FakeIDet: Exploring Patches for Privacy-Preserving Fake ID Detection
作者: Javier Muñoz-Haro, Ruben Tolosana, Ruben Vera-Rodriguez, Aythami Morales, Julian Fierrez
分类: cs.CV, cs.AI, cs.CR
发布日期: 2025-04-10 (更新: 2025-08-01)
期刊: IEEE International Joint Conference on Biometrics (IJCB 2025)
💡 一句话要点
提出FakeIDet以解决假身份证检测中的隐私保护问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 假身份证检测 隐私保护 补丁方法 机器学习 视觉变换器 数据稀缺 公开数据库
📋 核心要点
- 核心问题:假身份证检测面临真实数据稀缺的挑战,现有研究依赖于不可公开的内部数据库,限制了技术进步。
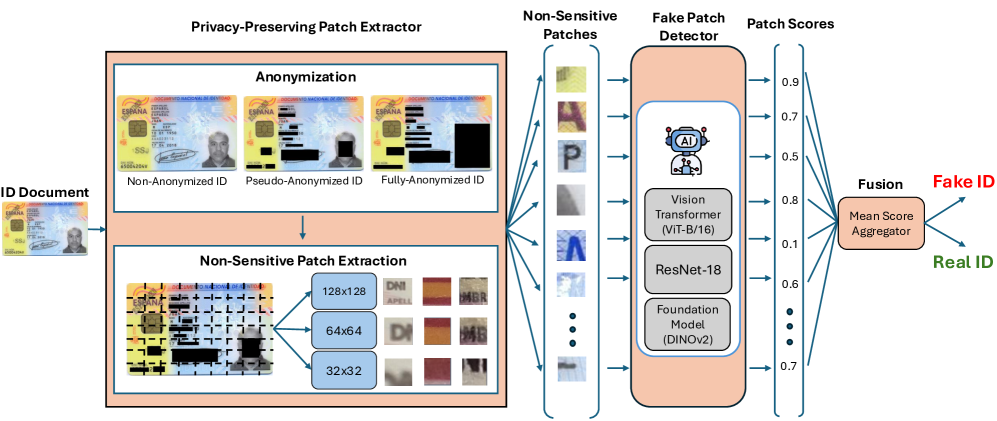
- 方法要点:提出FakeIDet方法,通过补丁级别的隐私保护,探索不同的匿名化级别和补丁大小配置。
- 实验或效果:在DLC-2021数据库上,FakeIDet在补丁和整个ID级别分别实现了13.91%和0%的EER,显示出良好的泛化能力。
📝 摘要(中文)
验证身份文件(ID)的真实性已成为数字银行、加密交易、租赁等实际应用中的一项关键挑战。本研究聚焦于假身份证检测,解决了该领域的多个局限性,尤其是缺乏真实ID数据的问题。为此,本文提出了一种新的基于补丁的方法,旨在平衡隐私与性能,并提出了一种新颖的隐私感知假身份证检测方法FakeIDet。实验中,我们探索了ID的两种匿名化级别(完全匿名和伪匿名)以及不同的补丁大小配置。结果表明,在未见过的数据库DLC-2021上,FakeIDet在补丁和整个ID级别分别达到了13.91%和0%的EER,显示出良好的泛化能力。此外,本文还发布了首个包含48,400个真实和假ID补丁的公开数据库FakeIDet-db及实验框架。
🔬 方法详解
问题定义:本研究旨在解决假身份证检测中的隐私保护问题,现有方法普遍依赖于不可公开的内部数据库,导致真实数据稀缺,限制了研究的深入和技术的发展。
核心思路:论文提出了一种新颖的补丁级别方法FakeIDet,通过对ID进行不同级别的匿名化处理,平衡隐私保护与检测性能,旨在提高假身份证检测的准确性和实用性。
技术框架:整体架构包括数据预处理、补丁生成、模型训练和评估四个主要模块。首先,对ID进行匿名化处理,然后生成不同大小的补丁,最后使用视觉变换器和基础模型进行训练和评估。
关键创新:最重要的技术创新在于提出了补丁级别的隐私保护方法FakeIDet,并发布了包含真实和假ID补丁的公开数据库FakeIDet-db,填补了该领域数据稀缺的空白。
关键设计:在实验中,采用了两种匿名化级别(完全匿名和伪匿名),并探索了不同的补丁大小配置,以优化敏感数据的可见性和检测性能。
🖼️ 关键图片


📊 实验亮点
实验结果显示,FakeIDet在未见过的DLC-2021数据库上,补丁级别和整个ID级别的EER分别为13.91%和0%,表现出良好的泛化能力,显著优于现有方法,展示了其在假身份证检测中的有效性。
🎯 应用场景
该研究的潜在应用领域包括数字身份验证、金融服务、在线租赁和其他需要身份验证的场景。通过提供一种有效的假身份证检测方法,FakeIDet能够帮助相关行业提高安全性,减少欺诈行为,促进技术的进一步发展与应用。
📄 摘要(原文)
Verifying the authenticity of identity documents (IDs) has become a critical challenge for real-life applications such as digital banking, crypto-exchanges, renting, etc. This study focuses on the topic of fake ID detection, covering several limitations in the field. In particular, there are no publicly available data from real IDs for proper research in this area, and most published studies rely on proprietary internal databases that are not available for privacy reasons. In order to advance this critical challenge of real data scarcity that makes it so difficult to advance the technology of machine learning-based fake ID detection, we introduce a new patch-based methodology that trades off privacy and performance, and propose a novel patch-wise approach for privacy-aware fake ID detection: FakeIDet. In our experiments, we explore: i) two levels of anonymization for an ID (i.e., fully- and pseudo-anonymized), and ii) different patch size configurations, varying the amount of sensitive data visible in the patch image. State-of-the-art methods, such as vision transformers and foundation models, are considered as backbones. Our results show that, on an unseen database (DLC-2021), our proposal for fake ID detection achieves 13.91% and 0% EERs at the patch and the whole ID level, showing a good generalization to other databases. In addition to the path-based methodology introduced and the new FakeIDet method based on it, another key contribution of our article is the release of the first publicly available database that contains 48,400 patches from real and fake IDs, called FakeIDet-db, together with the experimental framework.