POEM: Precise Object-level Editing via MLLM control
作者: Marco Schouten, Mehmet Onurcan Kaya, Serge Belongie, Dim P. Papadopoulos
分类: cs.CV
发布日期: 2025-04-10
备注: Accepted to SCIA 2025
💡 一句话要点
提出POEM,利用MLLM实现精确的对象级别图像编辑
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像编辑 多模态学习 大型语言模型 扩散模型 对象分割 文本到图像 细粒度控制
📋 核心要点
- 现有文本驱动图像编辑方法难以实现局部精确修改,常引入全局不希望的变化。
- POEM利用MLLM分析编辑指令,生成转换前后精确的对象掩码,实现细粒度控制。
- VOCEdits基准测试表明,POEM在精度和可靠性上优于现有方法,并减少人工干预。
📝 摘要(中文)
扩散模型显著提升了文本到图像的生成质量,能够从文本描述中生成高质量、逼真的图像。在生成之外,对象级别的图像编辑仍然是一个具有挑战性的问题,它需要在保持视觉连贯性的同时进行精确的修改。现有的基于文本指令的编辑方法在局部形状和布局转换方面表现不佳,常常引入不希望的全局变化。基于图像交互的方法虽然提供了更好的精度,但需要大量的人工干预来提供精确的指导。为了在保持高图像编辑精度的同时减少人工干预,本文提出了POEM,一个使用多模态大型语言模型(MLLM)进行精确对象级别编辑的框架。POEM利用MLLM分析指令提示,并在转换前后生成精确的对象掩码,从而实现细粒度的控制,而无需大量的用户输入。这种结构化的推理阶段指导了基于扩散的编辑过程,确保了精确的对象定位和转换。为了评估我们的方法,我们引入了VOCEdits,一个基于PASCAL VOC 2012的基准数据集,并增加了指令编辑提示、ground-truth转换和精确的对象掩码。实验结果表明,POEM在精度和可靠性方面优于现有的基于文本的图像编辑方法,同时与基于交互的方法相比,减少了人工干预。
🔬 方法详解
问题定义:论文旨在解决对象级别图像编辑中,现有方法精度不足且人工干预过多的问题。现有的文本指令编辑方法难以实现精确的局部形状和布局转换,容易引入全局性的不希望的改变。而基于图像交互的方法虽然精度较高,但需要大量的人工标注和指导,效率较低。
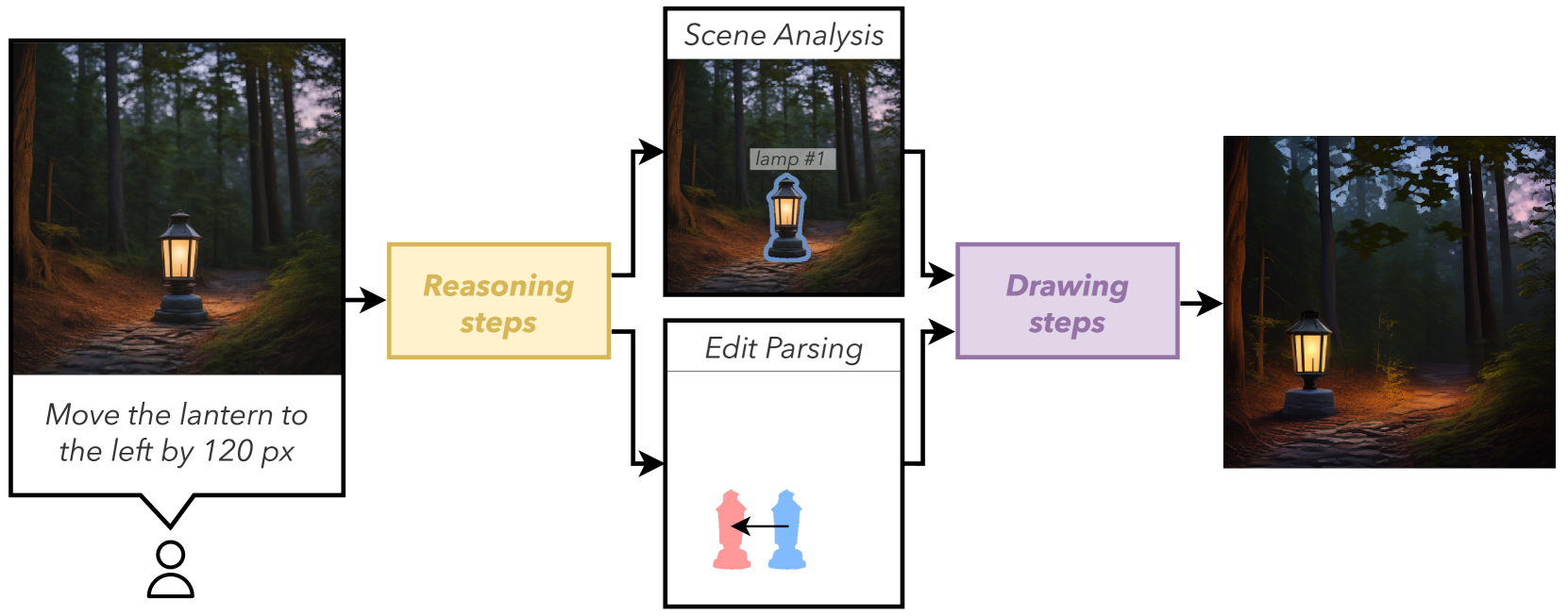
核心思路:论文的核心思路是利用多模态大型语言模型(MLLM)的强大推理能力,将文本编辑指令转化为精确的对象掩码,从而指导扩散模型的编辑过程。通过让MLLM理解指令并生成精确的掩码,可以避免现有方法中因理解偏差导致的错误编辑,并减少人工干预。
技术框架:POEM框架主要包含以下几个阶段:1) 指令分析:使用MLLM分析输入的文本编辑指令,理解需要修改的对象和修改方式。2) 掩码生成:MLLM根据指令生成修改前后的对象掩码,精确地定位需要编辑的对象区域。3) 扩散编辑:利用生成的掩码指导扩散模型进行图像编辑,实现精确的对象级别修改。框架整体上是一个端到端的流程,MLLM负责理解和规划,扩散模型负责执行。
关键创新:POEM的关键创新在于将MLLM引入到图像编辑流程中,利用其强大的语言理解和推理能力,生成精确的对象掩码,从而实现细粒度的控制。与现有方法相比,POEM不需要大量的人工标注,也不容易受到文本指令歧义的影响,能够更准确地实现用户意图。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,可以推断MLLM的选择和训练方式,以及掩码生成策略是关键的设计因素。此外,如何将MLLM生成的掩码有效地融入到扩散模型的编辑过程中,也是一个重要的技术挑战。
🖼️ 关键图片


📊 实验亮点
实验结果表明,POEM在VOCEdits数据集上显著优于现有的文本驱动图像编辑方法。具体来说,POEM在对象定位精度和编辑质量方面都取得了明显的提升,并且与基于交互的方法相比,大大减少了人工干预。这些结果验证了POEM框架的有效性和优越性。
🎯 应用场景
POEM具有广泛的应用前景,例如电商平台上的商品图像编辑、广告设计中的素材修改、以及艺术创作中的图像风格转换等。该技术可以帮助用户快速、精确地修改图像中的特定对象,提高工作效率,降低人工成本。未来,POEM还可以应用于虚拟现实、增强现实等领域,为用户提供更加个性化和沉浸式的体验。
📄 摘要(原文)
Diffusion models have significantly improved text-to-image generation, producing high-quality, realistic images from textual descriptions. Beyond generation, object-level image editing remains a challenging problem, requiring precise modifications while preserving visual coherence. Existing text-based instructional editing methods struggle with localized shape and layout transformations, often introducing unintended global changes. Image interaction-based approaches offer better accuracy but require manual human effort to provide precise guidance. To reduce this manual effort while maintaining a high image editing accuracy, in this paper, we propose POEM, a framework for Precise Object-level Editing using Multimodal Large Language Models (MLLMs). POEM leverages MLLMs to analyze instructional prompts and generate precise object masks before and after transformation, enabling fine-grained control without extensive user input. This structured reasoning stage guides the diffusion-based editing process, ensuring accurate object localization and transformation. To evaluate our approach, we introduce VOCEdits, a benchmark dataset based on PASCAL VOC 2012, augmented with instructional edit prompts, ground-truth transformations, and precise object masks. Experimental results show that POEM outperforms existing text-based image editing approaches in precision and reliability while reducing manual effort compared to interaction-based methods.