Memory-efficient Streaming VideoLLMs for Real-time Procedural Video Understanding
作者: Dibyadip Chatterjee, Edoardo Remelli, Yale Song, Bugra Tekin, Abhay Mittal, Bharat Bhatnagar, Necati Cihan Camgöz, Shreyas Hampali, Eric Sauser, Shugao Ma, Angela Yao, Fadime Sener
分类: cs.CV
发布日期: 2025-04-10
备注: 13 pages, 5 figures; https://dibschat.github.io/ProVideLLM
💡 一句话要点
提出ProVideLLM,用于实时程序视频理解的内存高效流式VideoLLM框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流式视频理解 长视频理解 多模态融合 程序视频理解 实时推理
📋 核心要点
- 现有方法在处理长时程序视频理解时,面临着token数量爆炸和计算资源需求过高的挑战。
- ProVideLLM通过多模态缓存,交错存储文本摘要token和视觉token,实现内存和计算的亚线性缩放。
- ProVideLLM在多个程序任务上取得了SOTA结果,并实现了10 FPS的逐帧流式推理,内存占用仅2GB。
📝 摘要(中文)
我们提出了ProVideLLM,一个用于实时程序视频理解的端到端框架。ProVideLLM集成了一个多模态缓存,该缓存配置为存储两种类型的token:口头文本token,提供长期观察的压缩文本摘要;以及视觉token,使用DETR-QFormer编码,以捕获短期观察的细粒度细节。这种设计在表示一小时的长期观察时,token数量比现有方法减少了22倍,同时有效地编码了当前的细粒度。通过在我们的多模态缓存中交错这些token,ProVideLLM确保了内存和计算随视频长度的亚线性缩放,从而能够以10 FPS进行逐帧流式推理,并以25 FPS进行流式对话,且仅需2GB的最小GPU内存占用。ProVideLLM还在四个数据集的六个程序任务上设置了新的最先进的结果。
🔬 方法详解
问题定义:现有VideoLLM在处理长时程序视频理解任务时,面临着计算和内存瓶颈。直接处理原始视频帧序列会导致token数量随视频长度线性增长,使得实时推理和部署变得困难。现有方法难以在有限的计算资源下,同时兼顾长期上下文理解和细粒度细节捕捉。
核心思路:ProVideLLM的核心在于利用多模态缓存,将长期观察压缩成文本摘要token,并与短期观察的视觉token交错存储。文本token负责提供长期上下文信息,视觉token负责捕捉当前帧的细节。这种混合表示方法显著减少了token数量,降低了计算和内存需求。
技术框架:ProVideLLM包含视频编码器、多模态缓存和语言模型三个主要模块。视频编码器负责提取视频帧的特征。多模态缓存负责存储和管理文本token和视觉token。语言模型负责根据缓存中的token生成文本描述或执行其他任务。具体流程为:视频帧经过视频编码器提取特征,然后使用DETR-QFormer提取视觉token,并根据时间间隔生成文本摘要token,最后将两种token交错存储在多模态缓存中,供语言模型使用。
关键创新:ProVideLLM的关键创新在于多模态缓存的设计,它能够有效地压缩长期视频信息,并保留关键的视觉细节。通过交错存储文本和视觉token,ProVideLLM实现了内存和计算的亚线性缩放,从而能够进行实时流式推理。
关键设计:ProVideLLM使用DETR-QFormer提取视觉token,该模型能够有效地捕捉视频帧中的目标和关系。文本摘要token的生成方式未知,但推测是利用语言模型对一段时间内的视觉信息进行总结。多模态缓存的大小和token的更新策略是影响性能的关键参数。损失函数的设计也需要考虑如何平衡长期上下文理解和细粒度细节捕捉。
🖼️ 关键图片

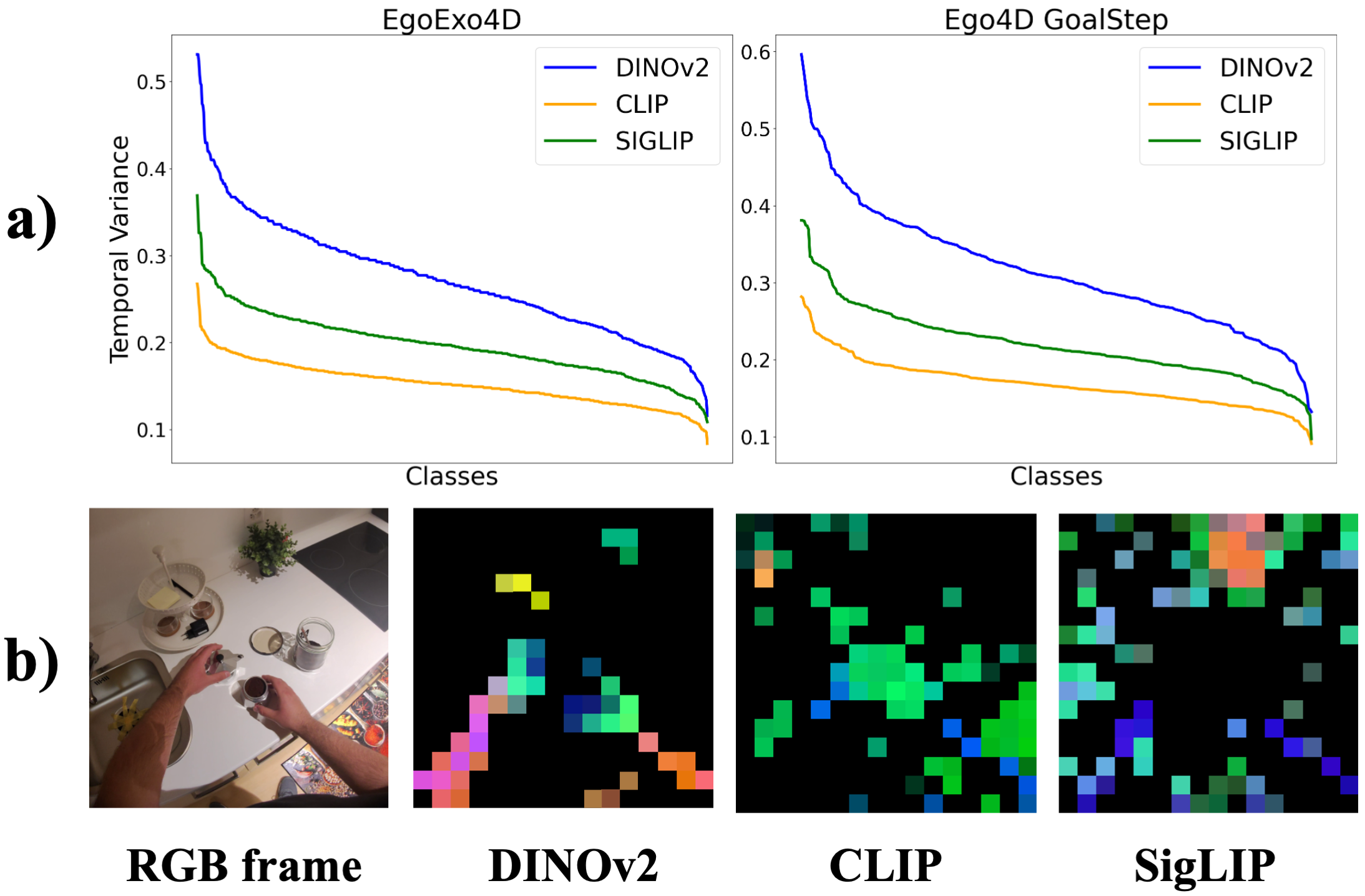

📊 实验亮点
ProVideLLM在四个数据集的六个程序任务上取得了新的SOTA结果。与现有方法相比,ProVideLLM在表示一小时的长期观察时,token数量减少了22倍。同时,ProVideLLM实现了10 FPS的逐帧流式推理,并仅需2GB的GPU内存占用。这些结果表明ProVideLLM在内存效率和推理速度方面具有显著优势。
🎯 应用场景
ProVideLLM可应用于各种需要实时程序视频理解的场景,例如智能助手、机器人导航、工业自动化、医疗诊断等。它可以帮助机器理解人类活动,并根据视频内容做出相应的决策和行动。该研究为开发低成本、高性能的实时视频理解系统提供了新的思路。
📄 摘要(原文)
We introduce ProVideLLM, an end-to-end framework for real-time procedural video understanding. ProVideLLM integrates a multimodal cache configured to store two types of tokens - verbalized text tokens, which provide compressed textual summaries of long-term observations, and visual tokens, encoded with DETR-QFormer to capture fine-grained details from short-term observations. This design reduces token count by 22x over existing methods in representing one hour of long-term observations while effectively encoding fine-granularity of the present. By interleaving these tokens in our multimodal cache, ProVideLLM ensures sub-linear scaling of memory and compute with video length, enabling per-frame streaming inference at 10 FPS and streaming dialogue at 25 FPS, with a minimal 2GB GPU memory footprint. ProVideLLM also sets new state-of-the-art results on six procedural tasks across four datasets.