SRVP: Strong Recollection Video Prediction Model Using Attention-Based Spatiotemporal Correlation Fusion
作者: Yuseon Kim, Kyongseok Park
分类: cs.CV
发布日期: 2025-04-10 (更新: 2025-04-16)
备注: This paper has been accepted to CVPR 2025 Precognition Workshop
💡 一句话要点
提出基于注意力机制的时空相关性融合的强回忆视频预测模型,提升预测质量。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频预测 注意力机制 时空相关性 循环神经网络 特征融合
📋 核心要点
- 传统RNN视频预测模型在长时间预测中易丢失对象细节,导致图像质量下降。
- SRVP模型融合标准注意力和强化特征注意力,提取并增强时空表示,缓解细节丢失。
- 实验表明,SRVP在保持预测性能的同时,有效减轻了RNN模型中的图像质量退化问题。
📝 摘要(中文)
视频预测(VP)通过利用过去帧的空间表示和时间上下文来生成未来帧。传统的基于循环神经网络(RNN)的模型增强了记忆单元结构,以捕获长时间跨度的时空状态,但存在对象外观细节逐渐丢失的问题。为了解决这个问题,我们提出了强回忆VP(SRVP)模型,该模型集成了标准注意力(SA)和强化特征注意力(RFA)模块。这两个模块都采用缩放点积注意力来提取时间上下文和空间相关性,然后将它们融合以增强时空表示。在三个基准数据集上的实验表明,SRVP减轻了基于RNN的模型中的图像质量下降,同时实现了与无RNN架构相当的预测性能。
🔬 方法详解
问题定义:视频预测旨在根据过去的一系列视频帧预测未来的视频帧。现有基于RNN的视频预测模型,虽然能够捕捉时序信息,但随着预测步数的增加,容易出现图像模糊、细节丢失等问题,导致预测质量下降。这是由于RNN在长时序建模中存在信息衰减的固有缺陷。
核心思路:SRVP模型的核心思路是利用注意力机制来更有效地提取和融合视频帧中的时空相关性。通过注意力机制,模型可以聚焦于与预测未来帧最相关的过去帧信息,从而减少信息损失,保留更多的细节。同时,通过强化特征注意力,进一步提升关键特征的表达能力。
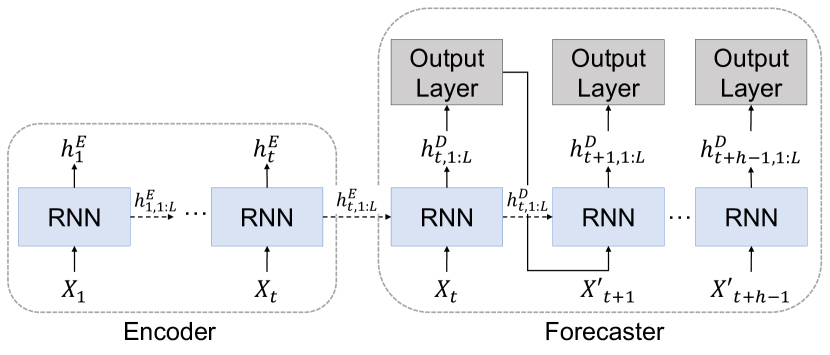
技术框架:SRVP模型主要包含以下几个关键模块:1) 特征提取模块:用于从输入的视频帧中提取空间特征表示。2) 标准注意力(SA)模块:利用缩放点积注意力机制,计算不同帧之间的相关性,提取时间上下文信息。3) 强化特征注意力(RFA)模块:在SA的基础上,进一步强化关键特征的表达,提升模型对重要信息的关注度。4) 时空融合模块:将SA和RFA模块提取的时空信息进行融合,得到增强的时空表示。5) 预测模块:根据增强的时空表示,生成未来的视频帧。
关键创新:SRVP模型的关键创新在于同时使用了标准注意力和强化特征注意力,并将它们融合以增强时空表示。RFA模块通过对特征进行强化,使得模型能够更加关注重要的特征信息,从而提升预测的准确性和细节保留能力。与传统的RNN模型相比,SRVP模型避免了RNN的循环结构,从而减轻了信息衰减的问题。
关键设计:SRVP模型中的注意力机制采用缩放点积注意力,其计算公式为:Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V,其中Q、K、V分别表示查询、键和值,d_k表示键的维度。RFA模块通过一个可学习的权重来强化特征。损失函数方面,可以使用L1损失或L2损失来衡量预测帧与真实帧之间的差异。具体的网络结构和参数设置需要根据不同的数据集进行调整。
🖼️ 关键图片


📊 实验亮点
SRVP模型在Moving MNIST、BAIR Robot Pushing和KTH Action三个基准数据集上进行了评估。实验结果表明,SRVP模型在减轻图像质量下降方面优于传统的RNN模型,并且在预测性能上与RNN-free架构相当。例如,在Moving MNIST数据集上,SRVP模型在保持较低的预测误差的同时,能够生成更加清晰的预测图像。
🎯 应用场景
SRVP模型可应用于多种视频分析和生成任务,例如视频监控、自动驾驶、视频编辑和游戏开发等。在视频监控中,可以预测潜在的异常行为;在自动驾驶中,可以预测车辆周围环境的变化;在视频编辑中,可以生成缺失的视频帧;在游戏开发中,可以生成逼真的游戏场景。该研究具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
Video prediction (VP) generates future frames by leveraging spatial representations and temporal context from past frames. Traditional recurrent neural network (RNN)-based models enhance memory cell structures to capture spatiotemporal states over extended durations but suffer from gradual loss of object appearance details. To address this issue, we propose the strong recollection VP (SRVP) model, which integrates standard attention (SA) and reinforced feature attention (RFA) modules. Both modules employ scaled dot-product attention to extract temporal context and spatial correlations, which are then fused to enhance spatiotemporal representations. Experiments on three benchmark datasets demonstrate that SRVP mitigates image quality degradation in RNN-based models while achieving predictive performance comparable to RNN-free architectures.