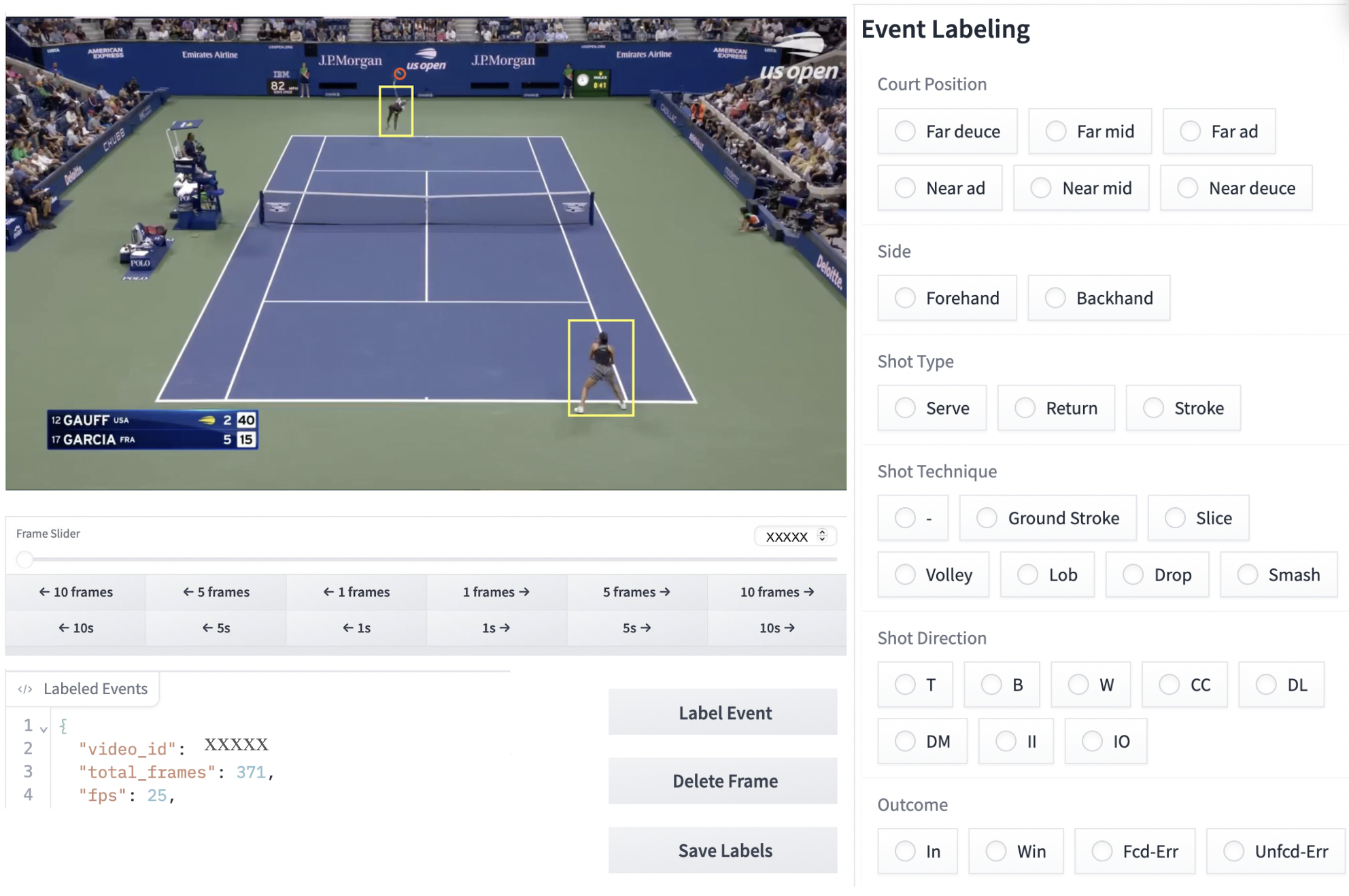
📊 实验亮点
论文通过在F$^3$Set数据集上评估现有方法,揭示了它们在处理F$^3$事件时的不足。同时,论文提出的F$^3$ED模型在F$^3$Set上取得了优于现有方法的性能,证明了其有效性。具体的性能数据和提升幅度未知,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于体育赛事分析、安防监控、自动驾驶等领域。例如,在体育赛事分析中,可以自动检测运动员的细微动作和战术变化;在安防监控中,可以快速识别异常行为和潜在威胁;在自动驾驶中,可以准确识别交通参与者的行为意图。该研究的未来影响在于推动视频理解技术的发展,使其能够更好地理解和分析复杂视频场景。
📄 摘要(原文)
Analyzing Fast, Frequent, and Fine-grained (F$^3$) events presents a significant challenge in video analytics and multi-modal LLMs. Current methods struggle to identify events that satisfy all the F$^3$ criteria with high accuracy due to challenges such as motion blur and subtle visual discrepancies. To advance research in video understanding, we introduce F$^3$Set, a benchmark that consists of video datasets for precise F$^3$ event detection. Datasets in F$^3$Set are characterized by their extensive scale and comprehensive detail, usually encompassing over 1,000 event types with precise timestamps and supporting multi-level granularity. Currently, F$^3$Set contains several sports datasets, and this framework may be extended to other applications as well. We evaluated popular temporal action understanding methods on F$^3$Set, revealing substantial challenges for existing techniques. Additionally, we propose a new method, F$^3$ED, for F$^3$ event detections, achieving superior performance. The dataset, model, and benchmark code are available at https://github.com/F3Set/F3Set.