BoxDreamer: Dreaming Box Corners for Generalizable Object Pose Estimation
作者: Yuanhong Yu, Xingyi He, Chen Zhao, Junhao Yu, Jiaqi Yang, Ruizhen Hu, Yujun Shen, Xing Zhu, Xiaowei Zhou, Sida Peng
分类: cs.CV
发布日期: 2025-04-10 (更新: 2025-09-30)
备注: ICCV 2025 Camera Ready, Project page: https://zju3dv.github.io/boxdreamer
💡 一句话要点
BoxDreamer:通过预测物体边界框角点实现通用物体姿态估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 物体姿态估计 角点检测 稀疏视角 遮挡处理 PnP算法 RGB图像 点合成
📋 核心要点
- 现有物体姿态估计方法在遮挡和稀疏视角下泛化能力不足,限制了实际应用。
- 提出利用物体边界框角点作为中间表示,实现从稀疏视角可靠恢复3D角点,并合成目标视图2D角点。
- 实验表明,该方法在YCB-Video和Occluded-LINEMOD数据集上优于现有方法,提升了泛化能力。
📝 摘要(中文)
本文提出了一种通用的、基于RGB图像的物体姿态估计方法,专门用于解决稀疏视角下的挑战。现有方法虽然可以估计未见物体的姿态,但在遮挡和稀疏参考视图场景中的泛化能力仍然有限,限制了其在现实世界中的应用。为了克服这些限制,我们引入物体边界框的角点作为物体姿态的中间表示。3D物体角点可以从稀疏输入视图中可靠地恢复,而目标视图中的2D角点通过一种新颖的基于参考的点合成器进行估计,即使在涉及遮挡的场景中也能很好地工作。作为物体语义点,物体角点自然地建立了2D-3D对应关系,从而可以使用PnP算法进行物体姿态估计。在YCB-Video和Occluded-LINEMOD数据集上的大量实验表明,我们的方法优于最先进的方法,突出了所提出的表示的有效性,并显著提高了物体姿态估计的泛化能力,这对于实际应用至关重要。
🔬 方法详解
问题定义:现有基于RGB的物体姿态估计方法在稀疏视角和遮挡情况下泛化能力较差。它们通常依赖于密集的参考视图或对遮挡不鲁棒的特征,导致在实际应用中性能下降。因此,如何提高物体姿态估计在复杂环境下的泛化能力是一个关键问题。
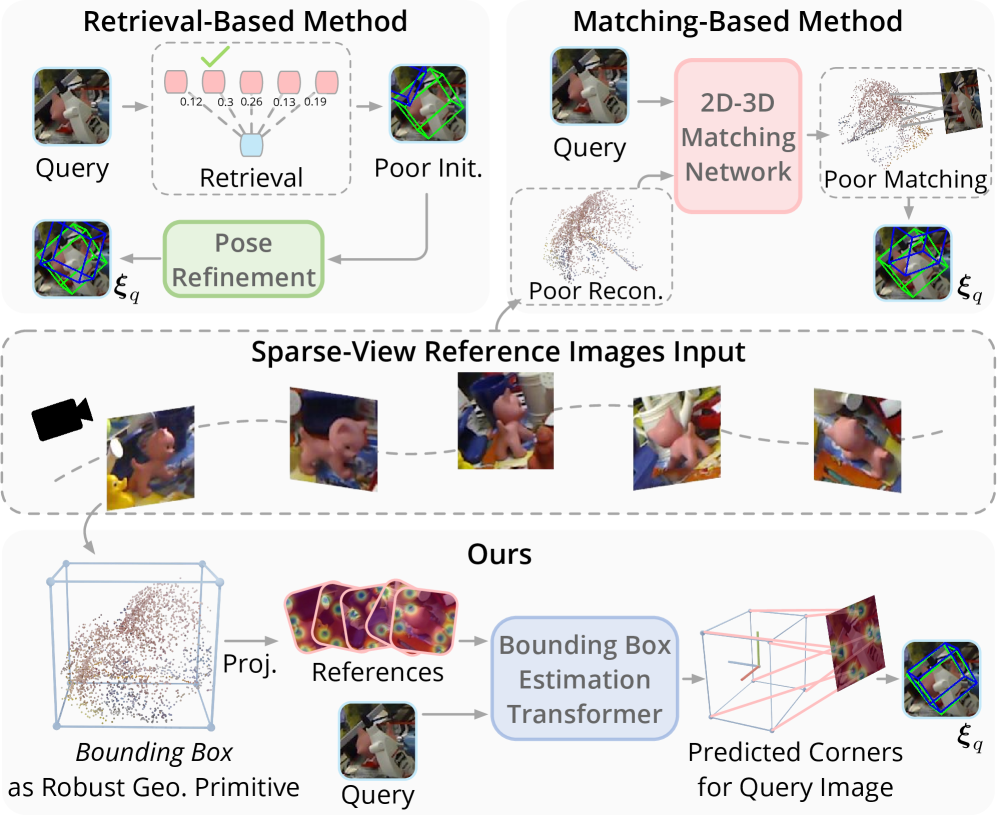
核心思路:本文的核心思路是将物体姿态估计问题转化为物体边界框角点的预测问题。通过预测3D空间中的角点坐标和目标视图中的2D角点位置,建立2D-3D对应关系,进而使用PnP算法求解物体姿态。这种方法的优势在于角点作为物体的语义特征,对遮挡具有一定的鲁棒性,并且可以从稀疏视图中进行推断。
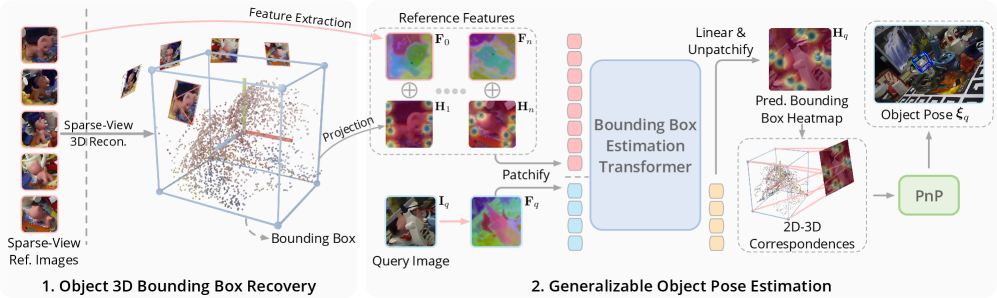
技术框架:该方法主要包含以下几个阶段:1) 从稀疏参考视图中恢复3D物体角点;2) 使用参考视图和目标视图,通过一个基于参考的点合成器估计目标视图中的2D角点;3) 利用恢复的3D角点和估计的2D角点,建立2D-3D对应关系;4) 使用PnP算法求解物体姿态。
关键创新:该方法最重要的创新点在于使用物体边界框角点作为物体姿态的中间表示。与直接预测物体姿态或其他中间表示(如密集像素对应)相比,角点具有更强的语义信息和更好的鲁棒性。此外,提出的基于参考的点合成器能够有效地处理遮挡情况,提高了2D角点估计的准确性。
关键设计:点合成器网络结构未知。损失函数未知。3D角点恢复方法未知。PnP算法使用标准实现。
🖼️ 关键图片

📊 实验亮点
该方法在YCB-Video和Occluded-LINEMOD数据集上进行了评估,实验结果表明,该方法在两个数据集上均优于现有方法。尤其是在Occluded-LINEMOD数据集上,该方法在遮挡情况下的性能提升显著,验证了所提出的角点表示和点合成器的有效性。具体性能数据未知。
🎯 应用场景
该研究成果可应用于机器人抓取、增强现实、自动驾驶等领域。在机器人抓取中,可以帮助机器人准确识别和定位物体,从而实现精确抓取。在增强现实中,可以实现虚拟物体与真实场景的精确对齐。在自动驾驶中,可以提高车辆对周围环境的感知能力,从而提高驾驶安全性。
📄 摘要(原文)
This paper presents a generalizable RGB-based approach for object pose estimation, specifically designed to address challenges in sparse-view settings. While existing methods can estimate the poses of unseen objects, their generalization ability remains limited in scenarios involving occlusions and sparse reference views, restricting their real-world applicability. To overcome these limitations, we introduce corner points of the object bounding box as an intermediate representation of the object pose. The 3D object corners can be reliably recovered from sparse input views, while the 2D corner points in the target view are estimated through a novel reference-based point synthesizer, which works well even in scenarios involving occlusions. As object semantic points, object corners naturally establish 2D-3D correspondences for object pose estimation with a PnP algorithm. Extensive experiments on the YCB-Video and Occluded-LINEMOD datasets show that our approach outperforms state-of-the-art methods, highlighting the effectiveness of the proposed representation and significantly enhancing the generalization capabilities of object pose estimation, which is crucial for real-world applications.