VideoExpert: Augmented LLM for Temporal-Sensitive Video Understanding
作者: Henghao Zhao, Ge-Peng Ji, Rui Yan, Huan Xiong, Zechao Li
分类: cs.CV
发布日期: 2025-04-10
💡 一句话要点
VideoExpert:增强LLM用于时序敏感的视频理解,解决时间戳生成偏差问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态学习 大型语言模型 时间序列建模 时间定位 事件检测 时序敏感任务
📋 核心要点
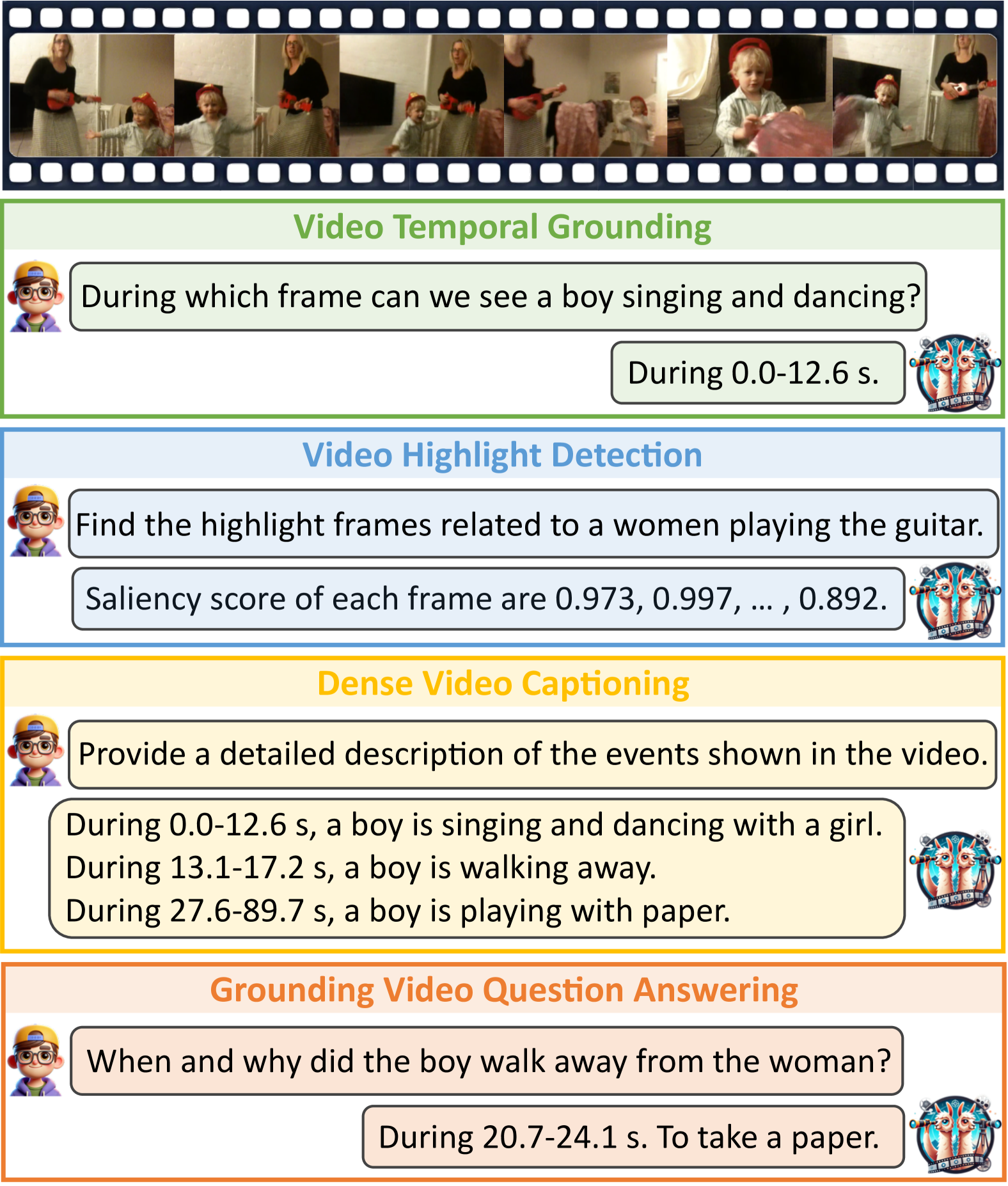
- 现有MLLM在时序视频理解中生成时间戳时,易受语言模式偏差影响,忽略视觉信息,导致性能下降。
- VideoExpert通过分离时间专家和空间专家,分别处理时序建模和内容生成,避免了时间戳预测中的文本模式偏差。
- 实验结果表明,VideoExpert在多个时序敏感的视频任务中表现出色,验证了其有效性和通用性。
📝 摘要(中文)
视频理解的核心挑战在于感知视频内容随时间变化的动态信息。然而,多模态大型语言模型(MLLM)在时序敏感的视频任务中表现不佳,这类任务需要生成时间戳来标记特定事件的发生。现有的方法通常要求MLLM直接生成绝对或相对时间戳。我们观察到,这些MLLM在生成时间戳时更倾向于依赖语言模式而非视觉线索,从而影响性能。为了解决这个问题,我们提出了VideoExpert,一种通用的MLLM,适用于多种时序敏感的视频任务。受到专家概念的启发,VideoExpert集成了两个并行的模块:时间专家(Temporal Expert)和空间专家(Spatial Expert)。时间专家负责建模时间序列并执行时间定位。它处理高帧率但压缩的tokens,以捕获视频中的动态变化,并包含一个轻量级的预测头,用于精确定位事件。空间专家专注于内容细节分析和指令跟随。它处理专门设计的空间tokens和语言输入,旨在生成与内容相关的响应。这两个专家通过一个特殊的token无缝协作,确保协调的时间定位和内容生成。值得注意的是,时间和空间专家保持独立的参数集。通过将时间定位从内容生成中分离出来,VideoExpert可以防止时间戳预测中的文本模式偏差。此外,我们引入了一个空间压缩模块(Spatial Compress module)来获得空间tokens。该模块过滤和压缩patch tokens,同时保留关键信息,为空间专家提供紧凑但细节丰富的输入。大量的实验证明了VideoExpert的有效性和通用性。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在时序敏感的视频理解任务中,由于时间戳生成过程中过度依赖语言模式而忽略视觉信息,导致性能下降的问题。现有方法直接让MLLM生成时间戳,容易受到文本模式的干扰,无法准确捕捉视频中的动态变化。
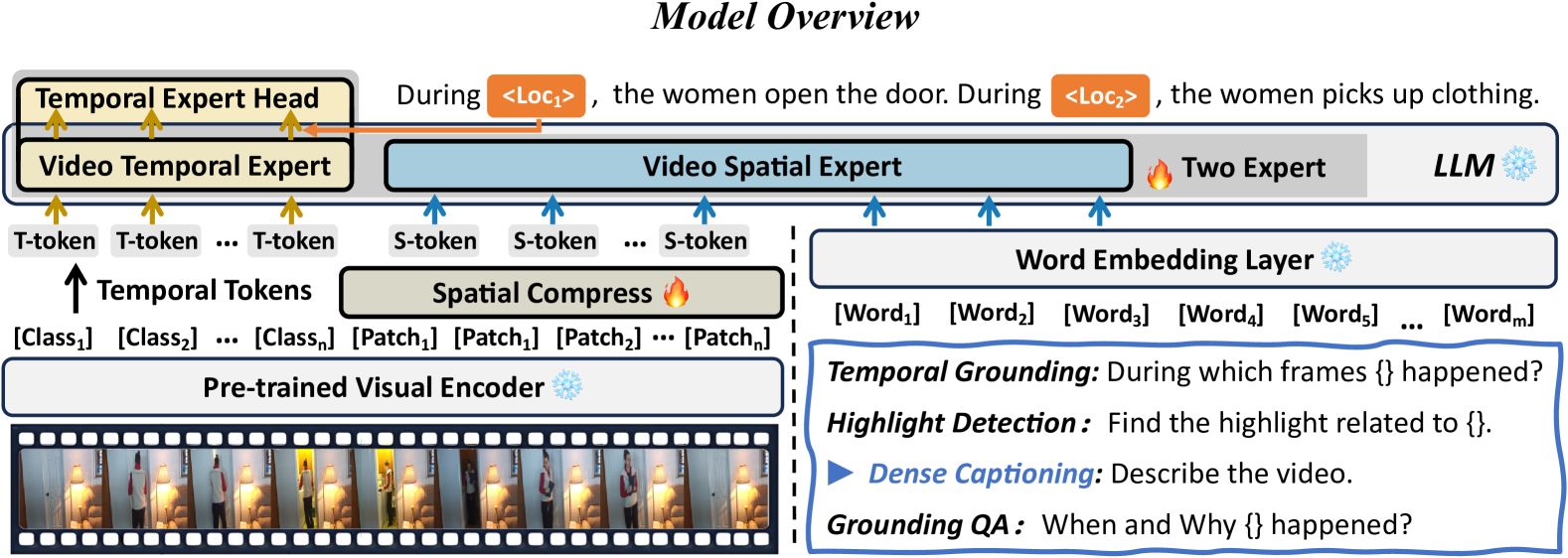
核心思路:论文的核心思路是将时间建模和内容生成解耦,分别由时间专家(Temporal Expert)和空间专家(Spatial Expert)处理。时间专家专注于时间序列建模和时间定位,空间专家专注于内容细节分析和指令跟随。通过这种解耦,可以避免时间戳预测中的文本模式偏差,提高时间定位的准确性。
技术框架:VideoExpert的整体架构包含三个主要模块:时间专家(Temporal Expert)、空间专家(Spatial Expert)和空间压缩模块(Spatial Compress module)。时间专家处理高帧率压缩的视频tokens,进行时间序列建模和事件定位。空间专家处理空间tokens和语言输入,生成与内容相关的响应。空间压缩模块用于过滤和压缩patch tokens,为空间专家提供紧凑但细节丰富的输入。时间专家和空间专家通过一个特殊的token进行协作,实现协调的时间定位和内容生成。
关键创新:VideoExpert的关键创新在于时间专家和空间专家的解耦设计。这种设计使得时间专家可以专注于时间序列建模,避免受到内容生成任务的干扰,从而提高时间定位的准确性。此外,空间压缩模块的设计也保证了空间专家能够获得关键的视觉信息,从而更好地理解视频内容。
关键设计:时间专家使用高帧率但压缩的tokens作为输入,以捕获视频中的动态变化。空间压缩模块采用过滤和压缩策略,保留关键信息,减少计算量。时间专家和空间专家之间通过特殊的token进行信息交互,实现协同工作。时间和空间专家拥有独立的参数集,允许它们独立学习和优化。
🖼️ 关键图片

📊 实验亮点
论文通过大量实验验证了VideoExpert的有效性和通用性。实验结果表明,VideoExpert在多个时序敏感的视频任务中取得了显著的性能提升。例如,在时间定位任务中,VideoExpert的准确率超过了现有方法,证明了其在时间建模方面的优势。此外,VideoExpert在内容生成任务中也表现出色,证明了其在理解视频内容方面的能力。
🎯 应用场景
VideoExpert具有广泛的应用前景,例如视频监控、自动驾驶、视频编辑、智能安防、体育赛事分析等领域。它可以用于精确定位视频中的事件发生时间,从而实现更智能的视频分析和理解。该研究的成果有助于推动多模态大型语言模型在视频理解领域的应用,并为未来的研究提供新的思路。
📄 摘要(原文)
The core challenge in video understanding lies in perceiving dynamic content changes over time. However, multimodal large language models struggle with temporal-sensitive video tasks, which requires generating timestamps to mark the occurrence of specific events. Existing strategies require MLLMs to generate absolute or relative timestamps directly. We have observed that those MLLMs tend to rely more on language patterns than visual cues when generating timestamps, affecting their performance. To address this problem, we propose VideoExpert, a general-purpose MLLM suitable for several temporal-sensitive video tasks. Inspired by the expert concept, VideoExpert integrates two parallel modules: the Temporal Expert and the Spatial Expert. The Temporal Expert is responsible for modeling time sequences and performing temporal grounding. It processes high-frame-rate yet compressed tokens to capture dynamic variations in videos and includes a lightweight prediction head for precise event localization. The Spatial Expert focuses on content detail analysis and instruction following. It handles specially designed spatial tokens and language input, aiming to generate content-related responses. These two experts collaborate seamlessly via a special token, ensuring coordinated temporal grounding and content generation. Notably, the Temporal and Spatial Experts maintain independent parameter sets. By offloading temporal grounding from content generation, VideoExpert prevents text pattern biases in timestamp predictions. Moreover, we introduce a Spatial Compress module to obtain spatial tokens. This module filters and compresses patch tokens while preserving key information, delivering compact yet detail-rich input for the Spatial Expert. Extensive experiments demonstrate the effectiveness and versatility of the VideoExpert.