SAMJAM: Zero-Shot Video Scene Graph Generation for Egocentric Kitchen Videos
作者: Joshua Li, Fernando Jose Pena Cantu, Emily Yu, Alexander Wong, Yuchen Cui, Yuhao Chen
分类: cs.CV
发布日期: 2025-04-10
💡 一句话要点
SAMJAM:面向第一视角厨房视频的零样本视频场景图生成方法
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频场景图生成 零样本学习 视觉语言模型 时间一致性 第一视角视频
📋 核心要点
- 现有视频场景图生成模型依赖大量训练数据,难以适应新场景和新对象。
- SAMJAM利用SAM2进行时间跟踪,结合Gemini的语义理解,实现零样本视频场景图生成。
- 实验表明,SAMJAM在EPIC-KITCHENS数据集上显著优于Gemini,提升了场景图生成的准确性。
📝 摘要(中文)
视频场景图生成(VidSGG)是理解动态厨房环境的重要课题。现有的VidSGG模型需要大量的训练才能生成场景图。最近,视觉语言模型(VLM)和视觉基础模型(VFM)在各种任务中展示了令人印象深刻的零样本能力。然而,像Gemini这样的VLM在处理VidSGG的动态性时表现不佳,无法在帧之间保持稳定的对象身份。为了克服这个限制,我们提出了SAMJAM,一个零样本流水线,它结合了SAM2的时间跟踪和Gemini的语义理解。SAM2还通过生成更精确的边界框来改进Gemini的对象定位。在我们的方法中,我们首先提示Gemini生成帧级别的场景图。然后,我们采用一种匹配算法,将场景图中的每个对象与SAM2生成的或SAM2传播的掩码进行匹配,从而在动态环境中生成时间一致的场景图。最后,我们在后续的每一帧中重复这个过程。我们通过实验证明,SAMJAM在EPIC-KITCHENS和EPIC-KITCHENS-100数据集上的平均召回率比Gemini高8.33%。
🔬 方法详解
问题定义:论文旨在解决在第一视角厨房视频中,零样本生成时间一致的视频场景图的问题。现有方法,特别是直接使用视觉语言模型(如Gemini),在处理视频中的动态变化时,难以保持对象身份的一致性,导致生成的场景图不稳定且不准确。
核心思路:论文的核心思路是结合视觉语言模型的语义理解能力和分割模型的精确跟踪能力。具体来说,利用Gemini进行帧级别的场景图生成,然后利用SAM2进行对象分割和时间跟踪,将分割结果与Gemini生成的对象进行匹配,从而实现时间一致的场景图。
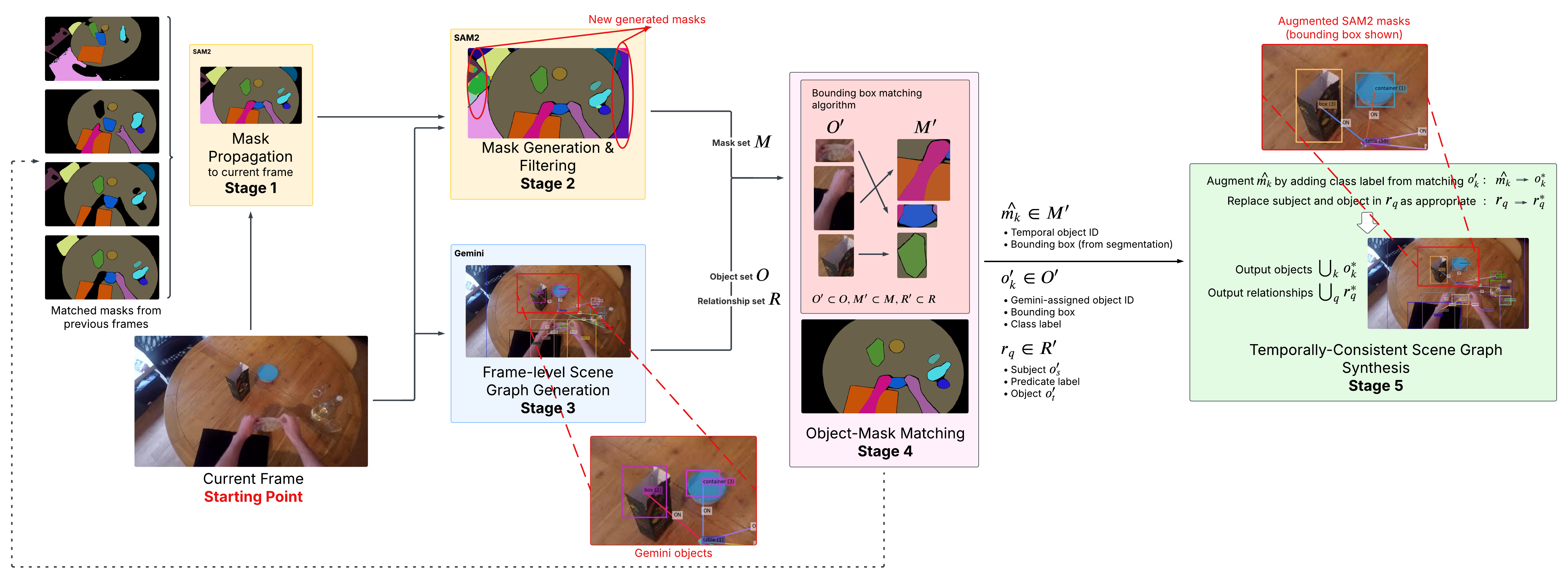
技术框架:SAMJAM的整体框架包含以下几个主要步骤:1) 使用Gemini生成帧级别的场景图;2) 使用SAM2生成或传播对象的掩码;3) 使用匹配算法将Gemini生成的对象与SAM2生成的掩码进行关联;4) 在后续帧中重复上述过程,以生成时间一致的视频场景图。
关键创新:SAMJAM的关键创新在于将视觉语言模型的语义理解能力与分割模型的时间跟踪能力相结合,从而在零样本条件下实现了时间一致的视频场景图生成。与直接使用视觉语言模型相比,SAMJAM能够更好地处理视频中的动态变化,保持对象身份的一致性。
关键设计:论文的关键设计包括:1) 使用SAM2进行对象分割和时间跟踪,确保对象身份的一致性;2) 设计匹配算法,将Gemini生成的对象与SAM2生成的掩码进行关联;3) 在后续帧中重复上述过程,以生成时间一致的视频场景图。具体的匹配算法细节和参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SAMJAM在EPIC-KITCHENS和EPIC-KITCHENS-100数据集上显著优于直接使用Gemini进行零样本视频场景图生成。具体来说,SAMJAM在平均召回率(mean recall)指标上比Gemini提高了8.33%。这一结果验证了SAMJAM方法的有效性,表明结合视觉语言模型和分割模型可以显著提高零样本视频场景图生成的性能。
🎯 应用场景
该研究成果可应用于智能厨房、机器人辅助烹饪、视频监控等领域。通过自动生成厨房场景图,可以帮助机器人理解厨房环境,执行复杂的烹饪任务。此外,该技术还可以用于视频内容分析和检索,例如,根据场景图搜索包含特定对象和动作的视频片段。未来,该技术有望扩展到其他动态场景,例如自动驾驶和智能家居。
📄 摘要(原文)
Video Scene Graph Generation (VidSGG) is an important topic in understanding dynamic kitchen environments. Current models for VidSGG require extensive training to produce scene graphs. Recently, Vision Language Models (VLM) and Vision Foundation Models (VFM) have demonstrated impressive zero-shot capabilities in a variety of tasks. However, VLMs like Gemini struggle with the dynamics for VidSGG, failing to maintain stable object identities across frames. To overcome this limitation, we propose SAMJAM, a zero-shot pipeline that combines SAM2's temporal tracking with Gemini's semantic understanding. SAM2 also improves upon Gemini's object grounding by producing more accurate bounding boxes. In our method, we first prompt Gemini to generate a frame-level scene graph. Then, we employ a matching algorithm to map each object in the scene graph with a SAM2-generated or SAM2-propagated mask, producing a temporally-consistent scene graph in dynamic environments. Finally, we repeat this process again in each of the following frames. We empirically demonstrate that SAMJAM outperforms Gemini by 8.33% in mean recall on the EPIC-KITCHENS and EPIC-KITCHENS-100 datasets.